Apache Arrow_apache日志存储路径
目录:
1.apache日志位置
2.apache日志文件目录
3.apache日志文件名
4.apache2日志
5.apache日志格式详解
6.apache日志中包含哪些内容
7.apache日志配置文件
8.apache 访问日志路径
9.apache记录日志的两个文件
10.apache 日志目录
1.apache日志位置
背景Apache Arrow 将列式数据结构的优势与内存计算相结合它提供了这些现代技术的性能优势,同时还提供了复杂数据和动态模式的灵活性它以开源和标准化的方式完成所有这些工作在过去的几十年里,数据库和数据分析发生了翻天覆地的变化。
2.apache日志文件目录
企业对分析和使用数据的要求越来越复杂,对查询性能的标准也越来越高内存变得便宜,支持基于内存分析的一套新的性能策略CPU 和 GPU 的性能有所提高,但也已经发展到可以优化并行处理数据针对不同的用例出现了新型数据库,每种都有自己的存储和索引数据的方式。
3.apache日志文件名
例如,由于现实世界的对象更容易表示为分层和嵌套的数据结构,因此 JSON 和面向文档的数据库变得流行起来新学科已经出现,包括数据工程和数据科学,它们都具有数十种新工具来实现特定的分析目标列式数据表示已成为分析工作负载的主流,因为它们在速度和效率方面具有显着优势。
4.apache2日志
考虑到这些趋势,一个明确的机会出现了,即每个引擎都可以使用的标准内存表示法——一个现代的,利用所有可用的新性能策略,并使跨平台无缝和高效的数据共享这就是 Apache Arrow 的目标Arrow 项目的愿景是提供内存数据分析 (in-memory analytics) 的开发平台,让数据在异构大数据系统间移动、处理地更快:。
5.apache日志格式详解
项目主要由 3 部分构成:为分析查询引擎 (analytical query engines)、数据帧 (data frames) 设计的内存列存数据格式用于 IPC/RPC 的二进制协议用于构建数据处理应用的开发平台
6.apache日志中包含哪些内容
整个项目的基石是基于内存的列存数据格式,现在将它的特点罗列如下:标准化 (standardized),与语言无关 (language-independent)同时支持平铺 (flat) 和层级 (hierarchical) 数据结构
7.apache日志配置文件
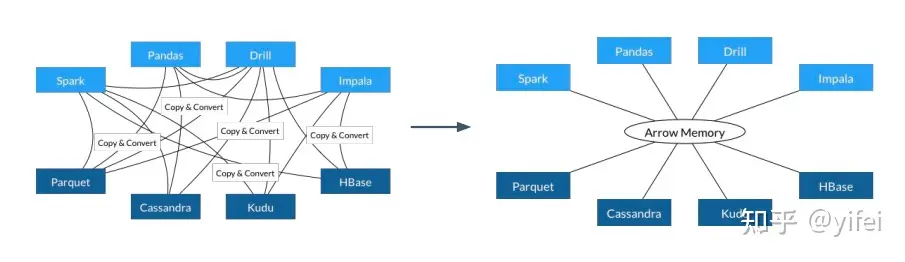
硬件感知 (hardware-aware)Apache Arrow 核心技术Arrow 本身不是存储或执行引擎它旨在作为以下类型系统的共享基础:SQL 执行引擎(例如,Drill 和 Impala)数据分析系统(例如 Pandas 和 Spark)
8.apache 访问日志路径
流和队列系统(例如,Kafka 和 Storm)存储系统(例如 Parquet、Kudu、Cassandra 和 HBase)Arrow 包含许多旨在集成到存储和执行引擎中的连接技术Arrow 的关键组件包括:。
9.apache记录日志的两个文件
定义的数据类型集包括 SQL 和 JSON 类型,例如 int、BigInt、decimal、varchar、map、struct 和 arrayDataSet 是数据的列式内存表示,以支持构建在已定义数据类型之上的任意复杂记录结构。
10.apache 日志目录
常见数据结构 Arrow感知伴随数据结构,包括选择列表、哈希表和队列在共享内存、TCP/IP 和 RDMA 中实现的进程间通信用于以多种语言读写列式数据的数据库,包括 Java、C++、Python、Ruby、Rust、Go 和 JavaScript 。
用于各种操作的流水线和 SIMD 算法,包括位图选择、散列、过滤、分桶、排序和匹配列内存压缩包括一系列提高内存效率的技术内存持久性工具,用于通过非易失性内存、SSD 或 HDD 进行短期持久化因此,Arrow 不与任何这些项目竞争。
它的核心目标是在它们中的每一个中工作以提供更高的性能和更强的互操作性事实上,Arrow 是由许多此类项目的主要开发人员构建的Apache Arrow 的优势表现用户获得答案的速度越快,他们提出其他问题的速度就越快。
高性能带来更多分析、更多用例和进一步创新随着 CPU 变得更快、更复杂,关键挑战之一是确保处理技术有效地使用 CPUArrow 专门设计用于最大化:缓存局部性:内存缓冲区是为现代 CPU 设计的数据的紧凑表示。
这些结构是线性定义的,与典型的读取模式相匹配这意味着相似类型的数据在内存中位于同一位置这使得缓存预取更有效,最大限度地减少了缓存未命中和主内存访问导致的 CPU 停顿这些 CPU 高效的数据结构和访问模式扩展到传统的平面关系结构和现代复杂数据结构。
流水线:执行模式旨在利用现代处理器的超标量和流水线特性这是通过最小化循环内指令数和循环复杂性来实现的这些紧密的循环导致更好的性能和更少的分支预测失败SIMD 指令:单指令多数据 (SIMD) 指令允许执行算法通过在单个时钟周期内执行多个操作来更有效地运行。
Arrow 组织数据以使其非常适合 SIMD 操作缓存位置、流水线和超标量操作经常提供 10-100 倍更快的执行性能由于许多分析工作负载受 CPU 限制,这些优势转化为显着的最终用户性能提升这里有些例子:。
PySpark:在 PySpark 中添加对 Arrow 的支持后,IBM 测得Python 和 Spark 的数据处理速度提高了 53 倍Parquet 和 C++:以高达 4GB/s 的速度从 C++ 将数据读入 Parquet
Pandas:读入 Pandas高达 10GB/sArrow 还提倡零拷贝数据共享由于每个系统都采用Arrow作为内部表示,一个系统可以直接将数据交给另一个系统进行消费而当这些系统位于同一个节点时,也可以通过使用共享内存来避免上述的副本。
这意味着在许多情况下,在两个系统之间移动数据不会产生开销内存效率内存中性能很好,但内存可能不足Arrow 设计为即使数据不能完全放入内存也能正常工作核心数据结构包括数据向量和这些向量的集合(也称为记录批次)。
记录批次通常为 64KB-1MB,具体取决于工作负载,并且通常限制为 2^16 条记录这不仅提高了缓存的局部性,而且即使在低内存情况下也可以进行内存计算对于从数百到数千台服务器不等的许多大数据集群,系统必须能够利用集群的聚合内存。
Arrow 旨在最大限度地降低在网络上移动数据的成本它利用分散/聚集读取和写入,并具有零序列化/反序列化设计,允许节点之间的低成本数据移动Arrow 还直接与支持 RDMA 的互连一起工作,为更大的内存工作负载提供单一内存网格。
arrow在内存中表示数据的最基本单元是array,它代表了一连串长度已知、类型相同的数据而多个长度相同、类型相同或者不同的array就可以用来表示结果集(或者一部分的结果集)举一个简单的例子:一个如下图所示的结果集(或者table)。
+------+------+ | C1 | C2 | [ |------+------| DoubleArray: [ 1.11, 2.22, 3.33], | 1.11 | foo | -> StringArray: [ foo, bar, NULL] | 2.22 | bar | ] | 3.33 | NULL | +------+------+
就可以表示成一个大小为2的有序集合,集合中的array(DoubleArray 和 StringArray)长度为3arrow限制了array的最大长度,当结果集(或者表)的大小超过了array的最大长度,就需要把结果集水平切分成多个有序集合。
接一下来我们具体来看一下array,arrow是这样定义一个array的:逻辑类型(比如 int32 或者 timestamp)一串buffer(用来存放具体的数据和表示NULL值)array长度array中NULL值的数量
dictionary (用于dictionary encoding,比较适用于有很多重复数据的array,相当于一个压缩算法,不是必需的)定长的数据格式如下:type FixedColumn struct { data []byte length int nullCount int nullBitmap []byte // bit 0 is null, 1 is not null }
除了数据数组 (data) 外,还包含:数组长度 (length)null 元素的个数 (nullCount)null 位图 (nullBitmap)举一个具体的例子,一个如下的Int32Array:[1, null, 2, 4, 8]
会被表示成* Length: 5, Null count: 1 * Validity bitmap buffer: |Byte 0 (validity bitmap) | Bytes 1-63 | |-------------------------|-----------------------| | 00011101 | 0 (padding) | * Value Buffer: |Bytes 0-3 | Bytes 4-7 | Bytes 8-11 | Bytes 12-15 | Bytes 16-19 | Bytes 20-63 | |------------|-------------|-------------|-------------|-------------|-------------| | 1 | unspecified | 2 | 4 | 8 | unspecified |
可以看出,无论数组中的某个元素 (cell) 是否是 null,在定长数据格式中 Arrow 都会让该元素占据规定长度的空间;可以利用指针代数支持 O(1) 的随机访问从 nullBitmap 的结构可以看出,Arrow 采用 little-endian 存储字节数据。
Variable-width data types变长的数据列格式如下所示:type VarColumn struct { data []byte offsets []int64 length int nullCount int nullBitmap []byte // bit 0 is null, 1 is not null }
可以看出,比定长列仅多存一个偏移量数组 (offsets)offsets 的第一个元素固定为 0,最后一个元素为数据的长度,即与 length 相等,那么关于第 i 个变长元素:pos := column.offsets[i] // 位置 size := column.offsets[i+1] - column.offsets[i] // 大小。
另一种备选方案是在 data 中利用特殊的字符分隔不同元素,在个别查询场景下,后者能取得更优的性能如扫描字符串列中包含某两个连续字母的所有列:利用 Arrow 的格式需要频繁地访问 offsets 来遍历 data,但利用特殊分隔符的解决方案直接遍历一次 data 即可。
而在其它场景下,如查询某字符串列中值和 “hello world” 相等的字符串,这时利用 offsets 能过滤掉所有长度不为 11 的列,因此利用 Arrow 的格式能获取更优的性能Nested Data
数据处理过程中,一些复杂数据类型如 JSON、struct、union 都很受开发者欢迎,我们可以将这些数据类型归类为嵌套数据类型Arrow 处理嵌套数据类型的方式很优雅,并未引入定长和变长数据列之外的概念,而是直接利用二者来构建。
假设以一所大学的班级 (Class) 信息数据列为例,该列中有以下两条数据:// 1 Name: Introduction to Database Systems Instructor: Daniel Abadi Students: Alice, Bob, Charlie Year: 2019 // 2 Name: Advanced Topics in Database Systems Instructor: Daniel Abadi Students: Andrew, Beatrice Year: 2020
我们可以将改嵌套数据结构分成 4 列:Name、Instructor、Students 以及 Year,其中 Name 和 Instructor 是变长字符串列,Year 是定长整数列,Students 是字符串数组列 (二维数组),它们的存储结构分别如下所示:
Name Column: data: Introduction to Database SystemsAdvanced Topics in Database Systems offsets: 0, 32, 67 length: 2 nullCount: 0 nullBitmap: | Byte 0 | Bytes 1-63 | |----------|------------| | 00000011 | 0 (padding)| Instructor Column: data: Daniel AbadiDaniel Abadi offsets: 0, 12, 24 length: 2 nullCount: 0 nullBitmap: | Byte 0 | Bytes 1-63 | |----------|------------| | 00000011 | 0 (padding)| Students Column data: AliceBobCharlieAndrewBeatrice students offsets: 0, 5, 8, 15, 21, 29 students length: 5 students nullCount: 0 students nullBitmap: | Byte 0 | Bytes 1-63 | |----------|------------| | 00011111 | 0 (padding)| nested student list offsets: 0, 3, 5 nested student list length: 2 nested student list nullCount: 0 nested student list nullBitmap: | Byte 0 | Bytes 1-63 | |----------|------------| | 00000011 | 0 (padding)| Year Column data: 2019|2019 length: 2 nullCount: 0 nullBitmap: | Byte 0 | Bytes 1-63 | |----------|------------| | 00000011 | 0 (padding)|
这里的 Students 列本身就是嵌套数据结构,而外层的 Class 表包含了 Students 列,可以看出这种巧思能支持无限嵌套所以,总结来说,优势如下:具体的值存放在value buffer中,相对应的值如果是NULL的话,value buffer中的bytes可以是任意的值。
NULL值是用bitmap来表示,bit 0 表示NULL,bit 1表示非NULL值,value buffer中的值是有意义的如果array中没有NULL值,这个bitmap也可以省略allocate memory on aligned addresses:每次分配内存的大小总是8或者64的倍数。
注意我们仅仅需要一个字节就能表示这个array的NULL值,value buffer也仅仅需要20个字节,但是arrow为每个buffer都分配64个字节的内存大小主要原因是便于编译器生成SIMD指令,进行向量化运算。
网上有很多关于向量化运算的文章,有兴趣的小伙伴可以自行搜索一下Fixed-Size Primitive Type Array (e.g. Int32Array)是最简单的情况(这里也没有考虑dictionary encoding的情况),StringArray 或者其他nested type array 的情况会更加复杂一些,具体的可以参见
这里编程语言支持除了更强的性能和互操作性之外,采用 Arrow 的另一个主要好处是不同编程语言之间的公平竞争环境传统的数据共享基于 IPC 和 API 级集成虽然这通常很简单,但当用户的语言与底层系统的语言不同时,它会损害性能。
根据语言和实现的算法集,语言转换会占用大部分处理时间Arrow 目前支持 C、C++、Java、JavaScript、Go、Python、Rust 和 RubyApache Arrow 性能许多项目都包含 Arrow 以提高性能并利用最新的优化。
这些项目包括 Drill、Impala、Kudu、Ibis、Spark 等Arrow 提高了数据消费者和数据工程师的性能——这意味着花在收集和处理数据上的时间更少,而花在分析数据和得出有用结论上的时间更多。
Memory-oriented columnar format计算机发展的几十年来,绝大多数数据引擎都采用行存格式,主要原因在于早期的数据应用负载模式基本都逃不出单个实体的增删改查面对此类负载,如果采用列存格式存储数据,读取一个实体数据就需要在存储器上来回跳跃,找到该实体的不同属性,本质上是在执行随机访问。
但随着时间的推移,数据的增多,负载变得更加复杂,数据分析的负载模式逐渐显露,即每次访问一组实体的少数几个属性,然后聚合出分析结果,这时候列存格式的地位便逐渐提高在 Hadoop 生态中,Apache Parquet 和 Apache ORC 已经成为最流行的两种文件存储格式,它们核心价值也是围绕着列存数据格式建立,那么我们为什么还需要 Arrow?这里我们可以从两个角度来看待数据存储:。
存储格式:行存 (row-wise/row-based)、列存 (column-wise/column-based/columnar)主要存储器:面向磁盘 (disk-oriented)、面向内存 (memory-oriented)
尽管三者都采用列存格式,但 Parquet 和 ORC 是面向磁盘设计,而 Arrow 是面向内存设计为了理解面向磁盘设计与面向内存设计的区别,我们来看 Daniel Abadi 做的一个实验Daniel Abadi 的实验。
在一台 Amazon EC2 的 t2.medium 实例上,创建一张包含 60,000,000 行数据的表,每行包含 6 个字段,每个字段都是 int32 类型的数据,因此每行需要 24 字节空间,整张表占用约 1.5GB 空间。
我们将这张表分别用行存格式和列存格式保存一份,然后执行一个简单的查询:在第一列中查找与特定值相等的数据,即:SELECT a FROM t WHERE t.a = 477638700;不论是行存还是列存版本,CPU 的工作都是获取整数与目标整数进行比较。
但在行存版本中执行该查询需要扫描每行,即全部 1.5GB 数据,而在列存版本中执行该查询只需扫描第一列,即 0.25GB 数据,因此后者的执行效率理论上应该是前者的 6 倍然而,实际的结果如下所示:
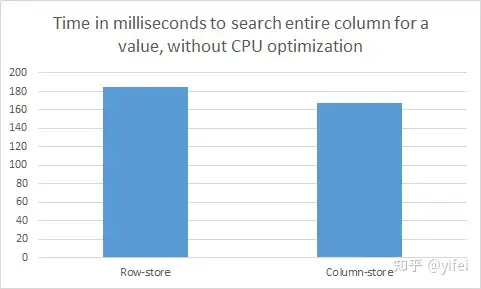
列存版本与行存版本的性能竟然相差无几!原因在于实验执行时关闭了所有 CPU 优化 (vectorization/SIMD processing),使得该查询的瓶颈出现在 CPU 处理上我们来一起分析一下其中的原因:根据经验,从内存扫描数据到 CPU 中的吞吐能达到 30GB/s,现代 CPU 的处理频率能达到 3GHz,即每秒 30 亿 CPU指令,因此即便处理器可以在一个 CPU 周期执行 32 位整数比较,它的吞吐最多为 12 GB/s,远远小于内存输送数据的吞吐。
因此不论是行存还是列存,从内存中输送 0.25GB 还是 1.5GB 数据到 CPU 中,都不会对结果有大的影响如果打开 CPU 优化选项,情况就大不相同对于列存数据,只要这些整数在内存中连续存放,编译器可以将简单的操作向量化,如 32 位整数的比较。
通常,向量化后处理器在单条指令中能够同时将 4 个 32 位整数与指定值比较优化后再执行相同的查询,实验的结果如下图所示:
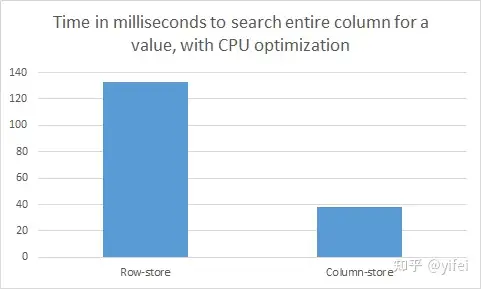
可以看到与预期相符的 4 倍差异不过值得注意的是,此时 CPU 仍然是瓶颈如果内存带宽是瓶颈的话,我们将能够看到列存版本与行存版本的性能差异达到 6 倍从以上实验可以看出,针对少量属性的顺序扫描查询的工作负载,列存格式要优于行存格式,这与数据是在磁盘上还是内存中无关,但它们优于行存格式的理由不同。
如果以磁盘为主要存储,CPU 的处理速度要远远高于数据从磁盘移动到 CPU 的速度,列存格式的优势在于能通过更适合的压缩算法减少磁盘 IO;如果以内存为主要存储,数据移动速度的影响将变得微不足道,此时列存格式的优势在于它能够更好地利用向量化处理。
这个实验告诉我们:数据存储格式的设计决定在不同瓶颈下的目的不同最典型的就是压缩,对于 disk-oriented 场景,更高的压缩率几乎总是个好主意,利用计算资源换取空间可以利用更多的 CPU 资源,减轻磁盘 IO 的压力;对于 memory-oriented 场景,压缩只会让 CPU 更加不堪重负。
Apache Parquet/ORC vs. Apache Arrow现在要对比 Parquet/ORC 与 Arrow 就变得容易一些因为 Parquet 和 ORC 是为磁盘而设计,支持高压缩率的压缩算法,如 snappy、gzip、zlib 等压缩技术就十分必要。
而 Arrow 为内存而设计,对压缩算法几乎没有要求,更倾向于直接存储原生的二进制数据面向磁盘与面向内存的另一个不同点在于:尽管磁盘和内存的顺序访问效率都要高于随机访问,但在磁盘中,这个差异在 2-3 个数量级,而在内存中通常在 1 个数量级内。
因此要均摊一次随机访问的成本,需要在磁盘中连续读取上千条数据,而在内存中仅需要连续读取十条左右的数据这种差异意味着 内存场景下的 batch 大小 (如 Arrow 的 64KB) 要小于磁盘场景下的 batch 大小。
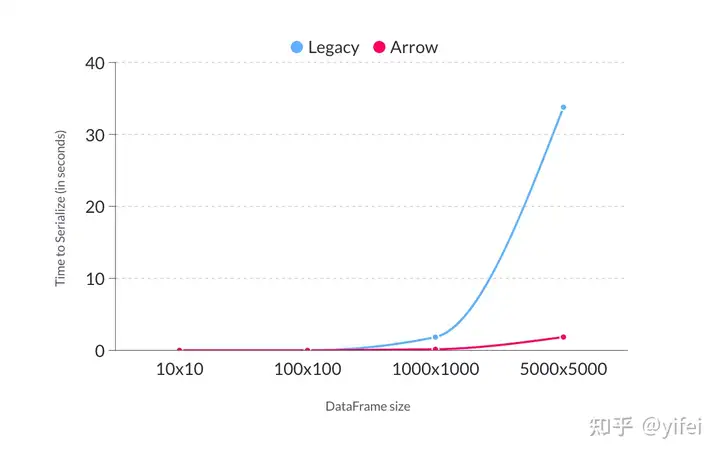
dremio是一个AP数据库,它测试的Arrow和Protobufs在数据序列化和反序列化方面的性能差异,Protobufs是他们自研的数据库序列化反序列化工具。
使用方法这里基于c++语言,探讨Arrow提供的功能和优势安装#!/bin/bash # # Script for Devs daily work. It is a good idea to use the exact same # build options as the released version. cmake .. \ -DCMAKE_CXX_COMPILER=`which g++` \ -DCMAKE_C_COMPILER=`which gcc` \ -DARROW_BUILD_UTILITIES=OFF \ -DARROW_COMPUTE=ON \ -DARROW_CSV=ON \ -DARROW_DATASET=ON \ -DARROW_FILESYSTEM=ON \ -DARROW_FLIGHT=ON \ -DARROW_FLIGHT_SQL=ON \ -DARROW_GCS=ON \ -DARROW_HDFS=ON \ -DARROW_JEMALLOC=ON \ -DARROW_JSON=ON \ -DARROW_MIMALLOC=ON \ -DARROW_ORC=ON \ -DARROW_PARQUET=ON \ -DPARQUET_REQUIRE_ENCRYPTION=ON \ -DARROW_PLASMA=ON \ -DARROW_PLASMA_JAVA_CLIENT=ON \ -DARROW_PYTHON=ON \ -DARROW_S3=ON \ -DARROW_WITH_RE2=ON \ -DARROW_WITH_UTF8PROC=ON \ -DARROW_TENSORFLOW=ON \ # end of file 。
cmake选项的含义:-DARROW_BUILD_UTILITIES=ON : Build Arrow commandline utilities -DARROW_COMPUTE=ON: Computational kernel functions and other support -DARROW_CSV=ON: CSV reader module -DARROW_CUDA=ON: CUDA integration for GPU development. Depends on NVIDIA CUDA toolkit. The CUDA toolchain used to build the library can be customized by using the $CUDA_HOME environment variable. -DARROW_DATASET=ON: Dataset API, implies the Filesystem API -DARROW_FILESYSTEM=ON: Filesystem API for accessing local and remote filesystems -DARROW_FLIGHT=ON: Arrow Flight RPC system, which depends at least on gRPC -DARROW_FLIGHT_SQL=ON: Arrow Flight SQL -DARROW_GANDIVA=ON: Gandiva expression compiler, depends on LLVM, Protocol Buffers, and re2 -DARROW_GANDIVA_JAVA=ON: Gandiva JNI bindings for Java -DARROW_GCS=ON: Build Arrow with GCS support (requires the GCloud SDK for C++) -DARROW_HDFS=ON: Arrow integration with libhdfs for accessing the Hadoop Filesystem -DARROW_JEMALLOC=ON: Build the Arrow jemalloc-based allocator, on by default -DARROW_JSON=ON: JSON reader module -DARROW_MIMALLOC=ON: Build the Arrow mimalloc-based allocator -DARROW_ORC=ON: Arrow integration with Apache ORC -DARROW_PARQUET=ON: Apache Parquet libraries and Arrow integration -DPARQUET_REQUIRE_ENCRYPTION=ON: Parquet Modular Encryption -DARROW_PLASMA=ON: Plasma Shared Memory Object Store -DARROW_PLASMA_JAVA_CLIENT=ON: Build Java client for Plasma -DARROW_PYTHON=ON: This option is deprecated since 10.0.0. This will be removed in a future release. Use CMake presets instead. Or you can enable ARROW_COMPUTE, ARROW_CSV, ARROW_DATASET, ARROW_FILESYSTEM, ARROW_HDFS, and ARROW_JSON directly instead. -DARROW_S3=ON: Support for Amazon S3-compatible filesystems -DARROW_WITH_RE2=ON Build with support for regular expressions using the re2 library, on by default and used when ARROW_COMPUTE or ARROW_GANDIVA is ON -DARROW_WITH_UTF8PROC=ON: Build with support for Unicode properties using the utf8proc library, on by default and used when ARROW_COMPUTE or ARROW_GANDIVA is ON -DARROW_TENSORFLOW=ON: Build Arrow with TensorFlow support enabled
Arrow的功能非常强大,这里先只研究其对csv,json,parquet,orc格式的支持编译有个坑,在国内编译,下载非常容易超时,多试几次才能成功测试代码:测试代码的cmake也需要链接到arrrow的相关模块:。
project(MyExample) find_package(Arrow REQUIRED) add_executable(my_example my_example.cc) target_link_libraries(my_example PRIVATE Arrow::arrow_shared) find_package(ArrowDataset REQUIRED) target_link_libraries(my_example PRIVATE ArrowDataset::arrow_dataset_shared) find_package(ArrowFlight REQUIRED) target_link_libraries(my_example PRIVATE ArrowFlight::arrow_flight_shared) find_package(ArrowFlightSql REQUIRED) target_link_libraries(my_example PRIVATE ArrowFlightSql::arrow_flight_sql_shared)
数据文件模块支持的数据格式包括IPC,ORC,parquet,csv,json数据结构 arrow::Int8Builder int8builder; int8_t days_raw[5] = {1, 12, 17, 23, 28}; ARROW_RETURN_NOT_OK(int8builder.AppendValues(days_raw, 5)); std::shared_ptr days; ARROW_ASSIGN_OR_RAISE(days, int8builder.Finish()); int8_t months_raw[5] = {1, 3, 5, 7, 1}; ARROW_RETURN_NOT_OK(int8builder.AppendValues(months_raw, 5)); std::shared_ptr months; ARROW_ASSIGN_OR_RAISE(months, int8builder.Finish()); arrow::Int16Builder int16builder; int16_t years_raw[5] = {1990, 2000, 1995, 2000, 1995}; ARROW_RETURN_NOT_OK(int16builder.AppendValues(years_raw, 5)); std::shared_ptr years; ARROW_ASSIGN_OR_RAISE(years, int16builder.Finish()); // Get a vector of our Arrays std::vector columns = {days, months, years}; // Make a schema to initialize the Table with std::shared_ptr field_day, field_month, field_year; std::shared_ptr schema; field_day = arrow::field("Day", arrow::int8()); field_month = arrow::field("Month", arrow::int8()); field_year = arrow::field("Year", arrow::int16()); schema = arrow::schema({field_day, field_month, field_year}); // With the schema and data, create a Table std::shared_ptr table; table = arrow::Table::Make(schema, columns);
以上代码是创建了一张表的数据结构,存储了三个字段,分别是day,Month,Year写文件 // Write out test files in IPC, CSV, and Parquet for the example to use. std::shared_ptr outfile; ARROW_ASSIGN_OR_RAISE(outfile, arrow::io::FileOutputStream::Open("test_in.arrow")); ARROW_ASSIGN_OR_RAISE(std::shared_ptr ipc_writer, arrow::ipc::MakeFileWriter(outfile, schema)); ARROW_RETURN_NOT_OK(ipc_writer->WriteTable(*table)); ARROW_RETURN_NOT_OK(ipc_writer->Close()); ARROW_ASSIGN_OR_RAISE(outfile, arrow::io::FileOutputStream::Open("test_in.csv")); ARROW_ASSIGN_OR_RAISE(auto csv_writer, arrow::csv::MakeCSVWriter(outfile, table->schema())); ARROW_RETURN_NOT_OK(csv_writer->WriteTable(*table)); ARROW_RETURN_NOT_OK(csv_writer->Close()); ARROW_ASSIGN_OR_RAISE(outfile, arrow::io::FileOutputStream::Open("test_in.parquet")); PARQUET_THROW_NOT_OK( parquet::arrow::WriteTable(*table, arrow::default_memory_pool(), outfile, 5)); 。
以上代码将数据分别以IPC格式,CSV格式和parquet格式写入到文件中,其中,IPC格式是arrow设计的一种数据格式,IPC全称是Serialization and Interprocess Communication,是一种进程间可以高效通讯的序列化格式。
读文件读IPC格式的文件 // (Doc section: ReadableFile Definition) // First, we have to set up a ReadableFile object, which just lets us point our // readers to the right data on disk. Well be reusing this object, and rebinding // it to multiple files throughout the example. std::shared_ptr infile; // (Doc section: ReadableFile Definition) // (Doc section: Arrow ReadableFile Open) // Get "test_in.arrow" into our file pointer ARROW_ASSIGN_OR_RAISE(infile, arrow::io::ReadableFile::Open( "test_in.arrow", arrow::default_memory_pool())); // (Doc section: Arrow ReadableFile Open) // (Doc section: Arrow Read Open) // Open up the file with the IPC features of the library, gives us a reader object. ARROW_ASSIGN_OR_RAISE(auto ipc_reader, arrow::ipc::RecordBatchFileReader::Open(infile)); // (Doc section: Arrow Read Open) // (Doc section: Arrow Read) // Using the reader, we can read Record Batches. Note that this is specific to IPC; // for other formats, we focus on Tables, but here, RecordBatches are used. std::shared_ptr rbatch; ARROW_ASSIGN_OR_RAISE(rbatch, ipc_reader->ReadRecordBatch(0)); // (Doc section: Arrow Read)
读CSV格式的文件 // (Doc section: CSV Read Open) // Bind our input file to "test_in.csv" ARROW_ASSIGN_OR_RAISE(infile, arrow::io::ReadableFile::Open("test_in.csv")); // (Doc section: CSV Read Open) // (Doc section: CSV Table Declare) std::shared_ptr csv_table; // (Doc section: CSV Table Declare) // (Doc section: CSV Reader Make) // The CSV reader has several objects for various options. For now, well use defaults. ARROW_ASSIGN_OR_RAISE( auto csv_reader, arrow::csv::TableReader::Make( arrow::io::default_io_context(), infile, arrow::csv::ReadOptions::Defaults(), arrow::csv::ParseOptions::Defaults(), arrow::csv::ConvertOptions::Defaults())); // (Doc section: CSV Reader Make) // (Doc section: CSV Read) // Read the table. ARROW_ASSIGN_OR_RAISE(csv_table, csv_reader->Read()) // (Doc section: CSV Read)
数据处理模块求和 arrow::Datum sum; // (Doc section: Sum Datum Declaration) // (Doc section: Sum Call) // Here, we can use arrow::compute::Sum. This is a convenience function, and the next // computation wont be so simple. However, using these where possible helps // readability. ARROW_ASSIGN_OR_RAISE(sum, arrow::compute::Sum({table->GetColumnByName("A")}));
支持的运算种类还包括加减乘除,位运算,对数,四舍五入,三角函数,比较,逻辑运算,String的大小写等运算,String padding,日期计算,向量计算等,详见:https://arrow.apache.org/docs/c
pp/compute.html#element-wise-scalar-functionsDataSetdataset是Arrow的一种使用方,与mysql的分区表类似,可以将数据按照某个分区键,存储在不同的模块中:
auto write_scanner_builder = arrow::dataset::ScannerBuilder::FromRecordBatchReader(write_dataset); ARROW_ASSIGN_OR_RAISE(auto write_scanner, write_scanner_builder->Finish()) // (Doc section: WriteScanner) // (Doc section: Partition Schema) // The partition schema determines which fields are used as keys for partitioning. auto partition_schema = arrow::schema({arrow::field("a", arrow::utf8())}); // (Doc section: Partition Schema) // (Doc section: Partition Create) // Well use Hive-style partitioning, which creates directories with "key=value" // pairs. auto partitioning = std::make_shared(partition_schema); // (Doc section: Partition Create) // (Doc section: Write Format) // Now, we declare well be writing Parquet files. auto write_format = std::make_shared(); // (Doc section: Write Format) // (Doc section: Write Options) // This time, we make Options for writing, but do much more configuration. arrow::dataset::FileSystemDatasetWriteOptions write_options; // Defaults to start. write_options.file_write_options = write_format->DefaultWriteOptions(); // (Doc section: Write Options) // (Doc section: Options FS) // Use the filesystem we already have. write_options.filesystem = fs; // (Doc section: Options FS) // (Doc section: Options Target) // Write to the folder "write_dataset" in current directory. write_options.base_dir = "write_dataset"; // (Doc section: Options Target) // (Doc section: Options Partitioning) // Use the partitioning declared above. write_options.partitioning = partitioning; // (Doc section: Options Partitioning) // (Doc section: Options Name Template) // Define what the name for the files making up the dataset will be. write_options.basename_template = "part{i}.parquet"; // (Doc section: Options Name Template) // (Doc section: Options File Behavior) // Set behavior to overwrite existing data -- specifically, this lets this example // be run more than once, and allows whatever code you have to overwrite whats there. write_options.existing_data_behavior = arrow::dataset::ExistingDataBehavior::kOverwriteOrIgnore; // (Doc section: Options File Behavior) // (Doc section: Write Dataset) // Write to disk! ARROW_RETURN_NOT_OK( arrow::dataset::FileSystemDataset::Write(write_options, write_scanner));
这个是按照字段a,将数据存储到不同的文件中,执行后的数据结构如下:
参考:DBMS Musings: An analysis of the strengths and weaknesses of Apache ArrowDremio blog: The Origin & History of Apache Arrow
ACM: Apache Arrow and the Future of Data Frames, slidesApache Arrow: official docs, committers
以上就是关于《Apache Arrow_apache日志存储路径》的全部内容,本文网址:https://www.7ca.cn/baike/10152.shtml,如对您有帮助可以分享给好友,谢谢。