【爬虫案例】用Python爬取百度热搜榜数据!-python百度爬虫
2023-04-16 00:26:35
一、爬取目标
本次爬取的目标是:百度热搜榜:百度热搜

分别爬取每条热搜的:
热搜标题、热搜排名、热搜指数、描述、链接地址。
下面,对页面进行分析。
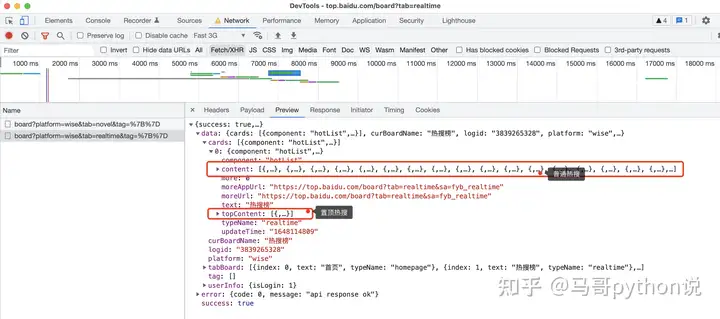
经过分析,此页面有XHR链接,可以针对接口进行爬取。
打开Chrome浏览器,按F12进入开发者模式,依次点击:
点击Network,选择网络点击XHR,选择XHR请求选择目标链接地址点击Preview,选择预览查看返回数据操作过程,如下图所示:

二、编写爬虫代码
首先,导入需要用到的库:
import requests # 发送请求
import pandas as pd # 存入excel数据
定义一个百度热搜榜接口地址:
# 百度热搜榜地址
url = https://top.baidu.com/api/board?platform=wise&tab=realtime
构造一个请求头,伪装爬虫:
# 构造请求头
header = {
User-Agent: Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36,
Host: top.baidu.com,
Accept: application/json, text/plain, */*,
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,
Accept-Encoding: gzip, deflate, br,
Referer: https://top.baidu.com/board?tab=novel,
}
向百度页面发送requests请求:
# 发送请求
r = requests.get(url, header)
返回的数据是json格式的,直接用r.json()接收:
# 用json格式接收请求数据
json_data = r.json()
这里,需要注意的是,页面上有2种热搜:
百度热搜榜最上面一条是置顶热搜,下面从1到30是普通热搜,接口返回的数据也是区分开的:
所以,爬虫代码需要分开处理逻辑:
置顶热搜:
# 爬取置顶热搜
top_content_list = json_data[data][cards][0][topContent]
普通热搜:
# 爬取普通热搜
content_list = json_data[data][cards][0][content]
然后再分别进行json解析,对应的字段(标题、排名、热搜指数、描述、链接地址)。
最后,保存结果数据到excel即可。
df = pd.DataFrame( # 拼装爬取到的数据为DataFrame
{
热搜标题: title_list,
热搜排名: order_list,
热搜指数: score_list,
描述: desc_list,
链接地址: url_list
}
)
df.to_excel(百度热搜榜.xlsx, index=False) # 保存结果数据
最后,查看一下爬取到的数据:

一共31条数据(1条置顶热搜+30条普通热搜)。
每条数据包含:热搜标题、热搜排名、热搜指数、描述、链接地址。
三、同步视频讲解
【Python爬虫案例】3分钟讲解用python爬取百度热搜榜数据!1820 播放 · 3 赞同视频
四、获取完整源码
爱学习的小伙伴,本案例的python爬虫源码及结果数据,我已打包好,并上传至微信公众号"老男孩的平凡之路",后台回复"爬百度热搜"获取,点链接直达↓
【爬虫案例】用Python爬取百度热搜榜数据!mp.weixin.qq.com/s?__biz=MzU5MjQ2MzI0Nw==&mid=2247484458&idx=1&sn=df7f12348a594ef6cf0a1bd59d44e757&chksm=fe1e10cac96999dc5bc86f895a9359db06174aed97240a971f9cd313a2f69cf486b1e8b326c2&payreadticket=HNuezve1RAR-0J__bnhyL65x8v7xDA4kzeUWPVtHjLwgg8H4_jURgicAyJJrwIu-cVeEgZI#rd
推荐阅读:马哥python说:【经典爬虫案例】用Python爬取微博热搜榜
以上就是关于《【爬虫案例】用Python爬取百度热搜榜数据!-python百度爬虫》的全部内容,本文网址:https://www.7ca.cn/baike/17003.shtml,如对您有帮助可以分享给好友,谢谢。
声明