AIBigKaldi(十六)| Kaldi的quick模型(源码解析)-kaldi模型怎么调用
本文来自公众号“AI大道理”。
这里既有AI,又有生活大道理,无数渺小的思考填满了一生。
单音素模型词错误率为50.58%,三音子模型词错误率为36.03%,lda-mllt模型词错误率为32.12%,说话人自适应模型词错误率为28.41%。
可见说话人自适应模型识别率继续有了一定的提高。
能否继续优化模型?又要从哪些方面入手进行优化呢?
quick模型将继续改善现有模型。
以kaldi的thchs30为例。

总过程

8 quick模型
实现思想:
对于当前模型的每个状态(构建完树后),它把旧模型中与其相近的状态直接克隆过来,评判是否相近的标准就是看它们树统计量的重叠数目相似度。
8.1 train_quick.sh
功能:
在现有特征之上训练模型(不进行任何类型的特征空间学习)。
该脚本从先前系统的模型初始化模型(即GMMs)。
也就是说:对于当前模型中的每个状态(在树构建之后),它选择旧模型中的closes状态,根据树stats中计数的重叠来判断相似度。
过程之道:
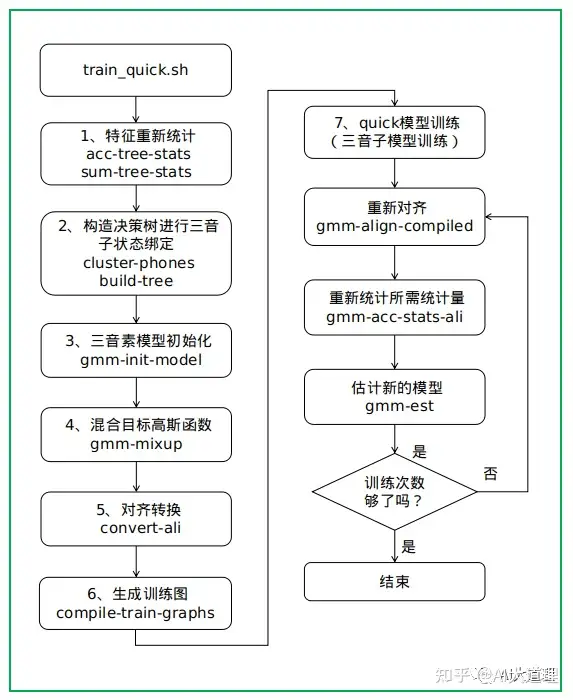
训练过程:

训练完毕。
训练好的quick模型:

训练好的sat模型:
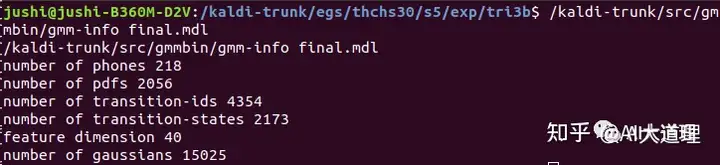
高斯数量明显增多。
8.2 thchs-30_decode.sh
功能:
quick模型解码识别。

quick模型部分解码识别(词级别):

真正结果(标签词):

单音素模型词错误率为50.58%,三音子模型词错误率为36.03%,lda-mllt模型词错误率为32.12%,说话人自适应模型词错误率为28.41%。
quick模型词错误率为27.94%。
可见quick模型识别率继续提高,虽然提高的幅度有限。

quick模型部分解码识别(音素级别):

真正结果(标签音素):

单音素模型音素错误率为32.43%,三音素模型音素错误率为20.44%,lda-mllt模型音素错误率为17.06%,说话人自适应模型音素错误率为14.98%。
quick模型音素错误率为13.53%。
8.3 align_fmllr.sh
功能:
对齐,为接下来的模型优化做准备。
对齐结果:

总结
单音素模型词错误率为50.58%,三音子模型词错误率为36.03%,lda-mllt模型词错误率为32.12%,说话人自适应模型词错误率为28.41%,quick模型词错误率为27.94%。
可见quick模型识别率继续有了一定的提高。
到这里经典语音识别GMM-HMM框架基本上就结束了。
通过一系列的优化,GMM-HMM模型在大词汇量语音识别中识别率大概可以达到七成左右。
但终究是有瓶颈的。
能否继续优化模型?又要从哪些方面入手进行优化呢?
火热的深度学习进入了我们的视野。
第一个被取代的就是对发射概率建模的GMM。
至此DNN-HMM拉开帷幕。

——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————
—————————————————————
|
以上就是关于《AIBigKaldi(十六)| Kaldi的quick模型(源码解析)-kaldi模型怎么调用》的全部内容,本文网址:https://www.7ca.cn/baike/43764.shtml,如对您有帮助可以分享给好友,谢谢。