深度学习实用算法(1)-Transformer(tensorflow和pytorch哪个好)
背景
Transformer all you need (=?) Attention Is All You Need。深度学习被工业界广泛应用于生产中了,满足性能情况下慢慢取代了部分原来机器学习算法的应用,提供更精确推理结果。基于Transformer基础模型结构,学术界已产生大多是许多变种的SOTA的模型,Transformer-XL、Swin-transformer、TFT、Informer、谷歌的Bert大型算法等等。因此,万变不离其宗,在惊叹各种模型的优秀的同时,最底层Transformer模型成为必须学习基础模型。丰富其算法技能树,它成为优秀的算法工程师必经之路。
论文PDF地址:
(强烈建议:先阅读完本文章或原论文PDF文件,再看沐神Transformer算法解析视频会更容易理解)
沐神学习视频地址:

一、原理
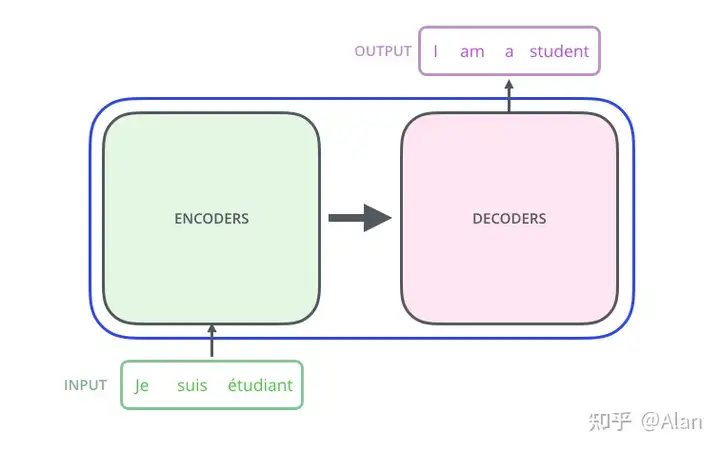
1.1基础的Encoder-Decoder结构(类似seq2seq模型)

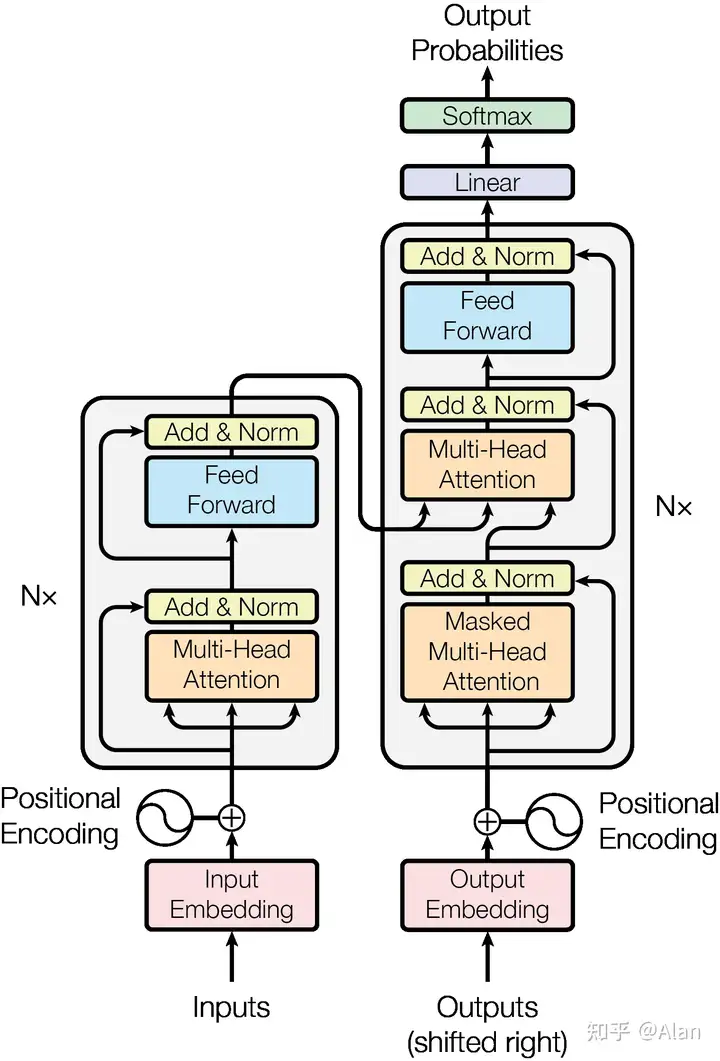
1.2Transformer的结构
每个Encoder Layer 包括两个子层: multi-head self-attention mechanism(多头注意力层) 和 positionwise fully connected feed-forward network (考虑位置信息的全连接前馈神经网络)。
每个Decoder Layer 包括三个子层:Masked multi-head self-attention mechanism (单向多头注意力层), multi-head self-attention mechanism(多头注意力层) 和 positionwise fully connected feed-forward network(全连接前馈神经网络)。
Transformer 的输入为 source sentence(原数据) 的 Embedding,包括 Input Embedding Layer 和 Position Encoding Layer。输出为target sentence 的 Embedding。
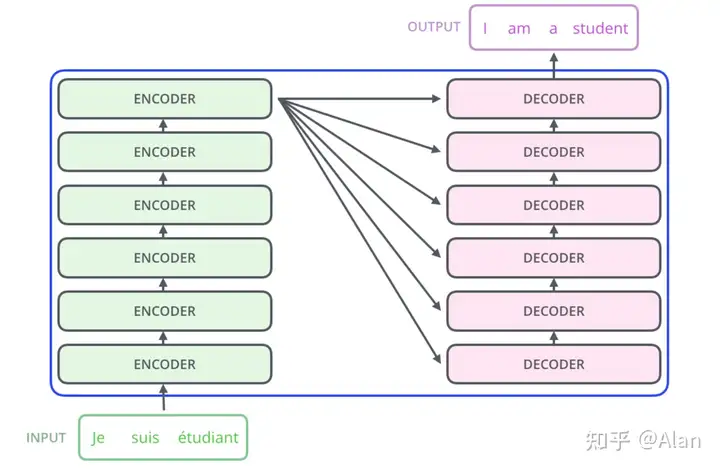
我们将大的encoder和大的decoder进行进一步拆解,此处的encoder由一堆小的encoders堆叠而成(论文中是6个),decoder处也是类似的,所以我们的模型又可以进一步插接为下图:
此处我们每个小的encoder、decoder都是一样的,那么我们就好奇了,这里每个小的encoder、decoder内部的结构又是什么样的呢?
其实,
encoder可分解为两个小的模块:一个self-attention模块以及一个Feed Forward前向的神经网络。
decoder可分解为三个的模块:由一个self-attention模块,encoder-decoder attention层和一个Feed Forward前向的神经网络层构成。
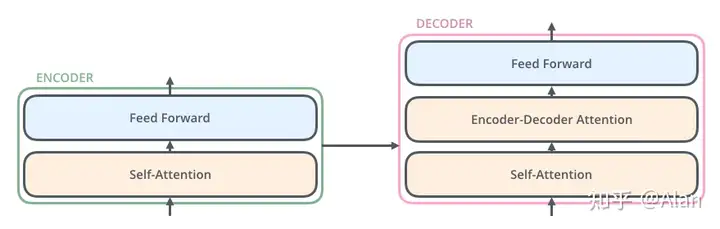
好了,这样我们就把我们的Transformer进行了细致地分解,那么接下来我们将从下而上地来看这里每一块的构成以及对应的作用。
1.3结合张量理解
从上面的内容中,我们将大的框架拆分为了一个一个小的框架,下面我们看我们在输入数据之后,是怎么在该网络中前向传播的。
假设我们输入一个句子,然后每个词进行embedding,然后我们得到:

在对词进行embedding之后,这些词汇经过第一个encoder层。
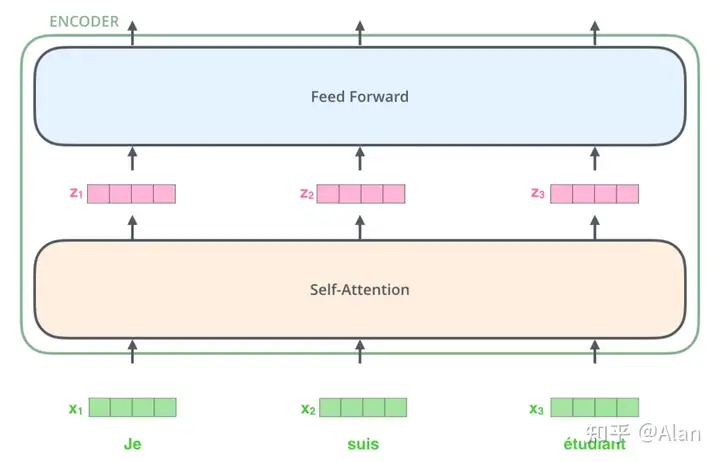
从上图中,我们可以很明显的发现Transformer的一个主要的性质,这些单词在self-attention层中是存在依赖关系的,但是在前向传播的时候是不存在依赖关系的,所以这一块是可以并行执行的。
那么我们来看看在每个encoder的子层中都发生了什么。
二、Transformer模块分析
2.1 Encode编码
我们上面说过,一个编码器会先接受一些向量作为输入,它先将这些向量传入self-attention层,然后再喂到一个前向神经网络,最后将输出传递到下一个编码器。
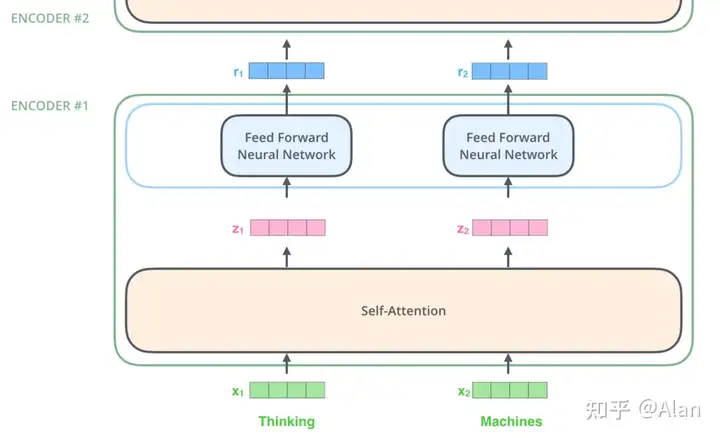
2.2 Self-Attention
Self-Attention的抽象理解
假设我们希望翻译下面的句子:
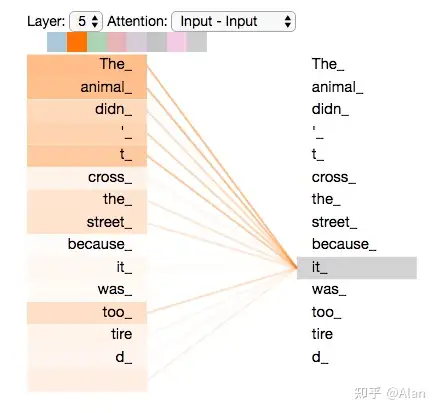
”The animal didnt cross the street because it was too tired”此时,我们并不知道句子中“it”是什么含义?它究竟指的是街道还是动物,我们人为看的话或许很简单,但是现在我们希望算法能够理解它。也就是说,当我们碰到"it"的时候,我们希望self-attention能帮助我们的模型将它与"animal"相关联。
当模型处理每个单词的时候,self-attention允许它能看到其它位置不同的词,从而帮助我们模型更好的理解,对原词汇能有一个更加好的编码。
Self-attention就是一种方法,它能让我们当前处理的相关词得到更好地表示,被机器更好地理解。
例如刚刚的例子,我们希望it与animal的关系更加紧密,向量之间能更近。
Self-Attention的细节
单个向量计算
上面我们说希望词向量再经过self-attention层,能够让处理的相关词汇能得到更好的表示,那么究竟是怎么做的呢?
构建三个输入encoder的输入向量,所以对于每个词,我们构建
一个Query的向量,一个Key向量和一个Value向量。注意这些新的向量再维度上时小于embedding向量的,它们的维度是64维,前面我们说embedding的维度是512.理由是:(this is an architecture choice to make the computation of multiheaded attention (mostly) constant.),于是我们便得到下面这张图:
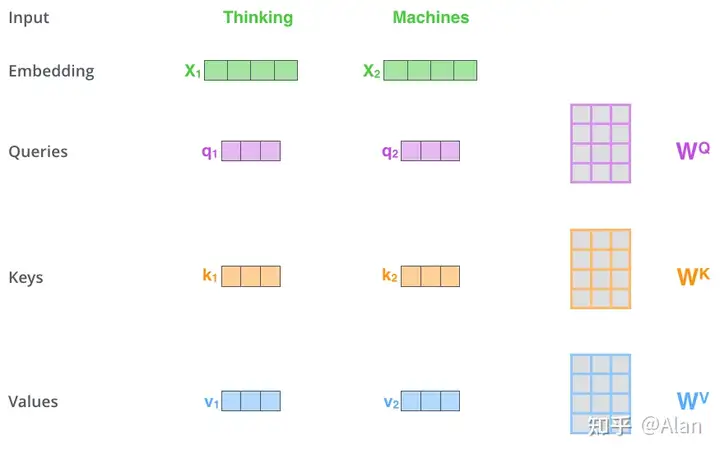
那么此处的"query","key","value"向量究竟是什么呢?
它们是抽象概念,有助于计算和思考attention,是不是讲得很模糊,哈哈,那么我们继续往下看。这里我们需要计算一个分数,举例来说,我们要为例子中的第一个单词"Thinking"计算self-attention,我们需要计算输入句子中的每个单词与它的分数,这个分数反映了输入句子的其他部分要集中多少注意力在这个特定位置的词上面。那么这个分数是如何计算的呢?
我们先计算query向量和key向量的点积,如下图,第一个score就是q1和k1的点积,第二个score就是q1和k2的点积。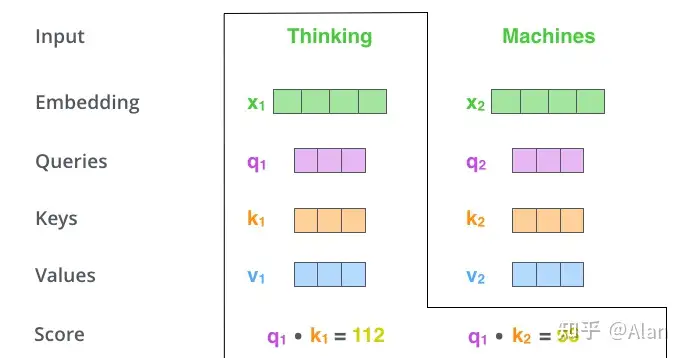
接下来,我们需要这个分数除以8 = sqrt(64), key向量的平方根,这可以使得我们的梯度更加稳定。(8是默认值,可以修改),然后我们将这些score通过softmax进行归一化,得到:
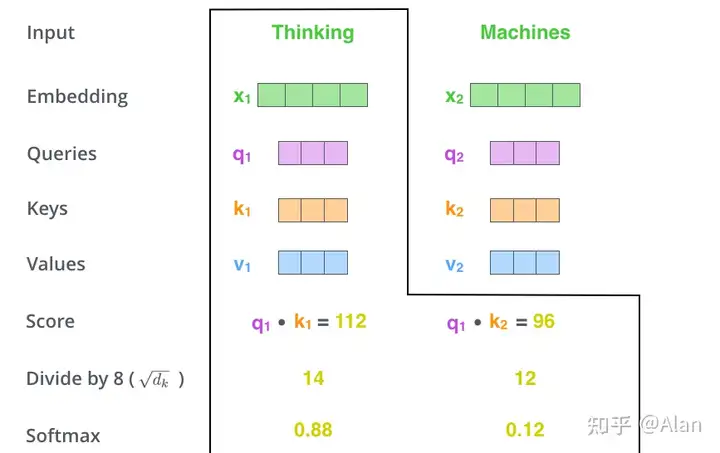
softmax的分数决定了每个单词在该位置上的一个表示,很明显,原来的词在该位置上是有着最高的softmax分数的。
最后我们将每个value向量乘上对应的softmax分数,本质是希望保持我们想关注的单词的值不变,并淹没掉不相关的单词(例如,通过将它们乘以0.0001这样的小数字)。
最后我们将加权的value向量相加,得到我们self-attention层在该位置的输出。
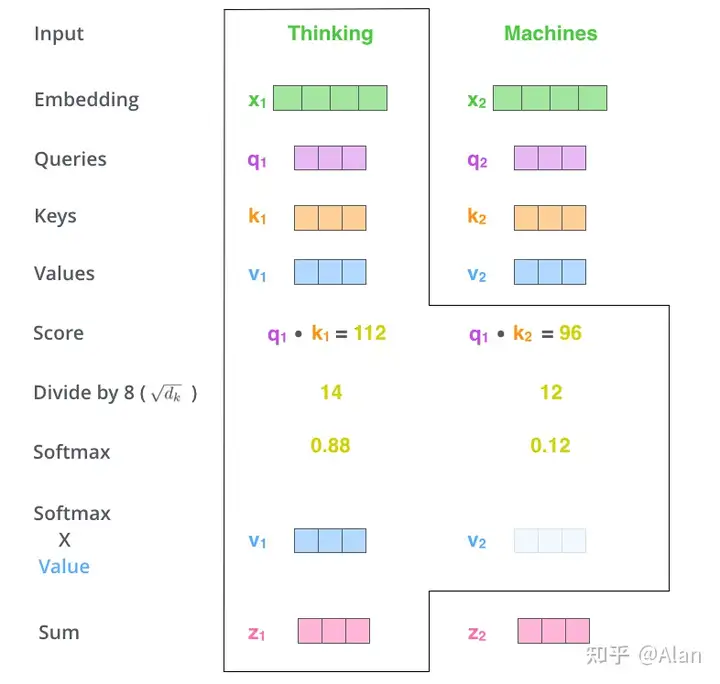
上面就是我们self-attention层的计算过程,最终的向量就是我们输入下一层前向神经网络的向量。
注意:在实际的操作中,为了快速的计算,该操作是通过矩阵的形式进行的。下面我们就用矩阵的来过一遍。
Self-Attention的矩阵计算
第一步,计算Query,Key,Value矩阵,我们将输入的句子作为矩阵X,然后分别乘上不同的权重矩阵(WQ,WK,WV).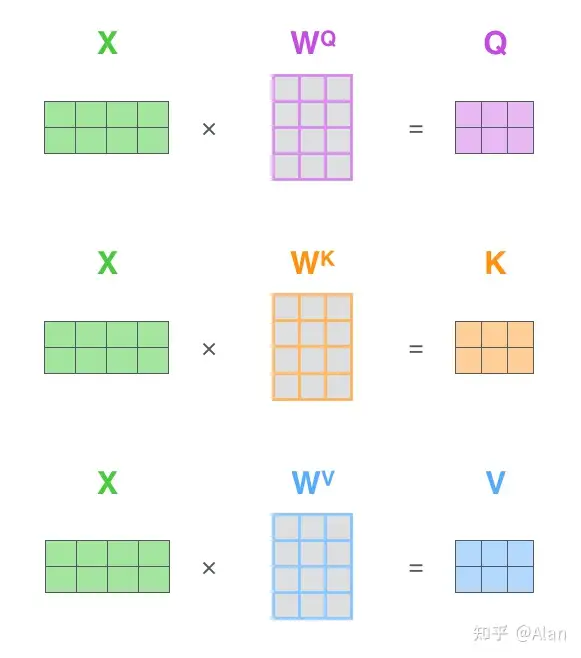

2.3 Multi-headed Attention(⭐️重点)
除了self-attention层之外,还有一个重要的叫做multi-headed attention,它从两个方面对我们的attention层进行改进。
扩展了模型的能力,使其能关注更多的位置,从上面的例子中,我们发现,z1或多或少会包含其他的编码部分,但是它会被其他的词所dominated,当我们对一个句子进行转换时,这会显得非常有效,例如当我们对一个句子进行翻译时,“The animal didn’t cross the street because it was too tired”,我们非常希望知道"it"指的是什么。它使得我们的attention层更多的“representation subspaces”,后面我们将会发现,multi-headed attention不是由单个组成,而是由多个Query/Key/Value的权重矩阵集合组成。(Transformer使用了8个attention heads,所以此处我们也使用8个). 每个集合都是随机初始化的, 在训练完之后,每个集合将输入的embedding投影到不同的表示子空间中。
如果我们对做self-attention操作,使用8个不同的权重矩阵,最终我们可以得到8个不同的Z矩阵。

这就有问题了,因为前向神经网络并不希望一下输入8个矩阵,只是希望单个矩阵(一个词一个向量),所以我们需要将8个矩阵压缩为单个的矩阵。那么怎么做呢,我们使用concat操作,并且最后我们乘上一个权重矩阵WO.

上面就是multi-headed attention的全部了,我们将其全部放到一张图中便得到:

现在我们已经学习了attention heads,我们再看看不同的attention heads所关注的"it",

我们发现,我们对词"it"进行编码时,有一个attention的head更加关注"the animal",然后另外一个更加关注"tired",从某种意义上说,模型对于词"it"的表示同时受到"animal"和"tired"表示的影响。
2.4 Positional Encoding位置编码表示序列的顺序
上面的内容我们介绍了self-attention和multiheaded-attention,但是在做序列相关的问题时,我们还需要考虑单词在序列中的位置。为了解决该问题,Transformer对每个输入embedding的向量加上一个其它向量,这些向量随模型所学习的特定pattern,这可以帮助我们更好地确定每个词的位置或者它与序列中其它不同词的距离。
而我们的直觉告诉我们将位置编码加入到词embedding中将会给与原先词向量更多有意义的表示。

如果我们假设embedding的维度是4,实际的位置编码就变为:

在下图中,每行表示一个向量的位置编码, 所以第一行就是我们在输入序列中和第一个单词embedding相加的向量,这边每一行都有512个值,每个值的大小在-1到1之间,

位置编码可以帮助我们了解看不到的序列长度.(例如,如果我们训练的模特被要求翻译比我们训练中任何一个更长的句子)
2.5 残差网络The Residuals
在论文的框架中还有一个细节,在每个encoder中,每个子层有一个残差链接,之后跟随一个layer-normalization步.


再细化一下:

我们假设Transformer是由两个encoder和decoder堆叠起来的,那么我们的框架如下所示:

2.6 Decoder部分
上面的部分,我们已经cover了encoder部分的大量概念,我们基本也知道decoder是如何工作的,下面我们看看二者在一起是如何工作的。
Encoder部分先对输入序列进行处理,顶层的encoder的输出转化为attention向量K和V的集合,K和V会被后面的每个decoder使用(在encoder-decoder attention层)用来帮助decoder更好地关注输入序列的特定位置。
上面是第一步,接下来的步骤都是类似的,直到我们一个特殊的符号出现,我们decoder层才会终止它的输出。
每一步的输出都会在下一步被喂进decoder(加入decoder的输入),然后decoder和encoder一样样重复着从输入到输出的过程。
注意,decoder处的self-attention层和encoder处的有些许不一样。在decoder处,self-attention层值允许将之前位置加入到输出的序列中。(通过masking未来的位置来实现),
"Encoder-Decoder Attention"层的工作机制就像是multiheaded self-attention,区别在于它构建Queries矩阵是从decoder的最下方,然后从encoder stack的输出层拿到我们的Keys和Values.
2.7 最终的线性层和Softmax层
decoder的堆积输出了浮点数的向量,那么我们如何将其转化为一个单词,这也是为什么最后连接一个线性层和一个Softmax层的原因。

线性层
线性层的作用就是将由一系列decoder的堆积的向量投影到一个更加大的向量。
我们假设我们的模型知道10000个不同的英语单词(我们模型的输出词库),我们的logits向量就是10000个cell,每个cell对应一个词的分数。
Softmax层
softmax层将这些分数转化为概率(0-1),所有的cell中最大的概率就被选为最终的结果。
2.8 损失函数
在上面的章节中,我们已经打通了整个流程,但是我们还缺一个,我们要让我们的模型训练起来,还需要一个损失函数,因为我们的模型是一个监督的模型,我们有标签,接下来就是对这些标签进行表示,并设计损失函数了。
我们假设我们的输出词库只含有6个单词(“a”, “am”, “i”, “thanks”, “student”, and “<eos>” (short for ‘end of sentence’),我们将其映射到:

一旦我们定义好了输出词库,我们就可以使用相同宽度的向量来表示每个词,最典型的例如one-hot编码,例如下面的"am"我们就可以表示为:

下面我们在看看模型的损失函数。
通过softmax层的描述,我们知道我们的模型输出的是一个概率向量,我们将其与我们的label放一起得到,

那么如何衡量我们的预测结果与真实结果的差异呢? 可以使用cross-entropy或者KL divergence等。
假设我们现在:
input: “je suis étudiant”expected output: “i am a student”这意味着什么呢? 我们希望我们的模型能够连续输出概率分布,其中
每个概率分布由一个词库大小长度的向量表示(这边是6,但是实践中往往不止是6)第一个概率分布概率分布在位置i上有最高的概率;第二个概率在对应的单词"am"上有最高的概率;以此类推,知道我们碰到第五个输出概率表示 "<end of sentence>"的符号。
在足够大的数据集上面训练之后,我们希望我们输出的概率分布如下:

因为模型一次产生一个输出,我们可以假设模型是从概率分布中选择概率最高的词,然后丢弃其余的词。这是一种方法(称为贪婪解码,Greedy docoding)。
另外一个方法是:保持前两个单词(例如,说“I”和“a”),然后在下一步中,运行模型两次:一次假设第一个输出位置是单词"I",另一次假设第一个输出位置是单词"a",无论哪一个版本在考虑位置1和位置2的情况下产生的误差都较小。我们对位置2和位置3等重复此操作。此方法称为"beam search",在我们的示例中,beam_size为2(因为我们在计算位置1和位置2的beam后比较了结果),top_beam也是2(因为我们保留了两个字)。
小结
我们先将Transformer的框架进行一步步拆解,然后再模拟了输入到输出的整个过程。
本文中有很多重要的概率,包括self-attention,multi-head attention等,这里面的Q,K,V三者的理解也是非常重要的。
三、应用
3.1、NLP文本分类
Text Classification using Transformers
利用Transformer模型进行电影评论分类_为之,则难者亦易矣;不为,则易者亦难矣。-CSDN博客
3.2、时序预测
3.3、图像分类
3.4、其他
后续补充
四、框架API使用(人生苦短,我选API)
4.1基于Pytorch Lighting框架(理解TensorFlow 高级API的Kears即可):
TUTORIAL 5: TRANSFORMERS AND MULTI-HEAD ATTENTION
4.2 基于AWS的MxNet、GluonTS:
五、参考资料链接
强烈推荐阅读:https://jalammar.github.io/illustrated-transformer/https://github.com/tensorflow/tensor2tensorAttention机制详解(二)——Self-Attention与Transformer:https://zhuanlan.zhihu.com/p/47282410Attention Is All You Need(注意力模型):https://zhuanlan.zhihu.com/p/44731789直观“Attention 模型”:https://zhuanlan.zhihu.com/p/62397974multi-head attention:https://www.cnblogs.com/rosyYY/p/10115424.htmlTransformer详解:https://zhuanlan.zhihu.com/p/44121378Attention and Self-Attention:https://www.jianshu.com/p/d7f50cc5560eAttention Is All You Need:https://arxiv.org/abs/1706.03762以上就是关于《深度学习实用算法(1)-Transformer(tensorflow和pytorch哪个好)》的全部内容,本文网址:https://www.7ca.cn/tg/42139.shtml,如对您有帮助可以分享给好友,谢谢。




