优化Feed流遭遇拦路虎 是谁帮百度打破了“内存墙”?-feed优化师证书
Feed流的概念对很多人来说都很陌生,但在移动互联网时代几乎每个人的工作生活都离不开它。通俗讲,它就是一种普遍应用于各类社交和内容资讯类app,主攻信息、内容的聚合和推送的互联网服务方式。它能将你最感兴趣并且长期关注的内容推送给你,成为“最懂你”的信息助手。同时,基于智能化的自动聚合、精准推送信息的功能,它也成为了今天商户投放广告和实现更佳营销效果的重要渠道。
依托于出色的个性化应用体验,Feed流服务的用户数量和使用频度都在与日俱增,用户对其内容推送的精准度、时效性等需求也在随之不断提升,这就对支撑Feed流服务的平台性能、尤其是数据库性能构成了严峻的挑战,即便是相关领域的老牌玩家、身为全球 IT 和互联网行业的领先企业的百度,也需要对其进行持续的优化和革新。
“成长的烦恼”,百度Feed流服务撞上“内存墙”
此前,大家在提及IT平台性能时,如果没有特指,基本都是对应其主要算力单元的性能表现,但为什么在Feed流服务中,数据库性能也会如此关键?
这一点,其实是由Feed流服务的本质及架构决定的,正如上文所说,它的主要功用就是要对各种信息和内容进行自动聚合和精准推送,而所有这些信息和内容都会以海量数据的型态在Feed流服务背后的数据库中进行存储,还需要进行尽可能高效地访问和处理,惟其如此才能实现迅捷和精准的推送结果。
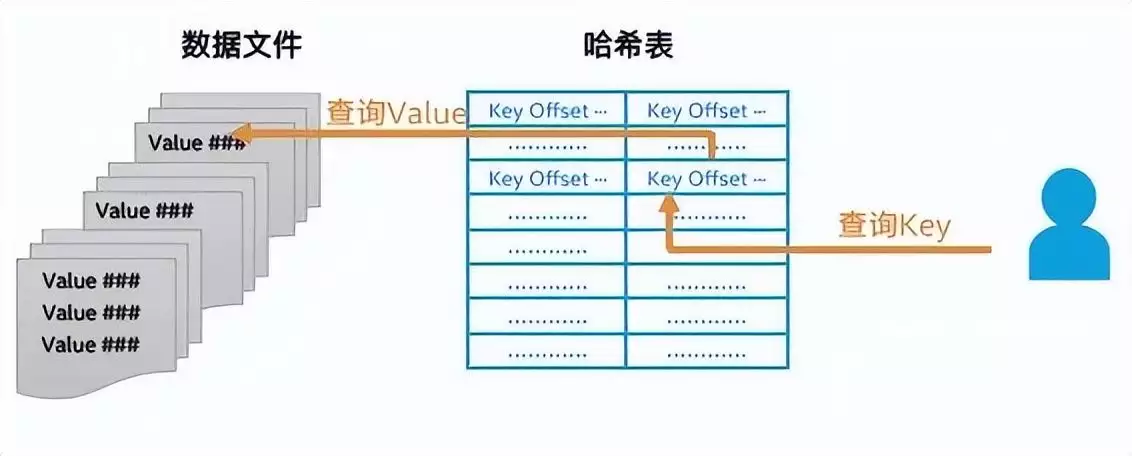
图一、百度Feed-Cube示意图
因此不论是哪家企业的Feed流服务,它们基本都是围绕背后的核心数据库构建起来的。百度也是如此,它早在数年前就构建了Feed流服务所需的数据库Feed-Cube。而且从自身的业务状况出发,为满足数以亿计的用户规模、千万量级的并发服务,以及更低时延的数据处理性能,百度还在Feed-Cube构建之初就把它打造成了一个内存数据库,并采用了KV(Key- Value,键值对)的存储结构。在这个结构中, Key值,以及Value值所在数据文件的存储偏移值都存放在哈希表中,而Value值则单独存放在不同的数据文件中。此外,所有哈希表和数据文件均存放在内存中,从而能充分借助内存的高速I/O能力来提供出色的读写性能和超低时延。
尽管拥有如此前瞻的架构设计,Feed- Cube还是会遇到挑战——虽然在每秒千万次查询的高并发和PB级海量数据存储环境下它的表现一直优异,但在百度Feed流服务规模持续扩展、数据规模也持续增长的情况下,它还是遇到了内存容量扩展跟不上数据存储需求发展的问题,或者说,撞上了“内存墙”的考验。
内存墙这个词,原本是用以描述内存与算力单元之间的技术发展差距所导致的性能瓶颈,而在大数据和AI时代数据处理需求更多走向实时化后,它也增添了容量层面的含义,即用户为了尽可能提升数据读写和处理的效率,不得不将更大体量的数据从存储中移到距算力更近、带宽和I/O性能更优的内存中,但内存容量扩展不易和成本过高的问题,却使得它难以承载更大体量的数据,这种情形,就像是内存在容量上也有了一层看不见摸不着,但又实实在在存在的围墙。
如果要问为何内存容量扩展难,成本也高?那就要谈到DRAM身上。作为目前内存普遍使用的介质,DRAM在单条服务器内存上的主流容量配置多是32GB或64GB,128GB少见且价格昂贵,任何人如果想使用DRAM内存来大幅扩展内存容量,那么就必须承担非常高昂的成本,而且花了大钱,最终可能还是难以实现自己想要达到的内存容量水准。
百度就曾经考虑过以堆DRAM的方式为Feed-Cube构建更大的内存池,但这一方面会使其TCO大幅抬升,另一方面,这种方式也依然跟不上Feed-Cube数据承载能力的发展要求。
在验证依靠DRAM难以突破内存墙后,百度还尝试使用性能不断提升的、基于非易失性存储(non-volatile memory,NVM)技术的存储设备,如 NVMe 固态盘来存储 Feed-Cube 中的数据文件和哈希表。但经测试发现,这一方案在QoS、IO 速度等方面都难以满足服务需求。
傲腾™ 持久内存成破“墙”利器,兼顾性能、容量和成本收益
求助DRAM和NVMe固态盘都不顺利,那么Feed-Cube突破内存墙的路径和方案到底在哪里呢?百度抱着寻求突破性方案的初衷,把眼光瞄向合作多年的伙伴英特尔,瞄向它意在颠覆传统内存-存储架构的傲腾™ 持久内存。
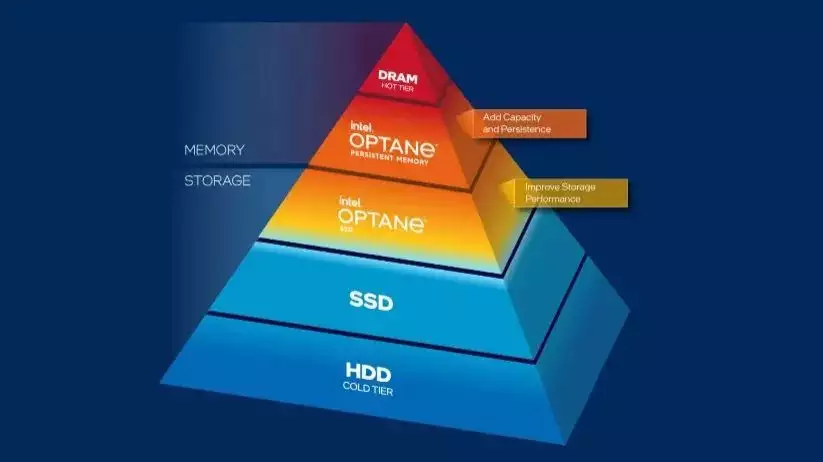
图二、傲腾™持久内存在内存-存储层级中的位置及作用
傲腾™ 持久内存进入百度视野的原因其实很简单,即它比较好的兼顾了现有DRAM内存和存储产品的优势,同时又不像它们那样有各自明显的不足之处——它凭借创新的介质,可提供接近DRAM的读写性能和访问时延、更接近固态盘的存储容量,并支持DRAM内存所不具备的数据持久性和更高价格容量比,以及NAND固态盘所无法比肩的耐用性。这使得它在多用户、高并发和大容量的场景下有着非常突出的优势,也特别适合用于扩展内存来承载更大体量、需要更高读写速度和时延来处理的数据。
有鉴于此,百度开始尝试使用傲腾™ 持久内存来破解Feed-Cube面对的内存墙问题。其做法就是用持久内存来存储Feed-Cube中的数据文件部分,并仍用DRAM来存放哈希表。采用这一混合配置的目的,一方面是为了验证傲腾™ 持久内存在 Feed-Cube 中的性能表现;另一方面,Feed- Cube 在查询 Value 值的过程中,读哈希表的次数要远大于读数据文件,因此先在数据文件部分进行替换,可以尽可能地减少对 Feed-Cube 性能的影响。
与此同步,百度还与英特尔合作,根据 Feed-Cube 应用场景的需求,在服务器 BIOS 中加入了对傲腾™ 持久内存的支持驱动,还在百度自研Linux内核的基础上增添了相关的补丁,以求实现硬件、操作系统、内核等组件的全方位优化,进而充分释放整个系统的性能潜力。
经过这一系列操作后,百度就模拟了实际场景中可能出现的大并发访问压力,对纯 DRAM 内存模式与上述混合配置模式进行了对比测试。测试中,每秒查询次数(Query Per Second,QPS)设为 20 万次,每次访问需要查询 100 组 Key-Value 组,总访问压力为 2 千万级。结果显示,在此如此大的访问压力下,平均访问耗时仅上升约 24%(30 微秒),处理器消耗整机占比仅上升7%,性能波动也在百度可接受的范围内。而与此相对应的是,单服务器的 DRAM 内存使用量下降过半,这对于 Feed-Cube PB 级的存储容量而言,无疑可大大降低成本。
在这一成果的激励下,百度又进一步尝试将 Feed-Cube的哈希表及数据文件都存入傲腾™ 持久内存中,以每秒 50 万次查询(QPS)的访问压力进行测试,结果证明这一模式与只配置DRAM 内存的方案相比,平均时延仅上升约 9.66%,性能波动也在百度可接受的范围内。
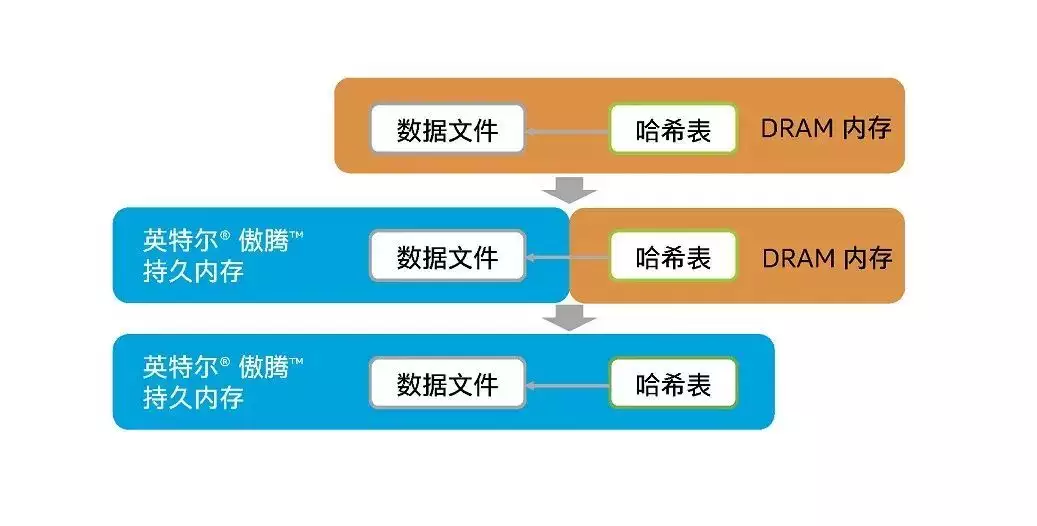
图三、百度Feed-Cube内存硬件变化路径
经过这些探索和实践,百度最终验证了其 Feed 流服务的核心模块 Feed-Cube 从仅配置 DRAM 内存的模式,迁移至同时使用 DRAM 内存与英特尔® 傲腾™ 持久内存的混合配置模式,再到全面依托英特尔® 傲腾™ 持久内存模式的可行性。这一系列创新举措在大并发访问压力下的优异的性能表现以及符合百度预期的资源消耗,充分展示了傲腾™ 持久内存在打破内存墙过程中发挥的关键作用。
打破内存墙 给行业数智转型带来的启示
毫无疑问,随着各行各业云化、数字化和智能化转型的加速,越来越多的大数据和AI应用的落地,大家不论是整体,还是个体都面临数据规模、数据维度和复杂性的大幅增长,加之用户对服务时效性等需求不断提升,所有相关的系统和应用不但对算力提出了更多样化和更为严苛的挑战,也要求内存-存储架构在性能和容量层面都能跟上算力和数据的演进趋势。如果我们再考虑到企业对低成本、高效率的无限追求,这一切就使得传统的通常增添DRAM来拓展内存容量的方式已几近成为历史,所有面临内存墙挑战的人,都需要像百度一样,必须要寻求变革性的技术、颠覆性的方案方能尽拂破墙而出,开启高效服务新篇章。
以上就是关于《优化Feed流遭遇拦路虎 是谁帮百度打破了“内存墙”?-feed优化师证书》的全部内容,本文网址:https://www.7ca.cn/baike/19689.shtml,如对您有帮助可以分享给好友,谢谢。