FasterKV存储引擎介绍_存储引擎的概念及特点
目录:
1.存储引擎是什么
2.存储引擎的作用
3.存储引擎的定义
4.简述存储引擎定义及存储引擎的作用
5.federated存储引擎
6.myisam存储引擎特点
7.存储引擎innodb、myisam和memory各有什么优缺点?
8.存储引擎原理
9.存储引擎的定义和作用
10.存储引擎什么意思
1.存储引擎是什么
以下内容来自于腾讯工程师bonlin 导语:微软开源的FasterKV存储引擎,使用Hash作为主索引,基于Log追加写和原地更新的混合存储方式,无锁并发,性能亮眼介绍微软开源的FasterKV存储引擎,使用Hash作为主索引,基于Log追加写和原地更新的混合存储方式,无锁并发,性能亮眼。
2.存储引擎的作用
而另一类基于log存储的存储是使用hash作为主索引组织数据,如Bitcask,因为Hash,不具备范围查询这种重要的功能,但可以在其他方面发挥优势,如极高的性能的点查,FasterKV也是这类引擎FasterKV首次出现在微软2018年在Sigmod上发表的论文,代码也开源,其主要应用场景如下:
3.存储引擎的定义
Faster = Log + KV,即Faster分两部分,即FasterLog和FasterKV,前者是Log存储引擎,可作为独立的组件使用,后者是在Log之上的KV存储引擎,Log是C#实现,KV有C#和C++两版本。
4.简述存储引擎定义及存储引擎的作用
FasterKV具有极高的点查读写性能,在单机、数据全match内存的情况下,达1.5亿QPS。

5.federated存储引擎
架构
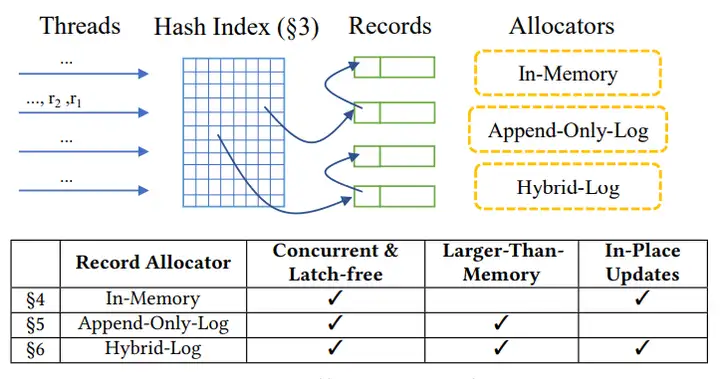
6.myisam存储引擎特点
数据组织上,Faster是一个全局的Hash主索引,放内存中,hash-entry不存key,指向Record-list,每个Record即KV对Record是从内存中分配(如基于jemalloc的分配器),或从log中分配,log会追加写,通过log刷盘进行数据的持久化。
7.存储引擎innodb、myisam和memory各有什么优缺点?
和传统的Log追加写的方式不同(所有的修改操作都创建一个record副本追加在log尾部),Faster在最热的log(cache在内存中)采用原地更新(in-place-update),从而避免log的快速增长,这也是Faster极高写性能的核心之一。
8.存储引擎原理
但原地更新,没有WAL,有宕机丢数据的风险Faster支持多线程并发,但经过对Hash主索引的巧妙设计,以及Epoch-Protection并发控制框架,整个系统是无锁(latch-free)并发的主要特性
9.存储引擎的定义和作用
主要功能特性: - 基本的点查读写,read、upsert(replace)、delete - 原子性的RMW(read-modify-write) - 多级存储,内存、SSD、Azure Storage
10.存储引擎什么意思
- 多线程,Multi-threaded session model access - Non-blocking(incremental)checkpoint & recovery - Key iteration & Full log scan
- 变长key和value - Log compaction - 【新】client-server & scale out - 【新】二级索引 - 【more】Roadmap - FASTER (microsoft.github.io)
API示例publicstaticvoidTest(){usingvarsettings=newFasterKVSettings("c:/temp");usingvarstore=
newFasterKV(settings);usingvarsession=store.NewSession(newSimpleFunctions((a,b)
=>a+b));longkey=1,value=1,input=10,output=0;session.Upsert(refkey,refvalue);session.Read(refkey,refoutput
);Debug.Assert(output==value);session.RMW(refkey,refinput);session.RMW(refkey,refinput,refoutput);Debug
.Assert(output==value+20);}性能数据

单线程(数据全放内存)
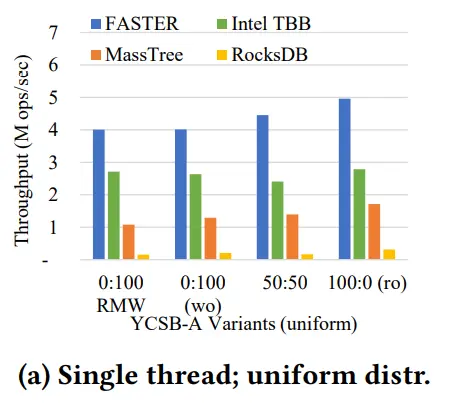
多线程扩展性(数据全放内存),达1亿以上QPS
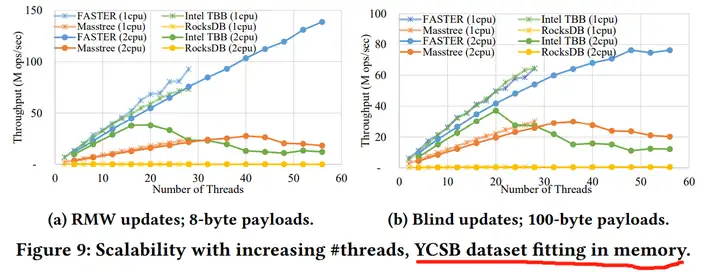
内存不足的情况,即使在内存受限的场景,写也能维持在极高的吞吐性能,根本原因是追加写+原地更新,都是内存热数据,不涉及写IO,而读操作则不一样。
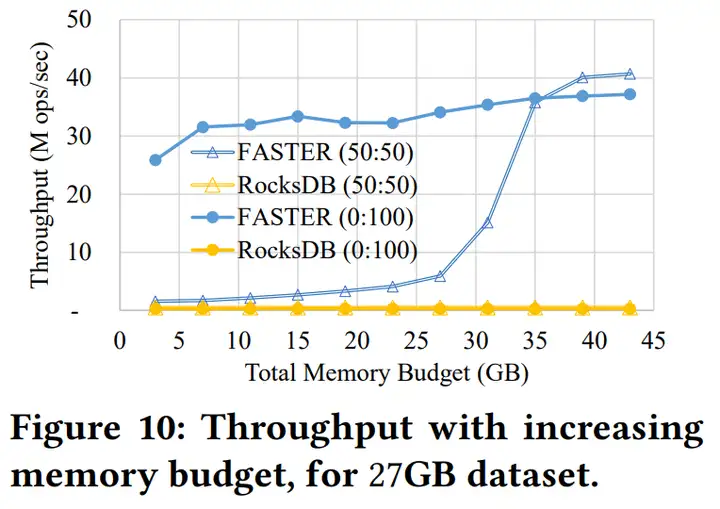
技术细节Hash主索引
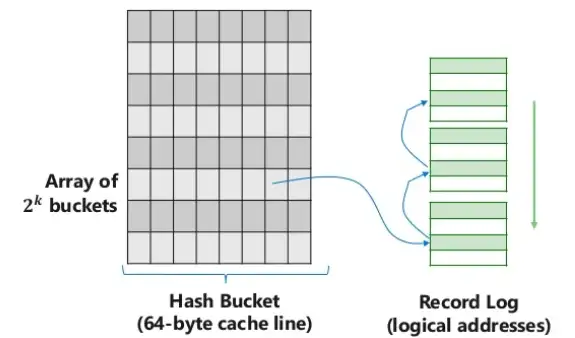
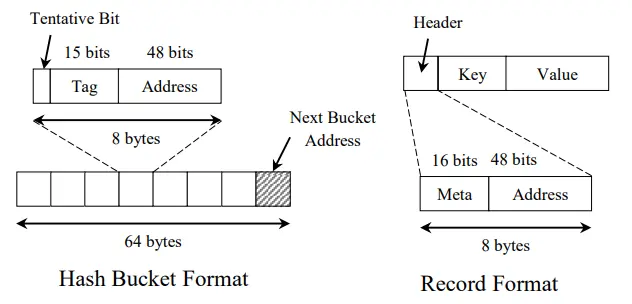
Hash索引的桶大小是64字节(cache line的大小),每个桶存8个地址,即64bit,支持Atomic更新,即CAS每个地址,64bit中 - 只用48bit来存储记录的地址,在Intel平台的机器上这是足够的。
- 15bit的tag保存key的hash值低15位,桶中的8个地址的8个tag保证唯一,有了这个tag,一定程度地减少了hash冲突检查 - 也就是说,bucket_offset + tag唯一标识一个冲突链
- 最高位1bit用于一些场景下的并发控制Record存储了变长key、value,其中还有一个64bit的Header,一方面这个Header可以存储地址,形成单向链表,另一方面64bit可以原子更新的,因此这个链表可以是无锁(latch-free)并发读写的。
无锁(Latch-free)读写读、删除,计算key的hash值,找到hash_bucket_offset、tag,找到冲突链表,找到对应的Record,进行读、删除RMW(read-modify-write)还是有些区别,这里只看insert,如下图,两个线程并发,都往相同的tag插入新记录,插入记录时,线程通过CAS修改tag所在的8字节,若失败说明有其他线程已经插入,则当前重试,找到新的链表头,把当前记录插入链表头再修改桶中的地址,因为链表的header也是8字节,可以CAS原子性插入。
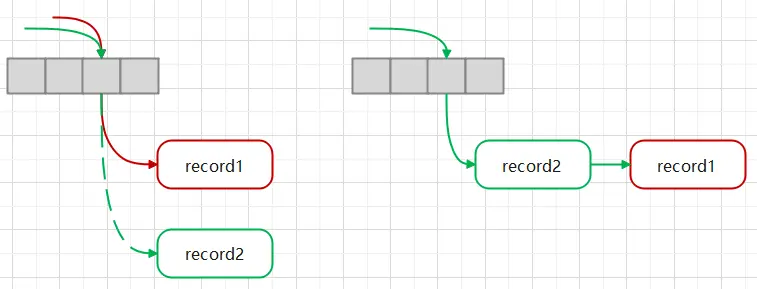
实际上还会更复杂,上述情况是有bug的,这就使用了64bit中的最高位1bit,进行并发控制(无锁),这里不展开,详情请看论文Rehash?Faster也是维护2个版本的hash表,可能也是类似Redis的渐进式rehash,这里细节待研究。
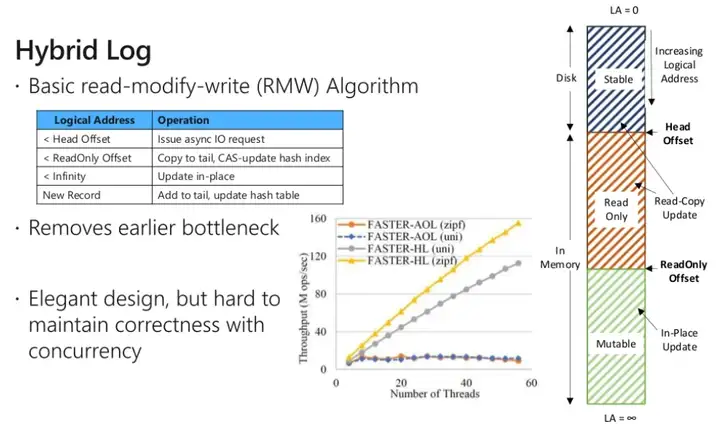
Hybrid Log从逻辑上,所有的record都是从一个连续的log中分配的,而hash中的地址就是指向log中的某个偏移地址新插入的record总是从log尾部创建,log尾部总是增长的log分为几个区域,Mutable区域总是最热的数据,head offset之前的区域则是已刷盘的,而readonly offset之前的数据虽然还在内存中,但是是可刷盘的
看其本质,其实和LSM-Tree存储是相通的(如RocksDB),图中mutable对应memtable,read only区域对应immemtable,stable对应SST按传统log,任何修改总是在mutable中拷贝出一个副本,然后修改,写密集场景下,log增长特别迅速,导致IO刷盘次数多,也带来更多的垃圾版本数据,从而引入繁重的log compact。
而hybrid log的mutable则是原地更新的,这是高性能的关键,看下面的第二张图,若不采用原地更新,性能差距是非常大的见下面的第二张图,对于RMW,当key落在不同的区域,其写策略还是不一样的虽然原地更新是高性能的关键,但是没有及时刷盘有宕机丢数据的风险,Faster如何解决?

并发控制Faster的主索引设计上,虽然支持无锁并发,但有些涉及全局资源的竞争的场景(如rehash、log的增长和回收、checkpoint、recovery等),同样的latch-free技巧是无法解决的,传统做法是引入锁,但faster认为锁太重了,因此引入了一个新的无锁的并发控制框架,即epoch protection。
这样的并发框架,要求系统满足这样的前提条件:绝大多数情况下,没有全局资源的竞争冲突,确实,绝大多数情况下faster的读写可以使用CAS无锁并发,记录级别并发Epoch不是新东西,Epoch意思上是“时钟”的概念,单调递增,像Bw-tree、Silo等其他数据库,基于epoch实现具体的MVCC、GC等并发控制问题。
而Faster则实现为一种通用的并发控制框架见下面两页PPT,大体总结如下:全局维护一个epoch E,单调递增,可以由任意一个线程推进增长每个线程维护本地epoch Et,时不时从全局的E拷贝刷新,每个线程Et刷新速度不一致
有一个安全epoch Es,总有Es < Et < E每个线程要执行某个动作时,不是立即执行,而是等到所有线程达成一致之后才能执行,即这个动作注册为回调函数+当前Et,当Et变成安全时会触发本质上,这个框架是一种线程之间的一致性同步协议,挺好奇代码怎么写的


恢复Hybrid log的性能关键是原地更新,但有宕机丢数据的风险,若引入传统WAL,那原地更新的意义不存,性能也大幅下降,如下Faster使用了组提交的WAL

分析一下,WAL瓶颈点在于,每个更新都要创建一个WAL log record,这正是原地更新要避免的点Faster受两个思想的启发(group commit和in-memory increment checkpoint),提出另一种checkpoint和恢复的方案,即concurrent prefix recovery。
从抽象上,大体思路是:每个线程维护一个逻辑上单调递增的时间序列(估计是epoch protection实现的),每个线程独立推进线程的每个写操作不用立即响应client,而是堆积,如下图中commit1和commit2之间
全局的commit点就是所有线程的当前的T值,每次刷盘时,以这样的commit边界进行刷盘,然后这些可成功响应本质上,这种方案是合并累积多次更新刷盘,而且不同线程没有竞争瓶颈但可以想象,和原来相比,时延和吞吐都受到影响,但确实比group commit的WAL好
具体的,应用到hybrid log上,如下图,这里理解本质上是找到一个log offset作为commit边界,及时刷盘
性能数据相比WAL,好很多
二级索引FasterKV作为纯粹的KV存储引擎,没有上层的模型逻辑,没有二级索引,而是微软的另一个项目FishStore,是以FasterKV作为底座的数据库,实现了模型层和二级索引,细节有待研究
FishStore/tutorial.md at master · microsoft/FishStore (github.com)其他代码量,感觉代码挺精简。
总结FasterKV的核心内容总结如下Hash主索引,特点是latch-free,全放内存Hybrid log,追加写+原地更新无锁并发控制框架,Epoch protectionCheckpoint & Recovery,WAL,CPR(concurrent prefix recovery)
二级索引?Fishstore参考FasterKV Basics - FASTER (microsoft.github.io)Research Papers - FASTER (microsoft.github.io)
Slides and Videos - FASTER (microsoft.github.io)
以上就是关于《FasterKV存储引擎介绍_存储引擎的概念及特点》的全部内容,本文网址:https://www.7ca.cn/baike/9427.shtml,如对您有帮助可以分享给好友,谢谢。