简单了解一下BERT-了解一下用英语怎么写
一直听闻NLP界有个很厉害的模型BERT但一直不知道到底是怎么回事,till i come across this kernal https://www.kaggle.com/abhinand05/bert-for-humans-tutorial-baseline-version-2
本文没有涉及到代码部分,仅仅是原理介绍。
一些作者提到的Credit
BERT for Dummies step by step tutorial by Michel KanaDemystifying BERT: Groundbreaking NLP Framework by Mohd Sanad Zaki RizviA visual guide to using BERT by Jay AlammarBERT Fine tuning By Chris McCormick and Nick RyanHow to use BERT in Kaggle competitions - Reddit ThreadBERT GitHub repositoryBERT - SOTA NLP model Explained by Rani HorevBERT总体介绍
BERT的全程叫做Bidirectional Encoder Representations for Transformers.是用Wikipedia and BooksCorpus的预料训练出来的深度模型(在具体任务时值需要finetuning就可以) 从架构上来说BERT基本上就是一堆Transformer Encoder stack在一起。Bidirectionality 是区分BERT和其他类似于OpenAI GPT的核心概念。总体介绍完毕,接下来:
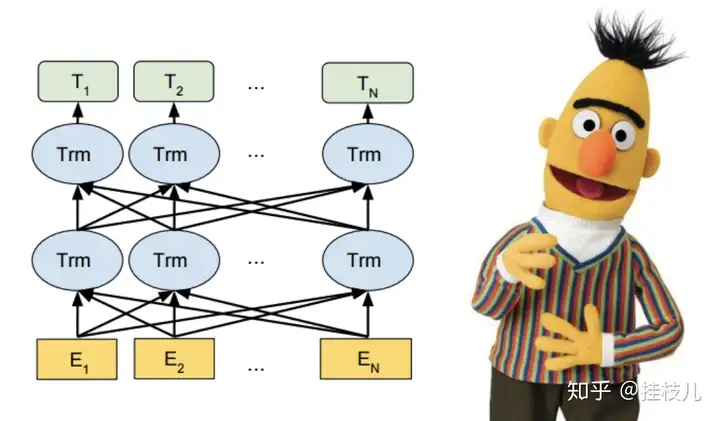
知道BERT的全程容易,但知道Bidirectional Encoder Representations for Transformers每个词分别代表什么不容易,我们接下来一一tackle,但看到这里我们的takeaway应该是:BERT是基于Transformer架构的BERT是基于大量的未标注语料库训练出来的,语料库越大模型越能去pick up哪些潜在的语义链接点,并且能够使得BERT胜任各类NLP任务BERT是深度双向的(Deeply Bidirectional)模型。双向意味着BERT在一条句子中不仅能抓到前向的语义context,他也能抓到后向的语义Context,比如下面这个2个例子如果只考虑token前向的语聊,得到的含义与综合考量前后向的含义是完全不同的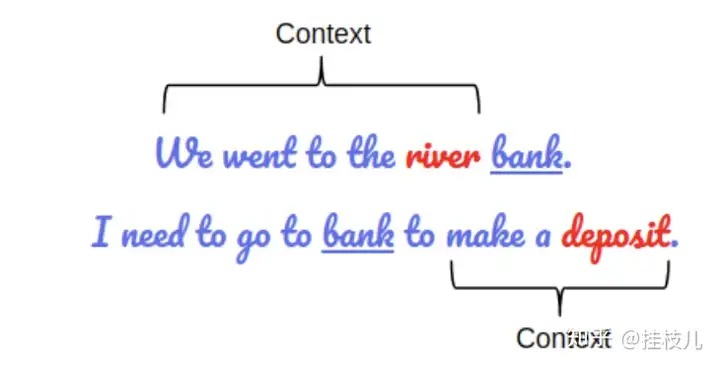
BERT的深入了解
1. BERT的架构
BERT是一个多层双向转换编码架构(Multi-Layer Bidirectional Transformer Encoder).在Paper中有2个模型:
BERT base - 12层(转换Block),12个Attention heads,以及110百万个参数BERT large - 24层,16个Attention heads以及340百万个参数 下图是例子,如果想深入了解Transformers到底是啥,可以看这篇文章:The Illustrated Transformers.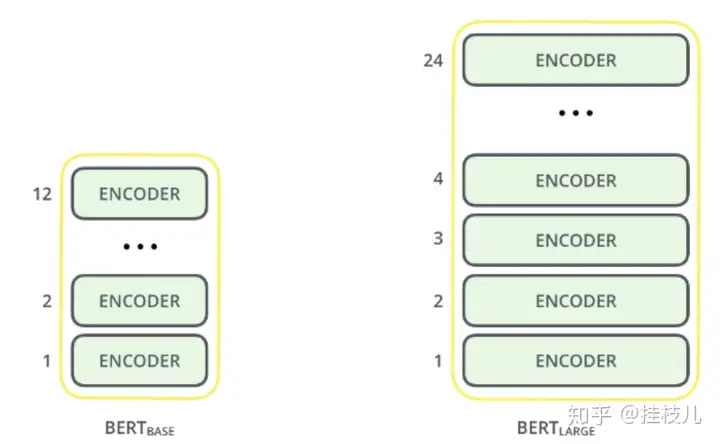
2. BERT对于预料的预处理
BERT对于输入数据的表达不仅能够表达单一句子,也可以表达一对句子(Q&A形式)
每个输入序列的敌意token是特殊分类token - [CLS]。这个token是在分类任务中是用来聚合整个序列表达的。在非分类任务中无视。对于一个单一的字符序列,这个[CLS]后面跟着的就是句子字符,以及我们的分割token [SEP]
对于成对出现的句子,WordPiece间是用[SEP]来做分割。输入系列也以[SEP]作为结束token句子embedding意味着句子A和B 之间的token是互相叠加的. 句子Embedding有像word embedding中vocabulary==2我们也会对字符串的位置进行positionl embedding.
BERT开发者对于在把预料扔进模型之前有很一套标准.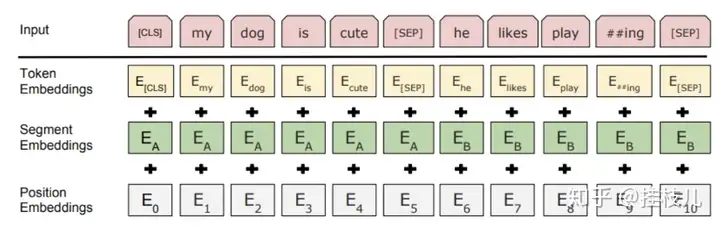
首先,模型的每一个输入都由三个Embedding构成:Position Embedding: BERT用这个来学习表达词语在句子中的位置。学习这个能够抵抗RNN没有办法去捕捉预料顺序的缺陷Segment Embedding:BERT可以成对的方式接受输入.Token Embedding: **从WordPiece中学习。
对于一个给定的Token,他在模型汇总的表达将由上面上面三个Embedding**累加得到。这样能够使得模型能够得到更多有用的信息。3. 预训练
模型会同时在2个任务上进行训练(这两个技术在此Kernal中没有说明)
遮蔽语言模型(Masked Language Model)Next Sentence Prediction.4. BERT的fine tuning技术:
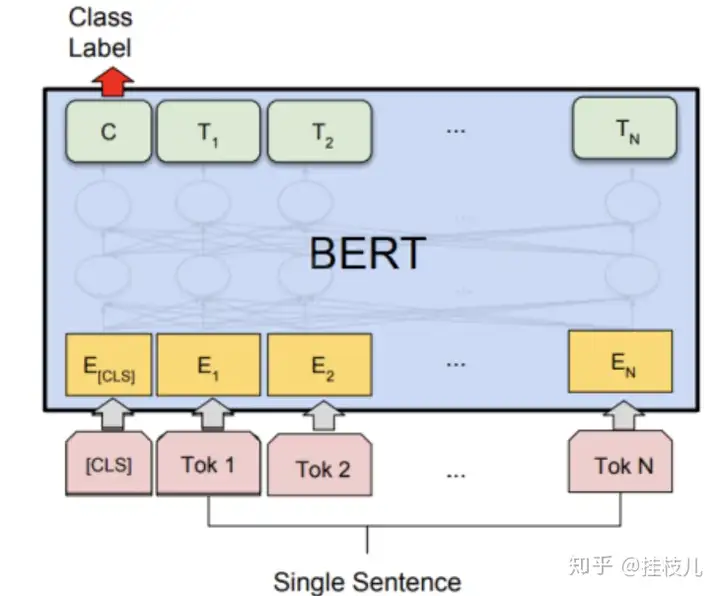
4.1 序列分类任务
在隐层上的最后一个[CLS]token表达的是在目前fix-dimensional上对于输入信息的表达,以供后续分类层来进行使用。分类层上的参数是我们需要训练的唯一训练,他的维度一般是 K * H ,K 是分类器标签个数,H是隐层的大小,最终的分类结果一般用softmax搞一下
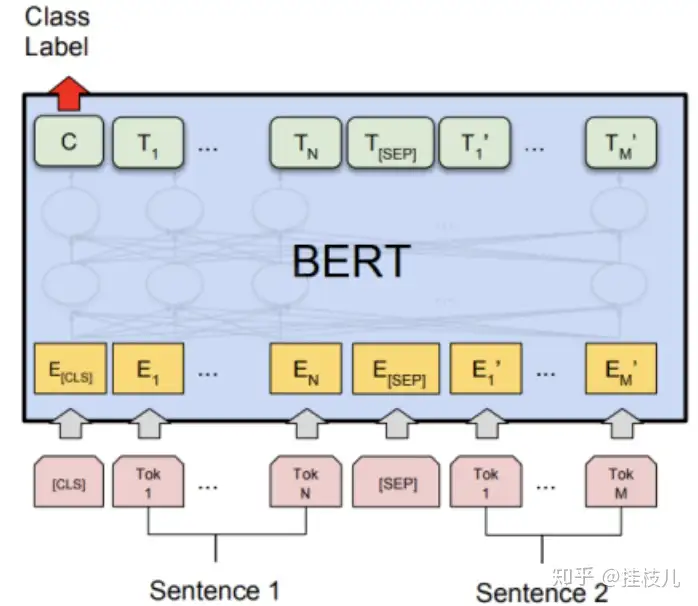
4 成对的语句分类任务
这和5.1差不多,唯一的区别是输入表达的2句句子是concat在一起的.
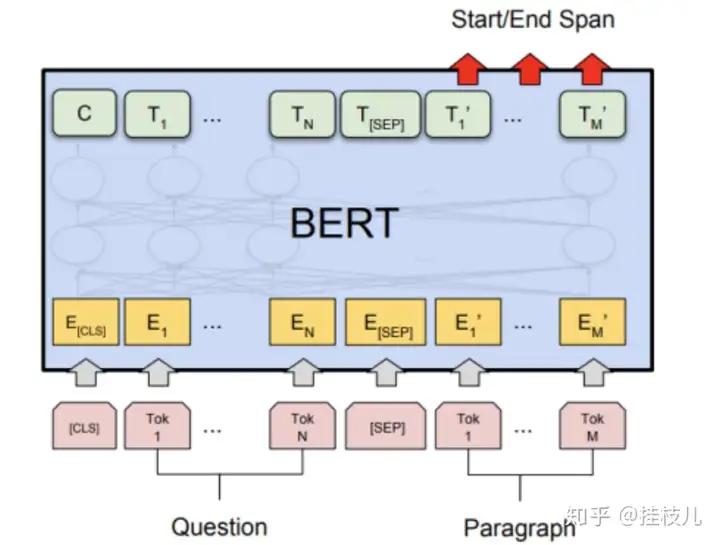
4.3 问题回答任务:
问题回答是一个预测性任务。给定一个问题和上下文,模型会预测一个问题答案

像成对的语句分类任务一样,问题将会办成第一个输入,上下文变成第二个输入。在这个过程中唯一会学习2个新的参数是一个起始向量和一个结束向量 (与隐层的shape相同)。
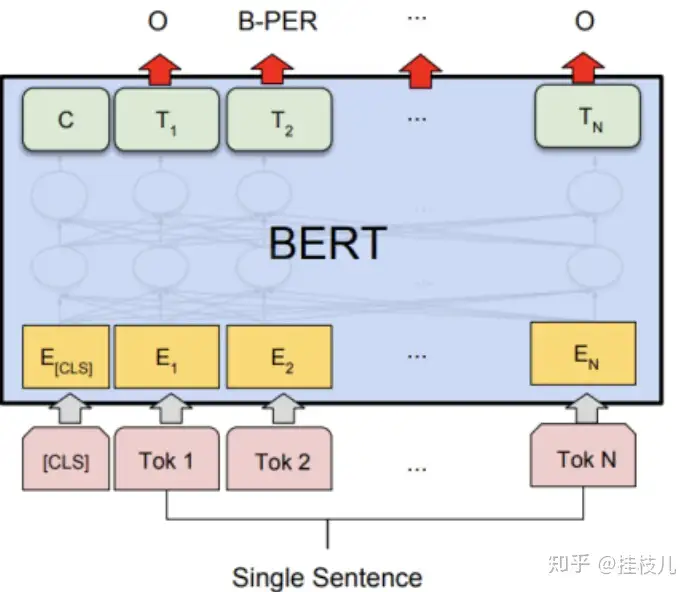
4.4 单序列语句tagging
对于单输入序列的tagging任务比如说人名检测,模型必须对于每个输入给出一个输出。最后的隐藏输出h将会扔给预测层来对于每输入给出预测。
4.5超参数调优:
超参数建议按照如下序列取值:
Dropout– 0.1Batch Size – 16, 32Learning Rate (Adam) – 5e-5, 3e-5, 2e-5Number of epochs – 3, 4 另外数据量比较大的话(>100k样本)对于超参数的选取将不是特别明显.一些Key takeaway
模型的size很重要,BERT_large有345百万个参数,基本是现在的万能语言模型了。只要有足够的训练数据,更多的训练 = 更高的准确率.BERT的双向(MLM)虽然比起传统的从左读到右的方式更慢,但训练的效果会比常规的效果更好。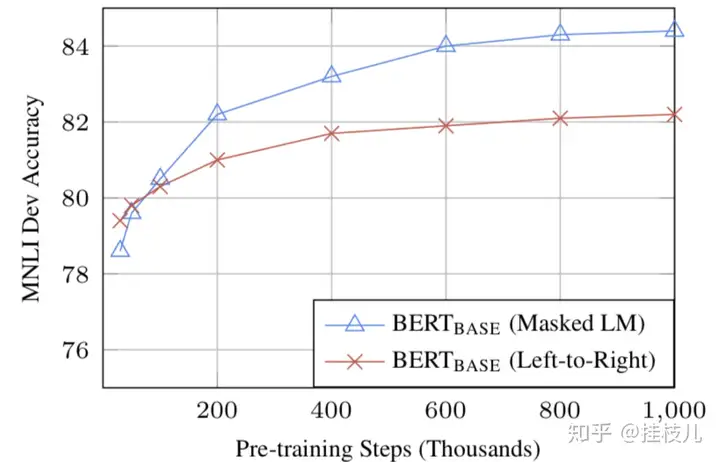
原文接下去开始代码示例,但我只是想了解一下所以就懒得码一遍了,感兴趣可以去顶部链接直接看原文。
以上就是关于《简单了解一下BERT-了解一下用英语怎么写》的全部内容,本文网址:https://www.7ca.cn/baike/61584.shtml,如对您有帮助可以分享给好友,谢谢。