从零解析ELF目标文件(附源码)(elfficiency)
前言
今晚状态不太好, 写着写着不小心发布了.(还没有写完) ,但是没有投到我的专栏里面. 然后我就删除了重新写. 之前想着好好写一个教程一步步的解析ELF的. (其实没有太大的必要. Linux下有一大堆的工具可以解析). 但是由于写的都被我删除了. 然后今晚状态又不是很好. 再都代码已经写完了. (虽然还有一些瑕疵,完成了95%以上吧) 要看的直接看代码吧. 这个算是一个C++版本的class文件解析. 如果想看 JVM版本的文件解析,请参考:
- 肥猫:深入学习JVM之Class文件二进制解析
这个是专栏: 读书笔记 - 程序员的自我修养
如果喜欢,还可以关注我的专栏: 跟我一起读OpenJDK源码在读<程序员的自我修养 - 链接,装载,库>时,作者使用各种工具组合来查看了ELF文件的结构与布局.但是如果没有详细了解机制的话读起来还是会晕. 如果你已经了解了ELF文件的解析方法.那反过来读则不会有这种感觉. 因此, 现在我们就抛开各种工具, 从零开始解析一下 ELF文件的内容与布局.
基础介绍
ELF文件是什么
ELF 是 Executable Linkable Format 的简称. 它是Linux平台的可执行文件的存储格式. 它是一种基于 COFF( Common File Format )文件标准的变种.
目标文件是什么
目标文件是编译出来后,没有进行链接前的中间文件. 一般为Linux平台的目标文件的后缀是: .o 而在Windows平台的目标文件的后缀是.obj; 同时, 目标文件的存储格式实际与可执行文件使用的是同一套存储标准,即 .o文件在Linux平台上与可执行文件都是使用的ELF文件格式进行存储的.
实际上,除了目标文件,我们熟悉的动态链接库文件也是使用ELF文件标准进行存储的. 动态链接库在Linux平台下的后缀是:.so ,而在Windows平台下的后缀是:.dll (有Windows平台编程经验的小伙伴应该不陌生);
注: windows平台下的可执行文件标签是PE-COFF ,它是标准的COFF文件的变种.
COFF 文件格式是Unix System V Release 3 提出的标准.后来微软公司基于 COFF制定了 PE 文件格式标准. 并将其应用于Windows NT系统. Unix System V4 在COFF的基础上引入了ELF . 目前流行的Linux系统也是使用ELF格式作为基本的可执行文件格式.
目标文件格式
文件头
一般的二进制文件格式都会制定文件头, 这样我们在解析文件的时候可行先读取文件头.判定文件格式,然后再根据文件头信息进一步的确认后序步骤怎样解析.
Linux的文件头定义了两种标准.一种是32位机器的,一种是64位机器的. 它们的内容结构其实是一样的(不是全部,可以基本认为是完全等价的),只是存储宽度不一样而已.
由于我要解析的是64位平台的文件.直接看64位版本即可.
表头中的字段主要描述elf文件服务的目标平台,以及相关的版本等信息. 同时给出了段表(Section Header Table)在文件中的偏移,字段: Elf64_Ehdr.e_shoff ,它表明段表在文件中的偏移. 偏移有了我们要知道有多少个item以及每一个item的大小, 这里的item就是段描述符: section descriptor 每一个描述符代表一个段. 比如在一个ELF文件中,就会存在一个.text的段. 那就会存在一个段描述符与之对应.段描述符的大小为: e_shentsize 它表示一个段描述符的大小.段描述符的个数为: e_shnum ,它表示我们的ELF文件中有多少个段描述符,同时也说明了一个ELF文件中有多少个段.注: ELF文件头可以使用命令: readelf -h xxx来直接查看.文件头中我们可以得到以下重要信息:
e_shoff: 段表在文件中的偏移位置.e_shentsize: 段表中的每一个段描述符的大小.e_shnum: 段描述符的个数. 即有多少个段.e_shstrndx: 段表中所描述的段的相关信息所引用的字符串表所在的段表的段描述符的索引号.有了以上信息,我们就可以接着往下解析. 段头相关的信息我不再赘述. 可以参考原书以及我的代码中的参考文献.
这个时候我们能得到的布局信息如下:
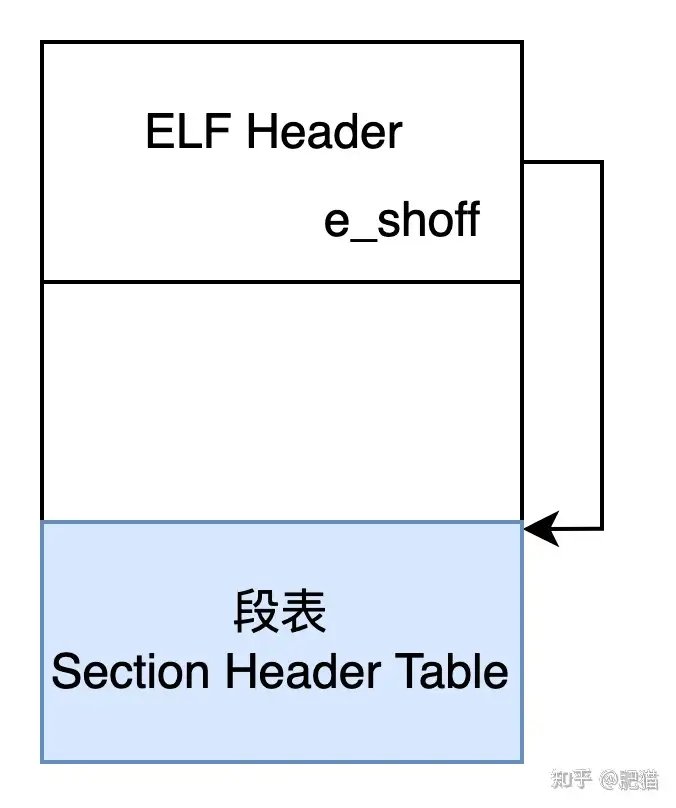
段表: Section Header Table
众所周知,在ELF文件中存在很多的段. 比如.text段,.data以及.bss段.而这些段所在的地方以及他们的基本属性, 这些由段的元数据进行描述,而这些元数据所在的地方就是段表. 这描述了各ELF段的基本信息,比如: 段名,段长度,段偏移,段属性等.
同样,存在两个版本的Shdr分别是32位与64位.以上信息重要的摘抄如下
sh_name: 一个段的名称. 这个是引用的 段名字符串表(.shstrtab段)中的偏移. (注意: 不是索引号, 这里是偏移. 一个相对于文件的偏移)sh_type: 段的类型. 参考: https://refspecs.linuxfoundation.org/elf/gabi4+/ch4.sheader.html#sh_type NameValueSHT_NULL0SHT_PROGBITS : 程序/数据/1SHT_SYMTAB : 符号表2SHT_STRTAB : 字符串表3SHT_RELA : 重定位表4SHT_HASH: HASH 表5SHT_DYNAMIC: 动态链接6SHT_NOTE : 注释7SHT_NOBITS: 不存在于文件中8SHT_REL : 重定位的一些信息9SHT_SHLIB10SHT_DYNSYM : 动态链接的符号表11SHT_INIT_ARRAY14SHT_FINI_ARRAY15SHT_PREINIT_ARRAY16SHT_GROUP17SHT_SYMTAB_SHNDX18SHT_LOOS0x60000000SHT_HIOS0x6fffffffSHT_LOPROC0x70000000SHT_HIPROC0x7fffffffSHT_LOUSER0x80000000SHT_HIUSER0xffffffffsh_addr 加载到内存后的虚拟地址. 比如.text段.加载到内存后,其起始地址就应该是这里指定的虚拟地址 sh_offset: 相对于文件的偏移sh_size: 段内容的大小.这里先不急着把我们已经掌握的文件布局画出来,我们先把段名字符串表解析后再过来看它.
段名字符串表:
上面有说到一个段的名称在.段描述中进行定义时,是引用的段名字符串表的内容. 这个段就是.shstrtab段.
其实字符串表的内容非常简单. 大家可以理解为把一个个的ASCII字符串直接堆到一起就完事了. 比如下图:

这个内容分析起来很简单. 第0个字符串是一个空串, 也就是上图中第一行中的黄色的那个\0 ;后序是跟着其它的字符串,紧接着的是:.systab然后是.strtab 用一个表格描述就是: String Table

比如我要引用字符串:variable ,那sh_name 的值应该就是: 7; 所以是偏移.不是索引号.切记.
有了以上信息后,我们可以对ELF文件的大概而已基本就可以画出来了.
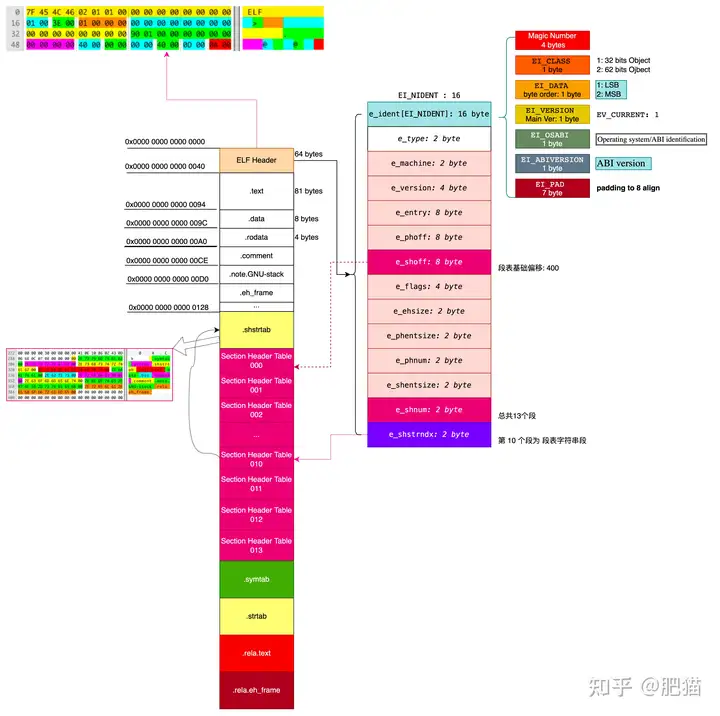
解析:
代码(github)
https://github.com/jianhong-li/ElfReader
二进制分析
为了方便分析和对比.这里给出待研究的ELF文件的HEX的内容图:

程序结果:
文件头:
段表:

符号表:
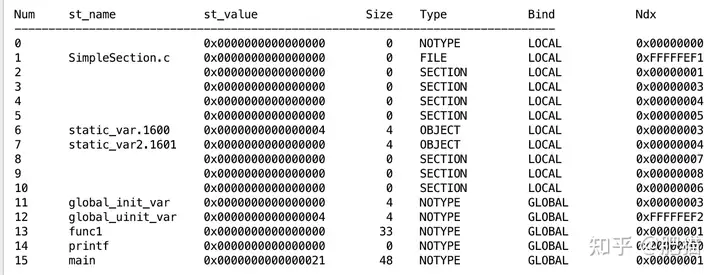
具体解析过程与细节见源代码, 一些如符号表解析. 相关的字段的取值的枚举定义,请参考官方文档和我的源码. 书中介绍的是32位的. 64位程序解析还是有很多不一样. 上体大家在解析时多参考官方文档.
源代码: https://github.com/jianhong-li/ElfReader

参考:
System V Application Binary Interface - DRAFT - 24 April 2001程序员的自我修养 - 书签版http://www.staroceans.org/e-book/elf-64-hp.pdf以上就是关于《从零解析ELF目标文件(附源码)(elfficiency)》的全部内容,本文网址:https://www.7ca.cn/baike/65551.shtml,如对您有帮助可以分享给好友,谢谢。