聊聊FASTER和进程内混合缓存_进程管理器怎么打开
目录:
1.fast和faster
2.faster faster
3.faster faster faster
4.fastest和faster区别
5.faster sooner区别
6.faster,faster,nice and slow
7.fast与fasten
8.fast与faster的区别
9.faster than faster
10.faster和more fast
1.fast和faster
最近有一个朋友问我这样一个问题:我的业务依赖一些数据,因为数据库访问慢,我把它放在 Redis 里面,不过还是太慢了,有什么其它的方案吗?其实这个问题比较简单的是吧?Redis 其实属于网络存储,我对照下面的这个表格,可以很容易的得出结论,既然网络存储的速度慢,那我们就可以使用
2.faster faster
内存 RAM 存储,把放 Redis 里面的数据给放内存里面就好了操作速度执行指令1/1,000,000,000 秒 = 1 纳秒从一级缓存读取数据0.5 纳秒分支预测失败5 纳秒从二级缓存读取数据7 纳秒
3.faster faster faster
使用 Mutex 加锁和解锁25 纳秒从主存(RAM 内存)中读取数据100 纳秒在 1Gbps 速率的网络上发送 2Kbyte 的数据20,000 纳秒从内存中读取 1MB 的数据250,000 纳秒
4.fastest和faster区别
磁头移动到新的位置(代指机械硬盘)8,000,000 纳秒从磁盘中读取 1MB 的数据20,000,000 纳秒发送一个数据包从美国到欧洲然后回来150 毫秒 = 150,000,000 纳秒提出这个方案以后,接下来就遇到了另外一个问题:
5.faster sooner区别
但是数据比我应用的内存大,这怎么办呢?笔者突然回想起来,似乎从来没有考虑过数据比应用大是该怎么处理,面对这种性能问题,最方便的方案就是直接扩容,在基础设施完备的公司,一般只需要提交一个工单"8G->64G"就能解决这个问题,这种成本似乎不是该考虑的事情。
6.faster,faster,nice and slow
不过对于有一些朋友的公司,因为多个方面的原因(主要还是预算),没有办法扩容机器或者体量非常大,每个实例扩容 1GB 内存,数万个容器就是非常大的开销于是我们可以采用一些内存+磁盘的缓存方式,因为现在大多数都是 SSD 磁盘,服务器 NVME 顺序读写速度早已突破 7GB/s,随机读写早已突破 100K IOPS,而且还可以通过 RAID0 进一步增加性能。
7.fast与fasten
最简单的就是我们在本地跑一个 Sqlite,然后将数据缓存到本地磁盘中,但是 Sqlite 并不是专业的 KV Store,读写性能并不是特别好KV-Store 的话还有基于 LSM-Tree 的 RocksDB、LevelDB 等等。
8.fast与faster的区别
不过那些 KV 都是 C++的实现,在 C#中集成需要 Bind 和 P/Invoke,需要自己编译比较麻烦;这让我想起了多年前微软开源 FASTER 项目文章开始之前呢还是给各位观众姥爷来一波教程资源分享哈!详细教程如下:。


9.faster than faster
资料免费自取:由于内容过多不便呈现,需要视频教程和配套源码的小伙伴,可点击下方链接个人说明处自取资料也可直接点击下方卡片:点击后可自动复制威芯号,并跳转到威芯得辛苦大家自行搜索威芯号添加内容已做打包,添加后直接发送注意查收!。
10.faster和more fast
点击卡片,复制微信号添加 免费领取干货FASTER项目如其名,FASTER 是目前蓝星最快的 KV-Store(开源的项目中),根据论文中的性能表现,它可以实现1.6 亿次操作/秒,当然这一切也是有代价的,就是它目前只支持简单的几种操作,Read、Upser、RMW 和 Delete,不过这已经够了,毕竟在缓存场景这些操作就足够了。

在它 2018 年开源和论文发表时,我就有关注,不过当时它的 API 易用性不够,另外 C#版本存在一些问题,所以一直都没有体验它,现在它经过几年的迭代,易用性得到了很大的提高,一些之前存在的问题也已经修复。
笔者简单的体验了一下它,可以说这是我使用过比较复杂的的 KV-Store 了,从它的 API 使用风格来说,它的设计的目的只有一个,那就是性能简单体验 FASTER具体的使用详情大家可以直接看官方文档,Github 开源地址和文档在文末给出,需要详细了解的可以查看文档。
首先就是安装 NuGet 包: 然后下面简单的几行代码就可以把 Demo 运行起来了,它支持 In-Memroy(内存模式)和混合模式。
和对数据库操作需要创建链接一样,它的维度是session,注意这个session就代表一个线程对它进行读写,如果多线程场景,那么每个线程对应的session应该要不一致,要单独创建,当然我们也可以把它池化。
// 内存模式 using var fasterKvSetting = new FasterKVSettings(null); // 混合模式 using var fasterKvSetting = new FasterKVSettings("./faster-query"); // 创建fasterKv Store using var fasterKv = new FasterKV(fasterKvSetting); var session = fasterKv.For(new SimpleFunctions()).NewSession(); // 准备一个utf-8字符 var str = "yyds"u8.ToArray(); // 写入 session.Upsert(1024, str); // 读取 var result = session.Read(1024); Console.WriteLine($"{Encoding.UTF8.GetString(result.output)}");
输出结果就是yyds另外也有丰富的参数可以调整内存占用,以下列出了几个相关的内存占用参数,当然,更低的内存使用,意味着更多的使用磁盘空间,性能也就会下降的越多:IndexSize: 主 Hash 索引的大小,以字节为单位(四舍五入为 2 的幂)。
最小大小为 64 字节MemorySize: 表示混合日志的内存部分的大小(四舍五入为 2 的幂)注意,如果日志指向类键或值对象,则此大小仅包括对该对象的 8 字节引用日志的旧部分溢出到存储中LogSettings。
: 这些是几个与日志相关的设置,例如页面大小的 PageSizeReadCacheEnable: 是否为存储提供并启用了单独的读缓存ReadCacheMemorySize: 读缓存内存占用大小,ReadCachePageSize。
: 读缓存页面大小跑个分试试那么 FASTER 到底有多强呢?笔者构建了一个测试,和我们常用的ConcurrentDictionary做比较,那是我能找到在.NET 平台上差不多的东西,按道理来说我们应该和 RocksDB、LevelDB 来比较。
ConcurrentDictionary应该是.NET 平台上性能最好的纯内存 KV Store 了,严格来说它和 FASTER 并不是不能相提并论,而且受制于笔记本的性能,无法做大数量的测试,要知道 FASTER 的场景是大型数据集
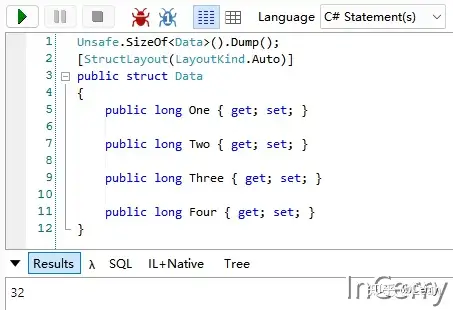
。为了方便的统计内存占用,我构建了一个结构体类型,如下所示,它应该占用 32 字节:
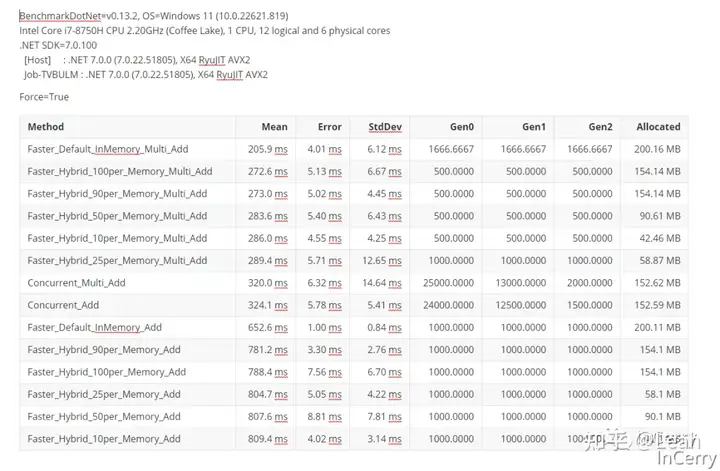
Add 测试我分别构建了不同的场景来测试 Add 性能,测试的构建如下所示:ConcurrentDictionary 单线程模式FasterKV 内存+磁盘混合 10~100%内存占用模式FasterKV 纯内存模式
以上模式的 6 个线程并发访问模式代码如下所示:[GcForce] [Orderer(SummaryOrderPolicy.FastestToSlowest)] [MemoryDiagnoser] [HtmlExporter] public class AddBench { private const int ThreadCount = 6; private const int NumCount = 200_0000; private ConcurrentDictionary _concurrent; [MethodImpl(MethodImplOptions.AggressiveInlining)] private static async Task FasterInternal(double percent, bool inMemory = false, bool multi = false) { FasterKVSettings kvSetting; if (inMemory) { kvSetting = new FasterKVSettings(null); } else { // 总计内存大小 总数 * (key + 每个Data需要占用的内存) var dataByte = NumCount * (Unsafe.SizeOf() + 8 + 8); // 计算memorySize 计划只使用{percent * 100}%的内存 需要是2的次幂 var memorySizeBits = (int) Math.Ceiling(Math.Log2(dataByte * percent)); // 根据数量计算IndexSize 需要是2的次幂 var numBucketBits = (int) Math.Ceiling(Math.Log2(NumCount)); kvSetting = new FasterKVSettings("./faster-add", deleteDirOnDispose: true) { IndexSize = 1L << numBucketBits, MemorySize = 1L << memorySizeBits }; // 不分页 kvSetting.PageSize = kvSetting.MemorySize; } using var fkv = new FasterKV(kvSetting); if (multi) { await FasterMultiThread(fkv); } else { FasterSingleThread(fkv); } kvSetting.Dispose(); } [MethodImpl(MethodImplOptions.AggressiveInlining)] private static void FasterSingleThread(FasterKV fkv) { using var session = fkv.For(new SimpleFunctions()).NewSession(); for (int i = 0; i < NumCount; i++) { session.Upsert(i, new Data()); } session.CompletePending(true); } [MethodImpl(MethodImplOptions.AggressiveInlining)] private static async Task FasterMultiThread(FasterKV fkv) { const int perCount = NumCount / ThreadCount; var tasks = new Task[ThreadCount]; for (var i = 0; i < ThreadCount; i++) { var i1 = i; var session = fkv.For(new SimpleFunctions()) .NewSession(); tasks[i] = Task.Run(() => { var j = i1 * perCount; var length = j + perCount; for (; j < length; j++) { session.Upsert(j, new Data()); } session.CompletePending(true); }); } await Task.WhenAll(tasks); } [Benchmark] public async Task Faster_Hybrid_10per_Memory_Add() { await FasterInternal(0.10); } [Benchmark] public async Task Faster_Hybrid_25per_Memory_Add() { await FasterInternal(0.25); } [Benchmark] public async Task Faster_Hybrid_50per_Memory_Add() { await FasterInternal(0.50); } [Benchmark] public async Task Faster_Hybrid_90per_Memory_Add() { await FasterInternal(0.90); } [Benchmark] public async Task Faster_Hybrid_100per_Memory_Add() { await FasterInternal(1.0); } [Benchmark] public async Task Faster_Default_InMemory_Add() { await FasterInternal(0, true); } [Benchmark] public async Task Faster_Hybrid_10per_Memory_Multi_Add() { await FasterInternal(0.10, multi: true); } [Benchmark] public async Task Faster_Hybrid_25per_Memory_Multi_Add() { await FasterInternal(0.25, multi: true); } [Benchmark] public async Task Faster_Hybrid_90per_Memory_Multi_Add() { await FasterInternal(0.90, multi: true); } [Benchmark] public async Task Faster_Hybrid_100per_Memory_Multi_Add() { await FasterInternal(1.0, multi: true); } [Benchmark] public async Task Faster_Hybrid_50per_Memory_Multi_Add() { await FasterInternal(0.50, multi: true); } [Benchmark] public async Task Faster_Default_InMemory_Multi_Add() { await FasterInternal(0, true, true); } [Benchmark] public void Concurrent_Add() { _concurrent = new ConcurrentDictionary(1, NumCount); for (long i = 0; i < NumCount; i++) { _concurrent.TryAdd(i, new Data()); } } [Benchmark] public async Task Concurrent_Multi_Add() { const int perCount = NumCount / ThreadCount; var tasks = new Task[ThreadCount]; _concurrent = new ConcurrentDictionary(1, NumCount); for (var i = 0; i { var j = i1 * perCount; var length = j + perCount; for (; j < length; j++) { _concurrent.TryAdd(j, new Data()); } }); } await Task.WhenAll(tasks); } }
结果如下所示:FASTER 的多线程写入性能非常不错,而且似乎使用内存的多少对写入性能影响不是很大单线程的话 FASTER 整体是不如 ConcurrentDictionary 的FASTER 确实是能节省内存,设置混合模式时,相较 ConcurrentDictionary 节省 60%的内存
Query 测试Query 测试我一共创建了 100W 条记录,然后测试了如下场景:单线程读取多线程读取[GcForce] [Orderer(SummaryOrderPolicy.FastestToSlowest)] [MemoryDiagnoser] [HtmlExporter] public class QueryBench { public const int Threads = 6; public const int NumCount = 100_0000; private static readonly Random Random = new(NumCount); private static readonly long[] RandomIndex = Enumerable.Range(0, 1000).Select(i => Random.NextInt64(0, (int)(NumCount * 0.10))).ToArray(); private static readonly ConcurrentDictionary Concurrent; private static readonly FasterKV FasterKvHybrid; private static readonly FasterKV FasterKvInMemory; private static readonly ClientSession HybridSession; private static readonly ClientSession InMemorySession; static QueryBench() { // 初始化字典 GC.Collect(); var heapSize = GC.GetGCMemoryInfo().HeapSizeBytes; Concurrent = new ConcurrentDictionary(Threads, NumCount); for (long i = 0; i < NumCount; i++) { Concurrent.TryAdd(i, new Data()); } Helper.PrintHeapSize("Concurrent", heapSize); // 初始化混合FasterKv heapSize = GC.GetGCMemoryInfo().HeapSizeBytes; // 总计内存大小 总数 * (key + 每个Data需要占用的内存) var dataByte = NumCount * (Unsafe.SizeOf() + 8 + 8); // 计算memorySize 计划只使用50%的内存 需要是2的次幂 var memorySizeBits = (int) Math.Ceiling(Math.Log2(dataByte * 0.5)); // 根据数量计算IndexSize 需要是2的次幂 var numBucketBits = (int) Math.Ceiling(Math.Log2(NumCount)); var kvHybridSetting = new FasterKVSettings("./faster-query", deleteDirOnDispose: true) { IndexSize = 1L << numBucketBits, MemorySize = 1L << memorySizeBits }; // 32分页 kvHybridSetting.PageSize = kvHybridSetting.MemorySize / 32; Console.WriteLine($"memorySizeBits:{memorySizeBits},numBucketBits:{numBucketBits},{kvHybridSetting}"); FasterKvHybrid = new FasterKV(kvHybridSetting); HybridSession = FasterKvHybrid.For(new SimpleFunctions()).NewSession(); for (long i = 0; i < NumCount; i++) { HybridSession.Upsert(i, new Data()); } HybridSession.CompletePending(true); Helper.PrintHeapSize("Faster Hybrid", heapSize); // 初始化In Memory GC.Collect(); heapSize = GC.GetGCMemoryInfo().HeapSizeBytes; var inMemorySetting = new FasterKVSettings(null); FasterKvInMemory = new FasterKV(inMemorySetting); InMemorySession = FasterKvInMemory.For(new SimpleFunctions()).NewSession(); for (long i = 0; i < NumCount; i++) { InMemorySession.Upsert(i, new Data()); } InMemorySession.CompletePending(true); Helper.PrintHeapSize("Faster In Memory", heapSize); } [Benchmark] public async Task Faster_Hybrid_Multi_Query() { var tasks = new Task[Threads]; for (int i = 0; i < Threads; i++) { var session = FasterKvHybrid.For(new SimpleFunctions()) .NewSession(); tasks[i] = Task.Run(() => { Data data = default; for (int j = 0; j < RandomIndex.Length; j++) { session.Read(ref RandomIndex[j], ref data); } }); } await Task.WhenAll(tasks); } [Benchmark] public void Faster_Hybrid_1Thread_Query() { Data data = default; for (long j = 0; j < RandomIndex.Length; j++) { HybridSession.Read(ref RandomIndex[j], ref data); } } [Benchmark] public async Task Faster_InMemory_Multi_Query() { var tasks = new Task[Threads]; for (int i = 0; i < Threads; i++) { var session = FasterKvInMemory.For(new SimpleFunctions()) .NewSession(); tasks[i] = Task.Run(() => { Data data = default; for (int j = 0; j < RandomIndex.Length; j++) { session.Read(ref RandomIndex[j], ref data); } }); } await Task.WhenAll(tasks); } [Benchmark] public void Faster_InMemory_Query() { Data data = default; for (long j = 0; j < RandomIndex.Length; j++) { InMemorySession.Read(ref RandomIndex[j], ref data); } } [Benchmark] public void Concurrent_Query() { for (long j = 0; j < RandomIndex.Length; j++) { Concurrent.TryGetValue(RandomIndex[j], out _); } } [Benchmark] public async Task Concurrent_Multi_Query() { var tasks = new Task[Threads]; for (int i = 0; i { for (long j = 0; j < RandomIndex.Length; j++) { Concurrent.TryGetValue(RandomIndex[j], out _); } }); } await Task.WhenAll(tasks); } }
结果如下所示,这里是 100%读的场景:似乎内存不足对于 FASTER 的读性能影响挺大的,这也是必然的结果,毕竟 SSD 再快也没有内存快另外根据我的测试结果来说,FASTER 纯内存模式在 100%纯读取的场景没有 Concurrent 那么快
官方测试结果由于我的测试结果不是很准确,我又继续查找有没有其它的性能评测的结果,并没有找到什么有价值的于是从论文和 Wiki 中找到了一些数据,和大家解读一下我比较感兴趣的部分Faster 论文这是在 Faster 2018 年的论文中提到的一些,如下所示: 。
https://www.microsoft.com/en-us/research/uploads/prod/2018/03/faster-sigmod18.pdf
上图是单线程情况下,跑 YCSB-A(uniform)数据集和 YCSB-A(Zipf)数据集的结果可以看到在单线程的场景,FASTER 速度远超于同类 Intel TBB、MassTree、RocksDB 等数据库。
文中的 0:100、50:50、100:0 是代表全写、50%写 50 读、全读的场景另外 FASTER 支持 Read-Modify-Write,RMW 就是代表进行这个操作的性能Yahoo! Cloud Serving Benchmark (YCSB) 是一个 Java 语言实现的主要用于云端或者服务器端的数据库性能测试工具,其内部涵盖了常见的 NoSQL 数据库产品,如 Cassandra、MongoDB、HBase、Redis 等等。
在多线程的情况下,FASTER 的读性能达到了惊人的 1.6 亿/s。
上图是在单核和双核的更新性能数据,可以看到 FASTER 蓝色的线是远超同类产品,特别是在线程数变多以后,其它都是下降趋势,它是程上升趋势。
上图是表示,分别在使用 5GB~45GB 内存加载 27GB 数据时的吞吐量,分别是 50%的读写,和 100%的写可以看到写性能几乎不受内存大小的影响,这也佐证了我的测试结果C# FasterKV 性能测试。
这是翻阅微软 Github 项目时,看到专门针对于 C#的 FasterKV 和 ConcurrentDictionary 的测试不过它只有纯内存模式的测试,并不包含内存+硬盘混合模式 https://。
github.com/microsoft/FASTER/wiki/Performance-of-FASTER-in-C%23#introduction
这里它使用了一台 36 核 72 线程的 512GB 服务器进行测试。分别测试大型数据集(2.5 亿个键)和小型数据集(250 万个键)进行实验。大数据集场景
上图是大型数据集的加载速度,可以发现 FASTER 的加载速度确实很快,是 ConcurrentDictionary 的好 10~50 倍,性能还在上涨。
上图是 100%写入时的场景,随着线程数量的增加还在上涨,远超 ConcurrentDictionary,这和我们的测试结果相符合。
上图是分别进行 50%读写的场景,可以发现吞吐量还是非常的不错的。
如果是 100%纯度的场景,还是 ConcurrentDictionary 会更好不过这也不是 FASTER 的适用场景,因为在这样的工作负载中不存在并发瓶颈,也不存在对内存的写操作这两个系统都受到读取缓存失败次数的限制,并具有相似的性能。
上图显示了来自上面 72 个线程的数据,以 x 轴上的读取百分比表示当您的工作负载中涉及到一小部分更新时,FASTER 提供了数量级更好的性能随着非常高的读取百分比超过 90% ,两个系统的性能开始像预期的那样趋于一致。
Int64 类型的 Key因为 ConcurrentDictionary 对(Int32、Int64)类型有特殊的优化,所以将 Key 的类型替换为 Int64 做了下面的测试。
可以看到(Int32、Int64)类型确实让 ConcurrentDictionary 更快了,不过在有写入操作的场景,还是 FASTER 更胜一筹这也解释了一些我们上面的测试中,为什么 ConcurrentDictionary 在读场景那么快的原因之一,就是我们用了 Int64 作为 Key。
小数据集场景这个场景我就不解读了,和大数据集场景表现基本一致。
总结通过对 FASTER 的测试和翻阅论文,从目前的结果来说,在以下单机场景比较适合使用 FASTER:只需要简单的 Read、Write 和 Read-Modify-Write 的场景非 100%读取操作的场景,这种场景由于没有锁争用,FASTER 不如字典
另外 FASTER 也提供了 Server 版本,可以通过网络访问另外在我的测试中,读取性能和官方测试有较大的出入,感觉是使用方法和参数上出了问题,因为 FASTER 整体还是比较复杂,笔者需要更多的时间去了解原理和测试。
回到最开始的那个问题,FASTER 可以作为内存+磁盘进程内缓存使用吗?我的答案是可以,它虽然比不上纯内存的 ConcurrentDictionary,但是有着远超 RocksDB 等同类 KV Store 的性能。
不过它不适合 100%读的缓存,最好是那些既有读,又有写的场景;如果需要 100%读,可能我们需要看看其它的工具是否能满足我们的需求原文链接:聊聊FASTER和进程内混合缓存。
以上就是关于《聊聊FASTER和进程内混合缓存_进程管理器怎么打开》的全部内容,本文网址:https://www.7ca.cn/baike/9429.shtml,如对您有帮助可以分享给好友,谢谢。