ClickHouse简介
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。ClickHouse最初是一款名为Yandex.Metrica的产品,主要用于WEB流量分析。ClickHouse的全称是Click Stream,Data WareHouse,简称ClickHouse。
ClickHouse非常适用于商业智能领域,除此之外,它也能够被广泛应用于广告流量、Web、App流量、电信、金融、电子商务、信息安全、网络游戏、物联网等众多其他领域。ClickHouse具有以下特点:
支持完备的SQL操作列式存储与数据压缩向量化执行引擎关系型模型(与传统数据库类似)丰富的表引擎并行处理在线查询数据分片
ClickHouse作为一款高性能OLAP数据库,存在以下不足。不支持事务。不擅长根据主键按行粒度进行查询(虽然支持),故不应该把ClickHouse当作Key-Value数据库使用。不擅长按行删除数据(虽然支持)
单机安装
下载RPM包
本文安装方式选择的是离线安装,可以在下面的链接中下载对应的rpm包,也可以直接百度云下载
-- rpm包地址
https://packagecloud.io/Altinity/clickhouse
-- 百度云地址
链接:https://pan.baidu.com/s/1pFR66SzLvPYMfcpuPJww5A
提取码:gh5a
在我们安装的软件中包含这些包:
clickhouse-client 包,包含 clickhouse-client 应用程序,它是交互式ClickHouse控制台客户端。clickhouse-common 包,包含一个ClickHouse可执行文件。clickhouse-server 包,包含要作为服务端运行的ClickHouse配置文件。
总共包含四个RPM包,
clickhouse-client-19.17.4.11-1.el7.x86_64.rpm
clickhouse-common-static-19.17.4.11-1.el7.x86_64.rpm
clickhouse-server-19.17.4.11-1.el7.x86_64.rpm
clickhouse-server-common-19.17.4.11-1.el7.x86_64.rpm
尖叫提示:如果安装过程中,报错:依赖检测失败,表示缺少依赖包
可以先手动安装libicu-50.2-4.el7_7.x86_64.rpm依赖包
关闭防火墙
## 查看防火墙状态。
systemctl status firewalld
## 临时关闭防火墙命令。重启电脑后,防火墙自动起来。
systemctl stop firewalld
## 永久关闭防火墙命令。重启后,防火墙不会自动启动。
systemctl disable firewalld
系统要求
ClickHouse可以在任何具有x86_64,AArch64或PowerPC64LE CPU架构的Linux,FreeBSD或Mac OS X上运行。虽然预构建的二进制文件通常是为x86 _64编译并利用SSE 4.2指令集,但除非另有说明,否则使用支持它的CPU将成为额外的系统要求。这是检查当前CPU是否支持SSE 4.2的命令:
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
SSE 4.2 supported
要在不支持SSE 4.2或具有AArch64或PowerPC64LE体系结构的处理器上运行ClickHouse,应该通过源构建ClickHouse进行适当的配置调整。
安装RPM包
## 将rpm包上传至/opt/software目录下
## 执行如下命令进行安装
[root@cdh06 software]# rpm -ivh *.rpm
错误:依赖检测失败:
libicudata.so.50()(64bit) 被 clickhouse-common-static-19.17.4.11-1.el7.x86_64 需要
libicui18n.so.50()(64bit) 被 clickhouse-common-static-19.17.4.11-1.el7.x86_64 需要
libicuuc.so.50()(64bit) 被 clickhouse-common-static-19.17.4.11-1.el7.x86_64 需要
libicudata.so.50()(64bit) 被 clickhouse-server-19.17.4.11-1.el7.x86_64 需要
libicui18n.so.50()(64bit) 被 clickhouse-server-19.17.4.11-1.el7.x86_64 需要
libicuuc.so.50()(64bit) 被 clickhouse-server-19.17.4.11-1.el7.x86_64 需要
## 上面安装报错,缺少相应的依赖包,
## 需要下载相对应的依赖包
## 下载libicu-50.2-4.el7_7.x86_64.rpm进行安装即可
查看安装信息
目录结构
/etc/clickhouse-server:服务端的配置文件目录,包括全局配置config.xml和用户配置users.xml等。/etc/clickhouse-client:客户端配置,包括conf.d文件夹和config.xml文件。/var/lib/clickhouse:默认的数据存储目录(通常会修改默认路径配置,将数据保存到大容量磁盘挂载的路径)。/var/log/clickhouse-server:默认保存日志的目录(通常会修改路径配置,将日志保存到大容量磁盘挂载的路径)。
配置文件
/etc/security/limits.d/clickhouse.conf:文件句柄数量的配置
[root@cdh06 clickhouse-server]# cat /etc/security/limits.d/clickhouse.conf
clickhouse soft nofile 262144
clickhouse hard nofile 262144
该配置也可以通过config.xml的max_open_files修改
<!-- Set limit on number of open files (default: maximum). This setting makes sense on Mac OS X because getrlimit() fails to retrieve correct maximum value. -->
<!-- <max_open_files>262144</max_open_files> -->
/etc/cron.d/clickhouse-server:cron:定时任务配置,用于恢复因异常原因中断的ClickHouse服务进程,其默认的配置如下。
[root@cdh06 cron.d]# cat /etc/cron.d/clickhouse-server
#*/10 * * * * root (which service > /dev/null 2>&1 && (service clickhouse-server condstart ||:)) || /etc/init.d/clickhouse-server condstart > /dev/null 2>&1
可执行文件
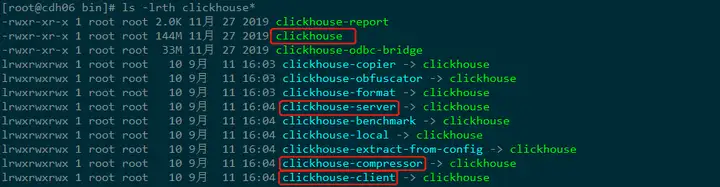
最后是一组在/usr/bin路径下的可执行文件:
clickhouse:主程序的可执行文件。clickhouse-client:一个指向ClickHouse可执行文件的软链接,供客户端连接使用。clickhouse-server:一个指向ClickHouse可执行文件的软链接,供服务端启动使用。clickhouse-compressor:内置提供的压缩工具,可用于数据的正压反解。
启动/关闭服务
## 启动服务
[root@cdh06 ~]# service clickhouse-server start
Start clickhouse-server service: Path to data directory in /etc/clickhouse-server/config.xml: /var/lib/clickhouse/
DONE
## 关闭服务
[root@cdh06 ~]# service clickhouse-server stop
客户端连接
[root@cdh06 ~]# clickhouse-client
ClickHouse client version 19.17.4.11.
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 19.17.4 revision 54428.
cdh06 :) show databases;
SHOW DATABASES
┌─name────┐
│ default │
│ system │
└─────────┘
2 rows in set. Elapsed: 0.004 sec.
基本操作
创建数据库
语法
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster] [ENGINE = engine(...)]
例子
CREATE DATABASE IF NOT EXISTS tutorial
默认情况下,ClickHouse使用的是原生的数据库引擎Ordinary(在此数据库下可以使用任意类型的表引擎,在绝大多数情况下都只需使用默认的数据库引擎)。当然也可以使用Lazy引擎和MySQL引擎,比如使用MySQL引擎,可以直接在ClickHouse中操作MySQL对应数据库中的表。假设MySQL中存在一个名为clickhouse的数据库,可以使用下面的方式连接MySQL数据库。
-- --------------------------语法-----------------------------------
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL(host:port, [database | database], user, password)
-- --------------------------示例------------------------------------
CREATE DATABASE mysql_db ENGINE = MySQL(192.168.200.241:3306, clickhouse, root, 123qwe);
-- ---------------------------操作-----------------------------------
cdh06 :) use mysql_db;
cdh06 :) show tables;
SHOW TABLES
┌─name─┐
│ test │
└──────┘
1 rows in set. Elapsed: 0.005 sec.
cdh06 :) select * from test;
SELECT *
FROM test
┌─id─┬─name──┐
│ 1 │ tom │
│ 2 │ jack │
│ 3 │ lihua │
└────┴───────┘
3 rows in set. Elapsed: 0.047 sec.
创建表
语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [compression_codec] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [compression_codec] [TTL expr2],
...
) ENGINE = engine
示例
-- 注意首字母大写
-- 建表
create table test(
id Int32,
name String
) engine=Memory;
上面命令创建了一张内存表,即使用Memory引擎。表引擎决定了数据表的特性,也决定了数据将会被如何存储及加载。Memory引擎是ClickHouse最简单的表引擎,数据只会被保存在内存中,在服务重启时数据会丢失。
集群安装
安装步骤
上面介绍了单机安装的基本步骤和ClickHouse客户端的基本使用。接下来将介绍集群的安装方式。ClickHouse集群安装非常简单,首先重复上面步骤,分别在其他机器上安装ClickHouse,然后再分别配置一下/etc/clickhouse-server/config.xml和/etc/metrika.xml两个文件即可。值得注意的是,ClickHouse集群的依赖于Zookeeper,所以要保证先安装好Zookeeper集群,zk集群的安装步骤非常简单,本文不会涉及。本文演示三个节点的ClickHouse集群安装,具体步骤如下:
首先,重复单机安装的步骤,分别在另外两台机器安装ClickHouse然后,在每台机器上修改**/etc/clickhouse-server/config.xml**文件
0.0.0.0
::
-->
尖叫提示(1):
在禁用了ipv6时,如果使用::配置,会报如下错误
Application: DB::Exception: Listen [::]:8123 failed: Poco::Exception. Code: 1000, e.code() =0, e.displayText() = DNS error: EAI: -9
尖叫提示(2):
ClickHouse默认的tcp端口号是9000,如果存在端口冲突,可以在**/etc/clickhouse-server/config.xml**文件中修改 端口号9001最后在/etc下创建metrika.xml文件,内容如下,下面配置是不包含副本的分片配置,我们还可以为分片配置多个副本
-->
cdh04
9001
cdh05
9001
cdh06
9001
保持一致
-->
cdh02
2181
cdh03
2181
cdh06
2181
需要修改对应主机上的配置-->
01
cdh04
分别在各自的机器上启动clickhouse-server
# service clickhouse-server start
(可选配置)修改**/etc/clickhouse-client/config.xml**文件
由于clickhouse-client默认连接的主机是localhost,默认连接的端口号是9000,由于我们修改了默认的端口号,所以需要修改客户端默认连接的端口号,在该文件里添加如下内容:
9001
当然也可以不用修改,但是记得在使用客户端连接时,加上**--port 9001**参数指明要连接的端口号,否则会报错:
Connecting to localhost:9000 as user default.
Code: 210. DB::NetException: Connection refused (localhost:9000)
基本操作
验证集群
在完成上述配置之后,在各自机器上启动clickhouse-server,并开启clickhouse-clent
// 启动server
# service clickhouse-server start
// 启动客户端,-m参数支持多行输入
# clickhouse-client -m
可以查询系统表验证集群配置是否已被加载:
cdh04 :) select cluster,shard_num,replica_num,host_name,port,user from system.clusters;
接下来再来看一下集群的分片信息(宏变量):分别在各自机器上执行下面命令:
cdh04 :) select * from system.macros;
┌─macro───┬─substitution─┐
│ replica │ cdh04 │
│ shard │ 01 │
└─────────┴──────────────┘
cdh05 :) select * from system.macros;
┌─macro───┬─substitution─┐
│ replica │ cdh05 │
│ shard │ 02 │
└─────────┴──────────────┘
cdh06 :) select * from system.macros;
┌─macro───┬─substitution─┐
│ replica │ cdh06 │
│ shard │ 03 │
└─────────┴──────────────┘
分布式DDL操作
默认情况下,CREATE、DROP、ALTER、RENAME操作仅仅在当前执行该命令的server上生效。在集群环境下,可以使用ON CLUSTER语句,这样就可以在整个集群发挥作用。
比如创建一张分布式表:
CREATE TABLE IF NOT EXISTS user_cluster ON CLUSTER cluster_3shards_1replicas
(
id Int32,
name String
)ENGINE = Distributed(cluster_3shards_1replicas, default, user_local,id);
Distributed表引擎的定义形式如下所示:关于ClickHouse的表引擎,后续文章会做详细解释。
Distributed(cluster_name, database_name, table_name[, sharding_key])
各个参数的含义分别如下:
cluster_name:集群名称,与集群配置中的自定义名称相对应。database_name:数据库名称table_name:表名称sharding_key:可选的,用于分片的key值,在数据写入的过程中,分布式表会依据分片key的规则,将数据分布到各个节点的本地表。尖叫提示:
创建分布式表是读时检查的机制,也就是说对创建分布式表和本地表的顺序并没有强制要求。
同样值得注意的是,在上面的语句中使用了ON CLUSTER分布式DDL,这意味着在集群的每个分片节点上,都会创建一张Distributed表,这样便可以从其中任意一端发起对所有分片的读、写请求。
创建完成上面的分布式表时,在每台机器上查看表,发现每台机器上都存在一张刚刚创建好的表。
接下来就需要创建本地表了,在每台机器上分别创建一张本地表:
CREATE TABLE IF NOT EXISTS user_local
(
id Int32,
name String
)ENGINE = MergeTree()
ORDER BY id
PARTITION BY id
PRIMARY KEY id;
我们先在一台机器上,对user_local表进行插入数据,然后再查询user_cluster表
-- 插入数据
cdh04 :) INSERT INTO user_local VALUES(1,tom),(2,jack);
-- 查询user_cluster表,可见通过user_cluster表可以操作所有的user_local表
cdh04 :) select * from user_cluster;
┌─id─┬─name─┐
│ 2 │ jack │
└────┴──────┘
┌─id─┬─name─┐
│ 1 │ tom │
└────┴──────┘
接下来,我们再向user_cluster中插入一些数据,观察user_local表数据变化,可以发现数据被分散存储到了其他节点上了。
-- 向user_cluster插入数据
cdh04 :) INSERT INTO user_cluster VALUES(3,lilei),(4,lihua);
-- 查看user_cluster数据
cdh04 :) select * from user_cluster;
┌─id─┬─name─┐
│ 2 │ jack │
└────┴──────┘
┌─id─┬─name──┐
│ 3 │ lilei │
└────┴───────┘
┌─id─┬─name─┐
│ 1 │ tom │
└────┴──────┘
┌─id─┬─name──┐
│ 4 │ lihua │
└────┴───────┘
-- 在cdh04上查看user_local
cdh04 :) select * from user_local;
┌─id─┬─name─┐
│ 2 │ jack │
└────┴──────┘
┌─id─┬─name──┐
│ 3 │ lilei │
└────┴───────┘
┌─id─┬─name─┐
│ 1 │ tom │
└────┴──────┘
-- 在cdh05上查看user_local
cdh05 :) select * from user_local;
┌─id─┬─name──┐
│ 4 │ lihua │
└────┴───────┘
总结
本文首先介绍了ClickHouse的基本特点和使用场景,接着阐述了ClickHouse单机版与集群版离线安装步骤,并给出了ClickHouse的简单使用案例。本文是ClickHouse的一个简单入门,在接下来的分享中,会逐步深入探索ClickHouse的世界。