长文之最全的Pytorch入门讲解_pytorch零基础入门
目录:
1.pytorch入门教程(非常详细)
2.pytorch新手入门
3.pytorch 快速入门
4.pytorch60分钟入门
5.pytorch教程
6.pytorch 入门教程
7.pytorch入门到进阶
8.pytorch入门
9.pytorch入门书
10.学pytorch的基础
1.pytorch入门教程(非常详细)
作为目前越来越受欢迎的深度学习框架,pytorch 基本上成了新人进入深度学习领域最常用的框架相比于 TensorFlow,pytorch 更易学,更快上手,也可以更容易的实现自己想要的 demo今天的文章就从 pytorch 的基础开始,帮助大家实现成功入门。
2.pytorch新手入门
首先,本篇文章需要大家对深度学习的理论知识有一定的了解,知道基本的 CNN,RNN 等概念,知道前向传播和反向传播等流程,毕竟本文重点是一篇实操性的教程其次,这篇文章我更想从一个总体性的视角展开,大家在学习的过程中更注重的应该是在接触新知识时,如何设计学习路线的一种思路分享。
3.pytorch 快速入门
这种思路不一定适合所有人,但是肯定可以对你有所借鉴,你也可以基于此总结出来更适合自己的方法1. 开始一个简单的分类器我个人在学习一门新语言,一个新框架,一个新技术时,最优先要保证的就是成就感反馈以学习 pytorch 为例,很多教程从张量开始。
4.pytorch60分钟入门
我自己也按照这种教程学习过,的确内容非常全尽,但是有两个原因,我自己不太推荐以这种方式入门:1)前期学习过于枯燥,没有成就感;2)有的知识内容属于深度学习的基本功,过于赘述所以我觉得入门一个新知识的知识,最好是先搭起来结构,然后再去慢慢补充细节。
5.pytorch教程
因此我在这篇文章的第一部分,先选择构建一个简单的分类器,让大家知道一个 pytorch 下的代码流程应该是什么样子学过 c 语言的朋友肯定知道,我们先学第一个代码的时候,肯定是先来一个 hello world,而不是去研究第一行的 #include。
6.pytorch 入门教程
对于第一个 pytorch 程序而言,我们要做的是首先跑通整个流程,如果是一个简单的分类器,数据集也就不能太复杂因此,我们从三方面考虑:1)自定义生成一些点,分为两类;2)学习如何构建一个浅层的神经网络;3)尝试 pytorch 中的训练和测试过程。
7.pytorch入门到进阶
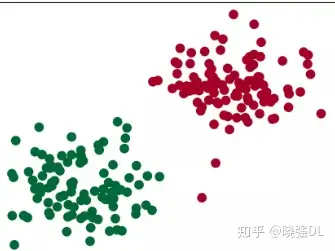
1.1 自定义生成数据集首先,自定义生成我们的数据集利用 torch 自带的 zeros,ones 这些方法,我们生成一些随机的点,分为两类比如分别以(2,2)和(-2,-2)为均值,随机生成一些随机数,作为两类,这样子我们就得到了我们想要的数据集。
8.pytorch入门
1.2 学会构建网络的流程其次,就是构建一个浅层的神经网络,这里我们给出一个代码示例,大家了解一下最基础的 pytorch 的网络应该如何构建:classNet(torch.nn.Module):def
9.pytorch入门书
__init__(self,n_feature,n_hidden,n_output):super(Net,self).__init__()self.n_hidden=torch.nn.Linear(n_feature
10.学pytorch的基础
,n_hidden)self.out=torch.nn.Linear(n_hidden,n_output)defforward(self,x_layer):x_layer=torch.relu(self
.n_hidden(x_layer))x_layer=self.out(x_layer)x_layer=torch.nn.functional.softmax(x_layer)returnx_layer
net=Net(n_feature=2,n_hidden=10,n_output=2)# print(net)optimizer=torch.optim.SGD(net.parameters(),lr=
0.02)loss_func=torch.nn.CrossEntropyLoss()这个 Net 类,就是我们构建的代码框架,用它生成的对象就是一个我们可以用来训练和测试的网络这个类中,初始化函数中表示了每个网络层的结构设置,而 forward() 方法表示了每个层之间的交互顺序和关系。
而 optimizer 就是优化器,包含了需要优化的参数有哪些,loss_func 就是我们设置的损失函数这个就像我们写一个 hello,world 一样,我们只需要知道自己该如何构造一个网络当我们需要调整的时候,就将其中对应的模块替换掉。
1.3 训练与测试接下来就是训练与测试的阶段训练我们需要知道三句代码是核心:optimizer.zero_grad()loss.backward()optimizer.step()这里的核心思路是,梯度清空,反向传播,参数更新。
分别对应了这三句代码的作用在pytorch 中,梯度会保留,所以需要用 zero_grad() 来清空,然后利用损失函数反向传播计算梯度,最后就是用我们定义的优化器将每个需要优化的参数进行更新测试阶段就很简单了,直接将输入丢进去就可以看到预测结果。
现在我们重新随机生成一些数据点作为测试集,可以看到训练集对它的分类结果就很明显至此,我们就完成了一个对于简单分类器的描述当然,如果你对前面的文章没有任何了解,可能会觉得这部分不够入门2. 在 MNIST 上实现一个 cnn。
完成了一个线性分类器后,我们的学习路线应该是什么样子呢?我觉得比较合适的做法是先改动 “hello,world” 的部分,让我们看看把最直观的部分进行修改,会有哪些变化并且可以得到很直接的成就反馈做深度学习,肯定最熟悉的就是 CNN 做图片分类。
在一张图片上,通过卷积来一层层的提取特征,最终实现分类的效果那么我们既然已经知道如何实现一个分类器,接下来就来看看如何用 CNN 完成图片的分类这里的数据集我们选择 mnist,是大家经常用来作为入门的图片分类数据集,内容是各种手写数字的展示。
在安装 torch 的时候,大家参考的教程一般也会推荐安装 torchvision在这个之中给出了一个 dataset 的集合,其中包括了各种各样的常见数据集,mnist 自然也是其中之一对于这些数据集的使用方法,主要是 root,transform 等几个参数,并不是很难。
然后对应的有一个 torch.data 中的 DataLoader 方法,可以用来让数据按自己想要的 batch 生成具体的如何并行式生成数据,在本文的最后一部分会进行介绍这里我们只需要知道可以使用 DataLoader 并行式按批生成数据。
核心的是如何构建一个 CNN 网络我们前面学会了分类器,只使用了一个隐藏层进行 embedding 操作就可以了那么如果要实现 CNN,我们自然要加入卷积层,激活层,池化层这些操作class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.conv1 = nn.Sequential( nn.Conv2d( in_channels=1, out_channels=16, kernel_size=5, stride=2, padding=2, ), nn.ReLU(), nn.MaxPool2d(2) ) self.conv2 = nn.Sequential( nn.Conv2d(16, 32, 5, 1, 2), nn.ReLU() ) self.out = nn.Linear(32 * 7 * 7, 10) def forward(self, x): x = self.conv1(x) x = self.conv2(x) x = x.view(x.size(0), -1) output = self.out(x) return output。
所以按照这个样子,我们就可以改造前面简单分类器的结构,生成我们现在的 CNN 结构从代码中可以看到,将第一个卷积层设计为:卷积+激活+最大池化;第二个卷积层设计为:卷积+激活最后跟上一个全连接层,实现整个 CNN 的网络结构设计。
最终的网络运行结果可以对 mnist 数据集达到 97% 以上的分类精度,可见 CNN 在图片分类领域的确有独到的优势那么在完成了这一步的操作后,我们可能需要思考一点:如果我自己想去做一些更自定义的网络结构出来,该如何实现呢?我又怎么知道去修改哪里,以及修改成什么样子呢?所以接下来需要了解的是 torch 都提供了哪些集成好的常用网络层。
3. 常用网络层介绍通过两个递进的例子,我们已经知道了该如何实现一个基本的 CNN 网络结构但是如前面提到的问题一样,如果想改某一部分,应该怎么改呢?所以从学习的角度出发的话,现在应该考虑的是介绍常用的网络层都有哪些。
然后我们就可以(成为一个调包侠哈哈,入门肯定要从调包开始嘛~)开始针对自己想要设计的网络结构选择合适的模块啦~在这部分我们从以下几个方面去对 pytorch 提供的网络层进行了介绍:卷积层:自带了一维,二维,三维等卷积函数;
池化层:可选的有最大池化,平均池化等;Dropout:有一维,二维等选择;BN层:是否加入 BN 层的操作;激活函数:elu,relu,sigmoid,tanh,softmax 等层可供选择;损失函数:mse,CrossEntropy 等可供选择。
4. tensorboard 可视化现在我们具备了初步构建自定义网络结构的能力,也可以完成在自带数据集上进行训练和测试的操作那么如何让我们对训练过程中的性能有一个更直观的认识呢?对网络结构如何进行可视化呢?数据集的内容是什么样子的?。
这些功能我们都可以用一个名为 tensorboard 的工具来实现,这个工具在 TensorFlow 中也很常用如何学习使用 tensorboard 呢?这部分我们建议从如下几个步骤去进行:首先举一个简单的例子,让代码示例跑起来;然后将整个训练过程可视化出来;最后再展示如何可视化数据集的内容以及网络结构流程。
4.1 run一个例子这里我们选择先运行一个官方教程给出的例子,了解如何使用 tensorboard 的基本流程:from torch.utils.tensorboard import SummaryWriter writer = SummarWriter() x = range(100) for i in x: writer.add_scalar(y=2x, i * 2, i) writer.close()
从这个流程中我们可以看到,引入了一个 SummaryWriter 类,然后生成一个 writer 对象,在 for 循环中,每次调用 add_scalar() 方法,往进添加内容在完成这个代码后,如果我们在终端中输入:。
tensorboard --logdir=runs我们会得到一副 y=2x 的斜线,这就相当于揭示了 tensorboard 的本质每次将一个值传入 ‘runs’ 文件夹中的文件中,然后在终端中去调用保存的数据,产生我们想要的图形。
在实际应用的时候,有可能环境变量没有配好,可先配环境变量,或者使用Tensorboard的绝对路径这一步我们主要是理解上面的这个流程,那么我们就来看看该怎么替换想要换掉的模块,来生成我们想要生成的图形4.2 可视化 CNN 的训练数据
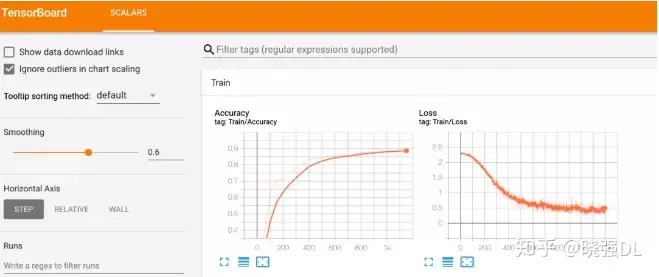
前面第二部分,我们定义了一个 CNN 来实现对图片的分类效果那么在训练过程中的 accuracy 和 loss 是如何变化的呢?output = cnn(b_x) loss = loss_func(output, b_y) optimizer.zero_grad() loss.backward() optimizer.step() if step % 50 == 0: test_output = cnn(test_x) pred_y = torch.max(test_output, 1)[1].data accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0)) writer.add_scalar("Train/Accuracy", accuracy, step) writer.add_scalar("Train/Loss", loss.item(), step)。
这里我们可以看出来是训练部分的内容,只是在后面加上了我们前面的一个步骤:添加了两行 add_scalar() 方法其实就是训练时每隔 50 步都进行一次测试,并将测试结果记录下来,并且每一步的 loss 也都会保存下来。
所以到最后,我们在终端中输入上面提到的:tensorboard —logdir=dir,就可以看到下面这幅图:
除了上面对数值的记录,tensorboard 还提供了诸如图片和模型等的可视化,相比于使用 add_scalar(),这里我们使用 add_image() 和 add_graph() 来实现对应的功能add_image() 对图片数据进行保存,每次输入一个 batch 的数据,也就是说 batch 有多大,其实相当于可视化了多少的 image。
add_graph() 则是对模型结构的保存,在可视化的时候,就可以对这些内容进行自动展示5. vgg 及一些 tricks这一部分的内容就比较简单了,找一个比较经典的深层网络来实现一下,验证一下我们之前的基础。
此外,再介绍一种方法来简化深层网络的构造方法首先实现一个 vgg 本身并没有太多难度,我们看一看 paper,就可以知道网络的结构设置我们不拘泥于 vgg,而是说一个深层次的网络的构成实现一个长的网络,本质上还是按照前面的思路,一层层的把网络堆叠起来。
我们先看使用 Sequential 构建一个卷积层的样子:
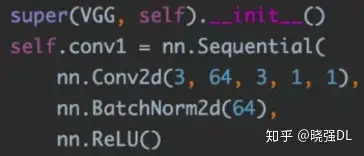
这是一层的网络样子,我们根据自己要实现的网络定义,比如参考 vgg 的 paper 内容,定义了卷积层的各个参数,加上 BN 层,加上 relu 进行激活整体就是我们定义好的一层,其它层以此类推,用我们前面介绍的常用网络层就可以像搭积木一样,把它们搭建起来。
所以按照前面的教程思路,一个深层的神经网络,例如 vgg,本质上是可以通过简单的堆叠来实现的最后我们在 forward 函数中,定义好如下内容:def forward(self, x): x = self.conv1(x) x = self.conv2(x) x = self.conv3(x) x = self.conv4(x) x = self.conv5(x) x = self.conv6(x) x = self.conv7(x) x = self.conv8(x) x = self.conv9(x) x = self.conv10(x) x = self.conv11(x) x = self.conv12(x) x = self.conv13(x) x = x.view(x.size(0), -1) output = self.out(x) return output。
可以看到从内容上就是前面的 CNN 的扩展,没有技术上的新东西但是也显然易见,有点丑陋,写这么长个 forward,而且还看起来都是重复的东西,程序员当然不能容忍重复的内容一直出现所以这里分为两步我们去考虑如何简化一个模型:sequential 以 list 的形式输入各层的网络结构;更加方便的生成各层网络结构的 list。
具体的意思是什么呢?我们简单的展开来讲一下对一个网络的设置而言,我们使用 Sequential 来定义我们想要的一层网络这里的一层往往指代卷积+激活+池化等,当然不固定是这样子换句话说,一个 Sequential 里面本身就定义了不止一个网络,那么我们是否可以将所有网络都放到一个 Sequential 里面来?答案是可以的!。
对于一个 Sequential,我们可以将所有的网络结构都输入进去,以动态参数的方式也就是说,我们让 Sequential 的输入是这个形式:*[网络层1,网络层2,…,网络层n]可以看到,是一个 list 前面加 *,就可以将 list 中的所有元素以参数的方式传进去。
但是这样输入进来的参数,需要一个非常非常长的 list在定义这个 list 的时候,显得我们的模型更加难看所以我们需要一个优雅的方式,来生成这样一个 list,其中的每个元素都是我们想要的网络层结构所以我们介绍的生成方式就是下述代码:。
def make_layers(cfg, batch_norm=False): layers = [] in_channels = 3 for v in cfg: if v == M: layers += [nn.MaxPool2d(kernel_size=2, stride=2)] else: conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1) if batch_norm: layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)] else: layers += [conv2d, nn.ReLU(inplace=True)] in_channels = v return nn.Sequential(*layers) cfg = [64, 64, M, 128, 128, M, 256, 256, 256, M, 512, 512, 512, M, 512, 512, 512, M]
这里就可以很直接的看到,最终生成的 layers 这个 list,就是我们想要的内容,其中包含了我们需要的每个网络层结构在 for 循环中就是我们生成的方式,按照在参数 cfg 中定义的内容,依次往 layers 中添加我们需要的内容。
数字表示该卷积层的输出通道,字母 ‘M 表示最大池化关于BN和VGG网络的论文讲解,可以看我的文章:晓强DL:图像处理必读论文之四GoogLe-2:Batch Normalization2 赞同 · 1 评论
文章
晓强DL:图像处理必读论文之二:VGG网络7 赞同 · 0 评论文章
6. GPU 和如何保存加载模型到了这一步,我们的网络深度也加上来了,是时候考虑一下 GPU 加速的问题了GPU 在深度学习中是无论如何也绕不过去的一个话题,好在 pytorch 在 GPU 的使用方面给了非常友好的接口,下面我们就看一下如何使用 GPU 加速,以及如何保存训练好的模型,到测试时再加载出来。
6.1 先看看 GPU 咋用吧我们就来说一下 GPU 在 pytorch 中有多么简单易用吧首先如下简单命令:torch.cuda.is_available()这条命令可以判读你是否安装好了 GPU 版本的 pytorch,或者你的显卡是否可以使用,如果结果显示 。
True,那我们就可以进行下一步了GPU 的使用在 pytorch 中,我们就记住三部分:迁移数据,迁移模型,迁回数据首先迁移数据是指,我们需要将数据迁移到 GPU 上,这个时候就体现出显存的重要性,显存越大,就可以往进迁移的数据越多;。
其次是迁移模型,也就是说将我们定义好的网络模型也迁移到 GPU 上,这个时候就可以在 GPU 上对给定模型,利用迁移进来的数据进行训练和测试;最后是迁回数据,也就是说将测试好的结果再返回 CPU,进行下一步的其它处理,比如计算精度之类。
这里给一个小栗子来为大家看一下这三步:# 指定好用的 GPU 设备,如果是单卡,一般就是 0.device = "cuda:0" # 迁移数据 images = images.to(device)labels = labels.to(device) # 迁移网络,将我们定义好的网络 cnn 迁移到 GPU 中。
cnn.to(device) # 训练...# 测试... 生成测试结果 pred_y # 迁回数据,将 pred_y 再迁回 CPU pred_y = pred_y.cpu()通过这个例子,我们可以很清晰的看到如何使用 GPU 完成我们上所述的三个步骤。
只要保证了将这三部分加入到你的代码中,中间的训练和测试依然保持原样,我们就实现了利用 GPU 加速的目的6.2 训练好的模型如何保存和加载呢?关于 pytorch 中的模型保存,一般有两种途径:只保存网络参数,保存整个网络。
首先要知道的一点是,在 pytorch 中所有的网路参数数据都是一个 dict,也就是网络对象的 state_dict() 参数那么我们如果想保存下来需要的内容,其实在底层操作方面并不复杂现在来看如何保存模型,其实就一条语句:torch.save(content,path),就可以将需要的 content 保存到目标的 path 中。
这里唯一的需要思考的是如何区分只保存网络参数,还是保存整个网络只保存网络参数时,我们的 content 就是 cnn.state_dict(),如果保存整个网络,content 就是 cnn下面两行代码分别是只保存参数和保存整个网络:。
torch.save(cnn.state_dict(), PATH)torch.save(cnn, PATH)可以看到保存的方式非常方便,一个函数就可以完成那么对应的,读取的方式是什么呢?分别用两个不同的方法来进行读取:load_state_dict() 和 load()。
只看名称也可以想到前者是读取参数,后者是读取整个网络但是只读取参数的话,我们需要提前定义好对应的网络对象,然后通过读取参数的方式,为网络的结构中填充相应的参数7. RNN 回归前面我们介绍了 CNN 的创建方式,常用的网络层,基于此的基础上,又介绍了一些其它的相关操作,比如 GPU 加速等。
现在我们来看系列教程的最后一部分,就是如何使用 RNN以 RNN 为例,我们构建一个回归器,以此来介绍 RNN 在 pytorch 中的使用方法,帮助大家入门 RNN 的操作过程7.1 RNN 参数我们这里不再赘述 RNN 的定义和内容,在本节后面的文章链接中,详细的介绍了这一部分。
我们在这里只说一下在 pytorch 中的 RNN 类可以设置的参数input_size:这个参数表示的输入数据的维度比如输入一个句子,这里表示的就是每个单词的词向量的维度hidden_size :可以理解为在 CNN 中,一个卷积层的输出维度一样。
这里表示将前面的 input_size 映射到一个什么维度上num_layers:表示循环的层数举个栗子,将 num_layers 设置为 2,也就是将两个 RNN 堆叠在一起,第一层的输出作为第二层的输入。
默认为 1nonlinearity:这个参数对激活函数进行选择,目前 pytorch 支持 tanh 和 relu,默认的激活函数是 tanhbias:这个参数表示是否需要偏置项,默认为 Truebatch_first
:这个是我们数据的格式描述,在 pytorch 中我们经常以 batch 分组来训练数据这里的 batch_size 表示 batch 是否在输入数据的第一个维度,如果在第一个维度则为 True,默认为 False,也就是第二个维度。
dropout:这里就是对每一层的输出是否加一个 dropout 层,如果参数非 0,那么就会加上这个 dropout 层值得注意的是,对最后的输出层并不会加,也就是这个参数只有在 num_layers 参数大于 1 的时候才有意义。
默认为 0bidirectional:如果为 True,则表示 RNN 网络为双向结构,默认为 False这些参数的给定,我们就可以轻松的去设置我们想要的 RNN 结构此处 input_size 和 hidden_size 是两个必须传入的参数,需要让网络知道将什么维度的输入映射到什么维度上去。
其余的参数都给了比较常用的默认值7.2 回归器:用 sin 预测 cos在这里我们举一个非常容易理解的例子也不去折腾什么复杂数据集,我们同样使用一个简单的自定义数据集:sin 函数作为 data,cos 函数作为 label。
因为重点是学习 RNN 的使用,所以我们无需测试集,只看训练的拟合程度,判断是否成功收敛就可以了首先给出来我们定义的 RNN 结构,再对其中的细节进行解读:class RNN(nn.Module): def __init__(self): super(RNN, self).__init__() self.rnn = nn.RNN( input_size=1, hidden_size=32, batch_first=True, ) self.out = nn.Linear(32, 1) def forward(self, x, h_state): r_out, h_state = self.rnn(x, h_state) outs = [] for time_step in range(r_out.size(1)): outs.append(self.out(r_out[:, time_step, :])) return torch.stack(outs, dim=1), h_state
我们先看第一部分 RNN 的结构上,定义了三个参数:input_size,hidden_size,batch_firstinput_size 我们设置为 1,是因为每次输入的数据上,只有一个点的位置,数据是一维数据;。
hidden_size 设置为 32,表示我们想要将这个数据映射到 32 维的隐空间上,这个值由自己进行选择,不要太小,也不要太大(太小会导致拟合能力较差,太大会导致计算资源消耗过多);batch_first 设为
True,表示我们的数据格式中,第一个维度是 batch最终,根据前面对参数的介绍,可以得知,我们构建了一个单层的 RNN 网络,输入的每个 time_step 上的数据都是一维的,通过将其映射到 32 维的隐空间上,来发掘对标签数据的拟合关系。
接下来我们看一下 forward 函数中的内容,与 CNN 的 forward 中有些不一样在 CNN 中,我们直接将对应的网络结构往一起拼接就可以,这里多了一些奇怪的参数这是为什么呢?从第一行开始看起,首先 RNN 我们都知道,每个 time_step 的循环中,都是将上一个循环的隐状态和当前的输入结合起来作为输入。
那么 r_out 和 h_state 就是当前状态的输出和隐状态第二行的 outs 是一个空列表,用来存储什么内容呢?我们往下看后面是一个 for 循环,循环的次数取决于 r_out.size(1)这个参数表示什么呢?r_out 我们知道是输出,这个输出的格式应该和输入是相同格式(batch,time_step,hidden_size),所以 r_out.size(1) 表示了这批数据的 time_step 的大小,也就是这批数据有多少个点。
将对应的数据进行 self.out() 操作,也就是将 32 维的数据再映射到 1 维,并将结果 append 到 outs 中这里我们就知道前面定义的 outs 列表用来装什么数据了,最后将结果 stack 起来,作为 forward 的返回值。
这里看一下训练过程中的拟合情况:
蓝色线条展示了模型的拟合过程,可以看到最终逐渐拟合到了目标的 cos 曲线上(红色线条)本部分更多的细节,包括 RNN 原理的简单介绍,对应的网络的运行细节都在:第七篇文章 中可以看到除此之外,这篇文章中还进一步给出了一个利用 LSTM 实现一个对 mnist 数据集进行分类的例子,帮助我们可以学习 pytorch 中 LSTM 的使用方法。
总结这是一篇对 pytorch 进行入门教程的文章,不仅仅是对框架的学习,这样的学习方法也可以借鉴到其它的框架,编程语言等中去,详细的可以了解Pytorch官网私信我可获得pytorch文档,进一步学习。
以上就是关于《长文之最全的Pytorch入门讲解_pytorch零基础入门》的全部内容,本文网址:https://www.7ca.cn/baike/8211.shtml,如对您有帮助可以分享给好友,谢谢。