一文讲述LSTM及其变体-lstm的基本结构
2023-08-07 23:11:33
原文连接:Understanding LSTM Networks
一、标准的LSTM
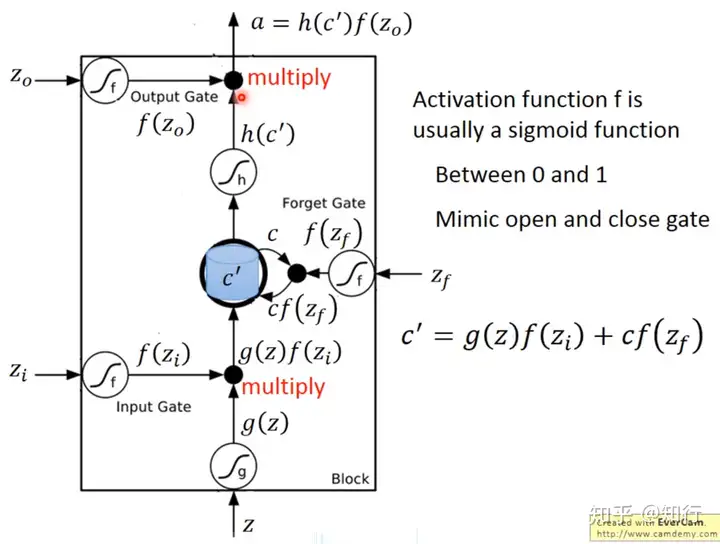
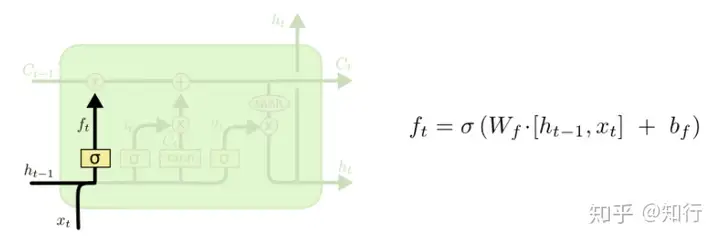
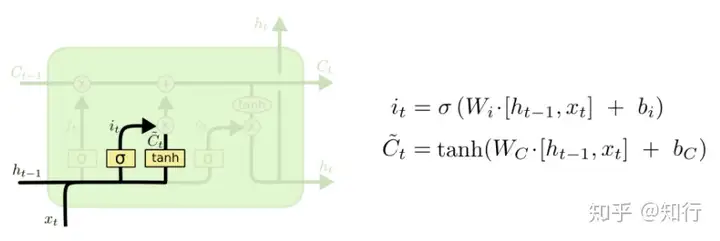
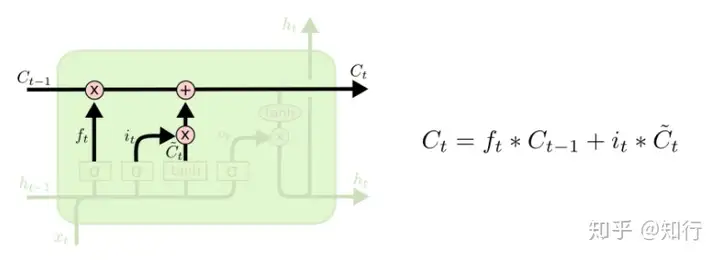
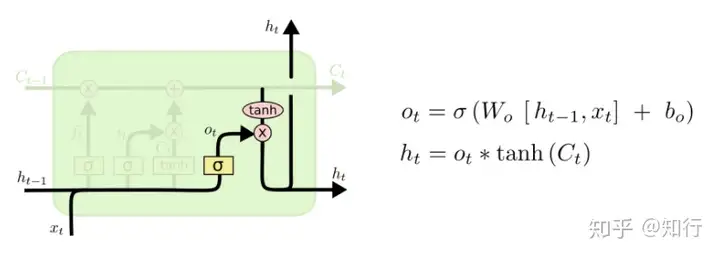
以上4个图就是正常的LSTM的公式。
二、考虑内存
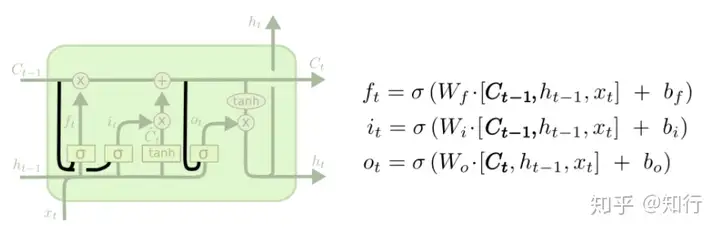
这种LSTM就是遗忘门、输入门考虑了上一时刻的内存值。由于Ct本来就考虑了上一时刻C和此时刻输入,因此用Ct即可。
三、内存与输入
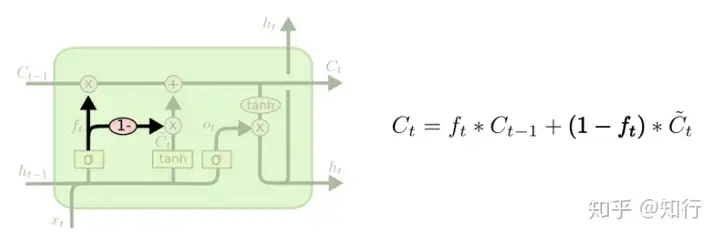
这种LSTM就是上一时刻内存与此时刻输入加权,当 ftf_t 较大,即觉得上一时刻内存值不应该忘记太多时,同时认为此时刻输入也不应该占据太多。
四、GRU
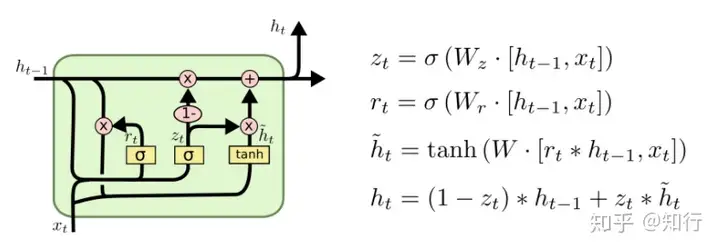
相较于LSTM三个门,GRU只有更新门 ztz_t 和 重置门 rtr_t ,它将输入门和遗忘门结合为一个更新门 ztz_t,参数减少三分之一。相较于LSTM考虑内存C,它是直接考虑上一时刻输出 ht−1h_{t-1} ,而没有了内存的概念,并且没有了bias。其输入也是由上一时刻输出 ht−1h_{t-1} 与此时刻预输出 h~t\tilde{h}_{t} ,通过更新门 ztz_t 加权得到, ztz_t 越大,越偏向与考虑此时的预输出 h~t\tilde{h}_{t} ;反之,则更偏向上一时刻输出 ht−1h_{t-1} 。总的来说,它的理念更加简单直观,没有内存概念,直接考虑上一时刻输出。
当数据量足够充分训练,那用LSTM是更好的;当数据量比较缺乏,更少参数的GRU更能提供更强的泛化能力。
五、为什么LSTM用tanh不用sigmoid?
这个问题网上有解释说,一开始用的其实是sigmoid的变种,但是效果没tanh好,所以用的tanh:
激活函数的选择也不是一成不变的。例如在原始的LSTM中,使用的激活函数是 Sigmoid函数的变种,h(x)=2sigmoid(x)-1,g(x)=4 sigmoid(x)-2,这两个函数的范国分别是[-1,1]和[-2,2]。并且在原始的LSTM中,只有输入门和输出门,没有遗忘门,其中输入经过输入门后是直接与记忆相加的,所以输入门控g(x)的值是0中心的。后来经过大量的研究和实验,人们发现增加遗忘门对LSTM的性能有很大的提升且h(x)使用tanh比2 sigmoid(x)-1要好,所以现代的LSTM采用 Sigmoid和tanh作为激活函数。事实上在门控中,使用 Sigmoid函数是几乎所有现代神经网络模块的共同选择。例如在门控循环单元和注意力机制中,也广泛使用 Sigmoid i函数作为门控的激活函数。以上就是关于《一文讲述LSTM及其变体-lstm的基本结构》的全部内容,本文网址:https://www.7ca.cn/baike/60184.shtml,如对您有帮助可以分享给好友,谢谢。
声明