R语言SVM支持向量机、文本挖掘新闻语料情感情绪分类和词云可视化
原标题:R语言SVM支持向量机、文本挖掘新闻语料情感情绪分类和词云可视化
全文链接:http://tecdat.cn/?p=32032 原文出处:拓端数据部落公众号支持向量机(SVM)是一种机器学习方法,基于结构风险最小化原则,即通过少量样本数据,得到尽可能多的样本数据。支持向量机对线性问题进行处理,能解决非线性分类问题。本文介绍了R语言中的 SVM工具箱及其支持向量机(SVM)方法,并将其应用于文本情感分析领域,结果表明,该方法是有效的。在此基础上,对文本挖掘新闻语料进行情感分类和词云可视化,从视觉上对文本进行情感分析。
语料是从yahoo Qimo上爬的新闻语料,一共49000篇,每篇包含题目、新闻内容、评论、读者投票结果(投票选择依次为:实用,感人、开心、超扯、无聊、害怕、难过、火大)以及总投票个数。
数据概览
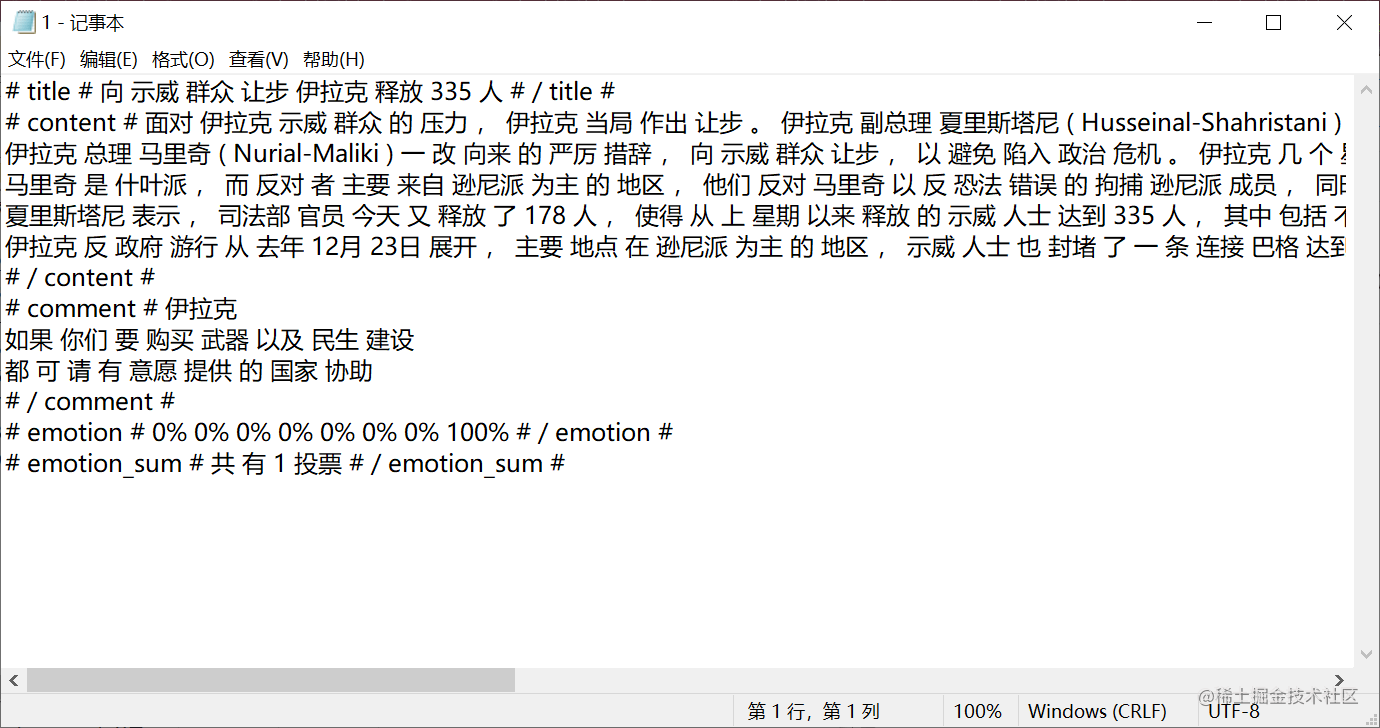
对其分词提取关键词
library(jiebaR)
cutter = worker(type = "keywords", topn = 10)
words = "1.txt"

dir = list.files(".")
获取分类号xx<-readLines(dir[i],encoding = "UTF-8")
## Warning in readLines(dir[i], encoding = "UTF-8"): 读1.txt时最后一行未遂
# xx<-readLines("2.txt",encoding = "UTF-8")
class=strsplit(xx[length(xx)-1],split="#")[[1]][3]
词性分类for(i in 1:10){
cutter = worker(type = "keywords", topn = 10)
绘制词汇图mycolors <- brewer.pal(8,"Dark2")#设置一个颜色系:
wordcloud(cutter_words,as.numeriter_words)),random.order=FAL

ntrain <- round(n*0.8) # 训练集
tindex <- sample(n,ntrain) # 筛选测试集样本
xtrain<-textdata[tindex,]
xtest<-textdata[-tindex,]
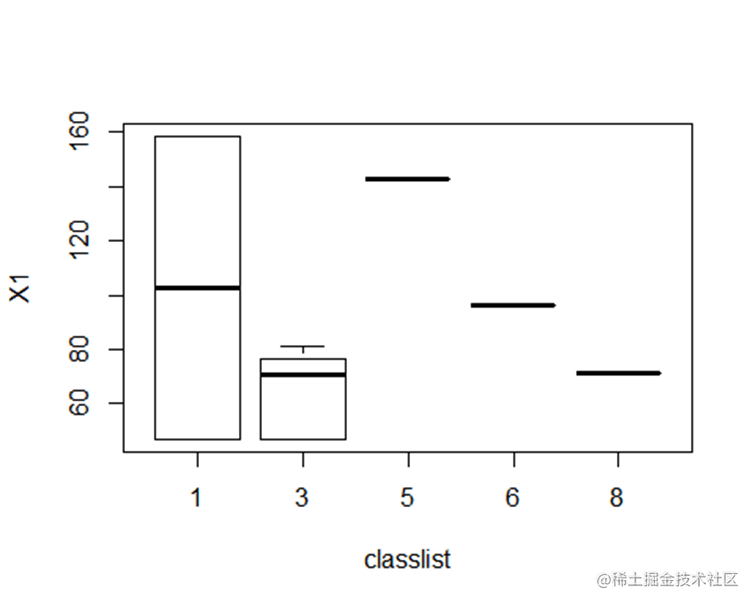
#可视化
plot(textdata[,c("classlist","X1")] ,pch=ifelse(istrain==1,1,2))
现在我们在训练集上使用来训练线性SVM
svm(classlist ~ . , textdata)

predictedY <- predict(model, textdata)
预测的数据


最受欢迎的见解
1.Python主题建模LDA模型、t-SNE 降维聚类、词云可视化文本挖掘新闻组
2.R语言文本挖掘、情感分析和可视化哈利波特小说文本数据
3.r语言文本挖掘tf-idf主题建模,情感分析n-gram建模研究
4.游记数据感知旅游目的地形象
5.疫情下的新闻数据观察
6.python主题lda建模和t-sne可视化
7.r语言中对文本数据进行主题模型topic-modeling分析
8.主题模型:数据聆听人民网留言板的那些“网事”
9.python爬虫进行web抓取lda主题语义数据分析返回搜狐,查看更多
责任编辑:
以上就是关于《R语言SVM支持向量机、文本挖掘新闻语料情感情绪分类和词云可视化》的全部内容,本文网址:https://www.7ca.cn/baike/26930.shtml,如对您有帮助可以分享给好友,谢谢。