在PyTorch上加载自定义数据集_pytorch自定义数据集
目录:
1.pytorch geometric自定义数据集
2.pytorch自定义dataloader
3.pytorch 自定义参数
4.pytorch加载自己的数据集
5.pytorch自定义transform
6.pytorch自己做数据集
7.pytorch 自定义backward
8.pytorch 自动调参
9.pytorch自定义卷积
10.pytorch如何定义变量
1.pytorch geometric自定义数据集
原标题:在PyTorch上加载自定义数据集

2.pytorch自定义dataloader
动机当你想建立一个机器学习模型时,你首先要做的就是准备数据集当数据是表格格式时则很容易准备,但如果是像图像这样的数据呢?图像与表格数据的格式不同这种格式有很多数据表示有些人根据图像对应的类将其放入一个文件夹,而有些人则以表格格式创建元数据,以描述图像文件名及其标签。
3.pytorch 自定义参数
当数据集采用第一种格式时,我们可以使用torch.data.utils库里一个名为ImageFolder的类来加载数据集但大多数情况下,图像数据集有第二种格式,其中包含元数据和图像文件夹因此,我们需要自行准备数据集。
4.pytorch加载自己的数据集
例如,你希望使用深度学习构建一个图像分类器,它由如下所示的元数据组成:

5.pytorch自定义transform
正如你看到的,数据集由图像id和标签组成在本例中,图像id还表示.jpg格式的文件名,标签采用one-hot编码格式如何加载数据集以便模型可以读取图像及其标签?在本文中,我将向你展示如何使用PyTorch加载包含元数据的图像数据集。
6.pytorch自己做数据集
我们将使用来自Kaggle竞赛的一个名为“植物病理学2020-FGVC7”的数据集,可以在这里访问这些数据:https://www.kaggle.com/c/plant-pathology-2020-fgvc7 。
7.pytorch 自定义backward
预处理元数据我们首先要做的就是对元数据进行预处理从上图中可以看到,数据集不包含图像文件名而且,标签仍然是one-hot格式但是值得庆幸的是,图像id还通过在id中添加.jpg来表示图像文件名生成图像文件名的代码如下所示:。
8.pytorch 自动调参
import pandas as pd# 假设你在KAGGLE笔记本上运行代码path = /kaggle/input/plant-pathology-2020-fgvc7/img_path = path + images
9.pytorch自定义卷积
# 加载数据集train_df = pd.read_csv(path + train.csv)test_df = pd.read_csv(path + test.csv)sample = pd.read_csv(path + sample_submission.csv)
10.pytorch如何定义变量
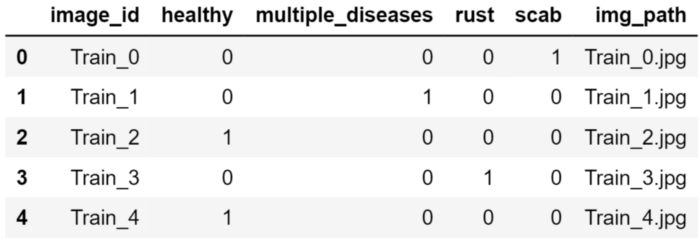
# 获取图像文件名train_df[img_path] = train_df[image_id] + .jpgtest_df[img_path] = test_df[image_id] + .jpgtrain_df.head()
结果是这样的:
在我们获得图像文件名之后,现在我们可以使标签成为一个单独的列代码如下:# 拆开和融合train_label = train_df.melt(id_vars=[image_id, img_path])# 过滤数据
train_label = train_label[train_label[value] == 1]# 获取图像ID号train_label[id] = [int(i[1]) for i in train_label[image_id].str.split(_)]
# 重置索引train_label = train_label.sort_values(id).reset_index()# 将标签添加到数据集train_df[label] = train_label[variable]
# 重新格式化数据集train_df = train_df[train_df.columns[[0, 5, 1, 2, 3, 4, 6]]]print(train_label.shape)train_df.head()
结果:

由于机器学习模型只能读取数字,所以我们必须将标签编码为数字代码如下:from sklearn.preprocessing import LabelEncoder# 对标签进行编码le = LabelEncoder()。
label_encoded = le.fit_transform(train_df[label])train_df[label_encoded] = label_encoded# 取类名label_names = label_encoded.classes_
train_df.head()结果:

在对元数据进行预处理之后,可以进入下一步使用Dataset类生成图像容器下一步是为图像和标签构建一个容器对象需要构建该对象的原因是为了使我们将数据加载到深度学习模型的任务变得更容易因此,我们可以使用索引来访问图像及其标签。
为了创建对象,我们可以使用torch.utils.data库里一个名为Dataset的类这个类是一个抽象类,因为它由尚未实现的函数或方法组成因此,我们可以根据自己的需要来实现这些功能我们需要实现的函数是:。
__init__函数,__len__函数__getitem__ 函数.函数将从类初始化一个对象,并从用户那里收集参数函数将返回数据集的长度最后,最重要的函数是使用索引返回数据通过理解类及其相应的函数,现在我们可以实现代码了。
在本例中,我将使用名为PathologyPlantsDataset的类名,它将从Dataset类继承函数代码如下:class PathologyPlantsDataset(Dataset):"""该类将充当数据集的容器。
"""def __init__(self, data_frame, root_dir, transform=None):self.data_frame = data_frameself.root_dir = root_dir
self.transform = transformdef __len__(self):# 返回数据集的长度return len(self.data_frame)def __getitem__(self, idx):
# 根据索引返回结果. 例如,dataset[0]将返回数据集中的第一个元素,在本例中是图像和标签if torch.is_tensor(idx):idx = idx.tolist()img_name = os.path.join(self.root_dir, self.data_frame.iloc[idx, 1])。
image = Image.open(img_name)label = self.data_frame.iloc[idx, -1]if self.transform:image = self.transform(image)
return (image, label)创建了类之后,现在可以构建对象了创建对象时,我们将设置由数据集、根目录和转换函数组成的参数代码如下:# 实例化对象pathology_train = PathologyPlantsDataset(。
data_frame=train_part,root_dir=path + images,transform=transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])现在,我们可以使用对象提取图像及其标签如上所述,为了从数据中获取观察值,我们可以使用索引例如,当我们要访问数据集的第三行(索引为2)时,可以使用pathology_train[2]来访问它向你展示如何使用pathology_train变量可视化结果。
代码如下:temp_img, temp_lab = pathology_train[2]plt.imshow(temp_img.numpy().transpose((1, 2, 0)))plt.title(label_names[temp_lab])
plt.axis(off)plt.show()结果:

返回搜狐,查看更多责任编辑:
以上就是关于《在PyTorch上加载自定义数据集_pytorch自定义数据集》的全部内容,本文网址:https://www.7ca.cn/baike/8244.shtml,如对您有帮助可以分享给好友,谢谢。