科普 | 深度学习算法三大类:CNN,RNN和GAN(cnn的处理过程)
人工智能在近几年处于爆发期,越来越多意想不到的应用被提出,说明AI还有非常多的发展空间相同的数据型态,利用不同的方法分析,就可以解决不同的课题例如目前已相当纯熟的人脸识别技术,在国防应用可以进行安保工作;企业可做员工门禁系统;可结合性别、年龄辨识让卖场进行市调分析,或结合追踪技术进行人流分析等。
本篇接下来要针对深度学习方法的数据类型或算法,介绍AI常见的应用以算法区分深度学习应用,算法类别可分成三大类:常用于影像数据进行分析处理的卷积神经网络(简称CNN)文本分析或自然语言处理的递归神经网络(简称RNN)。
常用于数据生成或非监督式学习应用的生成对抗网络(简称GAN)

CNN因为应用种类多样,本篇会以算法类别细分,CNN主要应用可分为图像分类(image classification)、目标检测(object detection)及语义分割(semantic segmentation)。
下图可一目了然三种不同方法的应用方式

图片来源于网络1、图像分类 (Classification)顾名思义就是将图像进行类别筛选,通过深度学习方法识别图片属于哪种分类类别,其主要重点在于一张图像只包含一种分类类别,即使该影像内容可能有多个目标,所以单纯图像分类的应用并不普遍。
不过由于单一目标识别对深度学习算法来说是正确率最高的,所以实际上很多应用会先通过目标检测方法找到该目标,再缩小撷取影像范围进行图像分类所以只要是目标检测可应用的范围,通常也会使用图像分类方法图像分类也是众多用来测试算法基准的方法之一,常使用由ImageNet举办的大规模视觉识别挑战赛(ILSVRC)中提供的公开图像数据进行算法测试。
图像分类属于CNN的基础,其相关算法也是最易于理解,故初学者应该都先以图像分类做为跨入深度学习分析的起步使用图像分类进行识别,通常输入为一张图像,而输出为一个文字类别2、目标检测 (Object Detection)
一张图像内可有一或多个目标物,目标物也可以是属于不同类别算法主要能达到两种目的:找到目标坐标及识别目标类别简单来说,就是除了需要知道目标是什么,还需要知道它在哪个位置目标检测应用非常普遍,包含文章开头提到的人脸识别相关技术结合应用,或是制造业方面的瑕疵检测,甚至医院用于X光、超音波进行特定身体部位的病况检测等。
目标识别的基础可想象为在图像分类上增加标示位置的功能,故学习上也不离图像分类的基础不过目标检测所标示的坐标通常为矩形或方形,仅知道目标所在位置,并无法针对目标的边缘进行描绘,所以常用见的应用通常会以「知道目标位置即可」作为目标。
最常见的算法为YOLO及R-CNN其中YOLO因算法特性具有较快的识别速度,目前已来到v3版本R-CNN针对目标位置搜寻及辨识算法和YOLO稍有不同,虽然速度稍较YOLO慢,但正确率稍高于YOLO使用目标检测进行识别,通常输入为一张图像,而输出为一个或数个文字类别和一组或多组坐标。
3、语义分割 (Semantic Segmentation) 算法会针对一张图像中的每个像素进行识别,也就是说不同于目标检测,语义分割可以正确区别各目标的边界像素,简单来说,语义分割就是像素级别的图像分类,针对每个像素进行分类。
当然这类应用的模型就会需要较强大的GPU和花较多时间进行训练常见应用类似目标检测,但会使用在对于图像识别有较高精细度,如需要描绘出目标边界的应用例如制造业上的瑕疵检测,针对不规则形状的大小瑕疵,都可以正确描绘。
医学上常用于分辨病理切片上的病变细胞,或是透过MRI、X光或超音波描绘出病变的区块及类别算法如U-Net或是Mask R-CNN都是常见的实作方法使用语义分割进行识别,通常输入为一张图像,而输出也为一张等大小的图像,但图像中会以不同色调描绘不同类别的像素。
RNN有别于CNN,RNN的特色在于可处理图像或数值数据,并且由于网络本身具有记忆能力,可学习具有前后相关的数据类型例如进行语言翻译或文本翻译,一个句子中的前后词汇通常会有一定的关系,但CNN网络无法学习到这层关系,而RNN因具有内存,所以性能会比较好。
因为可以通过RNN进行文字理解,其他应用如输入一张图像,但是输出为一段关于图像叙述的句子(如下图)

图片来源于网络RNN虽然解决了CNN无法处理的问题,但其本身仍然有些缺点,所以现在很多RNN的变形网络,其中最常被使用的网络之一为长短记忆网络(Long Short-Term Network,简称LSTM)。
这类网络的输入数据不限于是图像或文字,解决的问题也不限于翻译或文字理解数值相关数据也同样可以使用LSTM进行分析,例如工厂机器预测性维修应用,可透过LSTM分析机台震动讯号,预测机器是否故障在医学方面,LSTM可协助解读数以千计的文献,并找出特定癌症的相关信息,例如肿瘤部位、肿瘤大小、期数,甚至治疗方针或存活率等等,透过文字理解进行解析。
也可结合图像识别提供病灶关键词,以协助医生撰写病理报告GAN除了深度学习外,有一种新兴的网络称为强化学习(Reinforcement Learning),其中一种很具有特色的网络为生成式对抗网络(GAN)。
GAN的应用相关论文成长幅度相当大(如下图)。
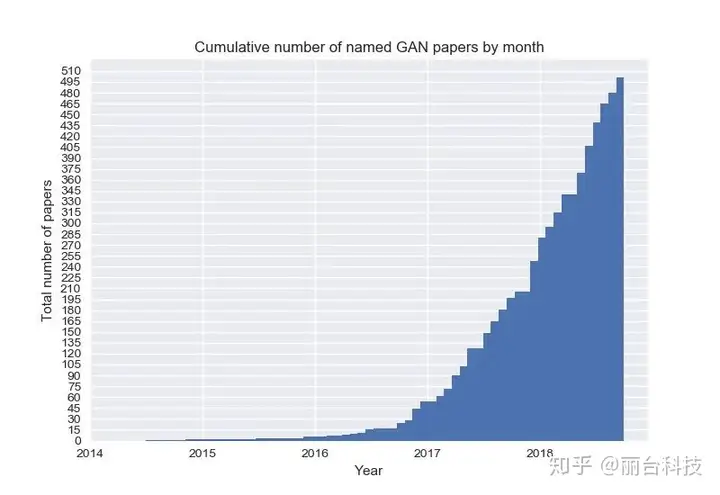
这里不详述GAN的理论或实作方式,而是探讨GAN实际应用的场域深度学习领域最需要的是数据,但往往不是所有应用都可以收集到大量数据,并且数据也需要人工进行标注,这是非常消耗时间及人力成本图像数据可以通过旋转、裁切或改变明暗等方式增加数据量,但如果数据还是不够呢?目前有相当多领域透过GAN方法生成非常近似原始数据的数据,例如3D-GAN就是可以生成高质量3D对象。
当然,比较有趣的应用例如人脸置换或表情置换(如下图)

图片来源于网络另外,SRGAN (Super Resolution GAN)可用于提高原始图像的分辨率,将作为低分辨率影像输入进GAN模型,并生成较高画质的影像(如下图)这样的技术可整合至专业绘图软件中,协助设计师更有效率完成设计工作。

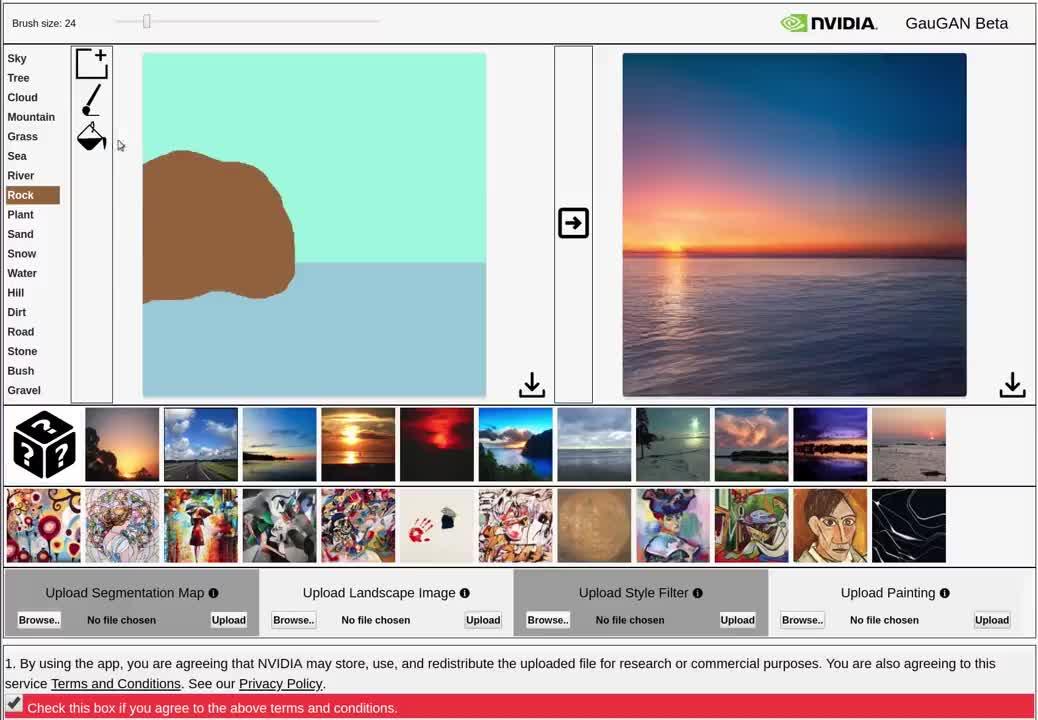
图片来源于网络NVIDIA也有提供一些基于GAN的平台的应用,包含透过GauGAN网络,仅需绘制简单的线条,即可完成漂亮的画作,并且还能随意修改场景的风格(如下图)。

GauGAN130 播放 · 0 赞同视频
以上就是关于《科普 | 深度学习算法三大类:CNN,RNN和GAN(cnn的处理过程)》的全部内容,本文网址:https://www.7ca.cn/baike/3794.shtml,如对您有帮助可以分享给好友,谢谢。