faster-RCNN系列总结_faster rcnn rpn
目录:
1.faster rcnn介绍
2.faster rcnn+fpn
3.faster rcnn rpn详解
4.一文读懂faster rcnn知乎
5.faster rcnn demo
6.faster rcnn roi
7.faster rcnn原理详解
8.faster rcnn flops
9.faster rcnn onestage
10.faster rcnn详解
1.faster rcnn介绍
RCNNRCNN是经典的两阶段目标检测网络,分为目标候选框ROI提取和CNN分类预测两个阶段,相对于传统的检测算法,其改进点在于:1)对预测的bbox进行回归矫正,2)使用CNN网络进行特征提取,正在意义上的将目标检测带入深度学习时代。
2.faster rcnn+fpn
基于下图的网络结构,对RCNN的网络流程进行介绍:
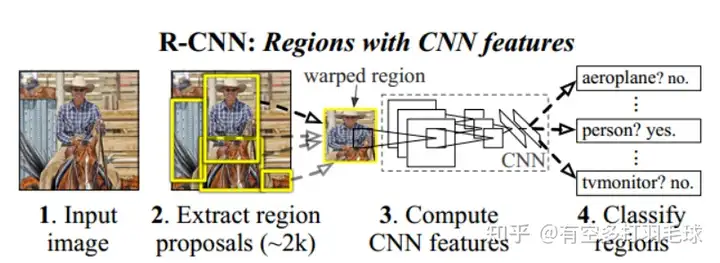
3.faster rcnn rpn详解
RCNN网络结构1)输入image,使用selective search算法提取2000个目标候选框2)对每个候选框进行resize到固定大小227*2273)预训练一个CNN网络,进行候选框的特征提取,全连接层输出
4.一文读懂faster rcnn知乎
4)训练svm作为分类器,对cnn提取的特征进行分类预测类别5)对预测为目标类别的bbox进行回归调整存在问题:1)使用传统的selective search算法提取目标候选框,算法的思路是分割与聚合,时间复杂度高,处理时间是秒级
5.faster rcnn demo
2)候选框rezise到固定大小,会损失图像信息,降低模型精度;主要原因是CNN后面接了两个全连接层,全连接层的输入参数固定导致CNN的输入大小固定3)每张图都会产生2k个候选框,虽然选取出来的候选框可以并行计算,但计算量大耗时,同时候选框之间有位置重叠,导致卷积重复;(cnn选用vggnet,单张图推理过程耗时47s)
6.faster rcnn roi
4)训练过程分割,独立训练,例如CNN、svm分类器、bbox回归器等都需要单独训练Fast-RCNN相对于RCNN网络,fast-rcnn的改进点主要体现在:1)卷积共享,全图进行一次卷积特征提取,然后再与候选框特征映射,降低耗时;2)使用SPPnet(空间金字塔池化)对映射的feature-map进行池化,再输入到fc层,解决了cnn网络的输入限制,避免图像信息损失。
7.faster rcnn原理详解
fast-RCNN网络结构如下图所示:
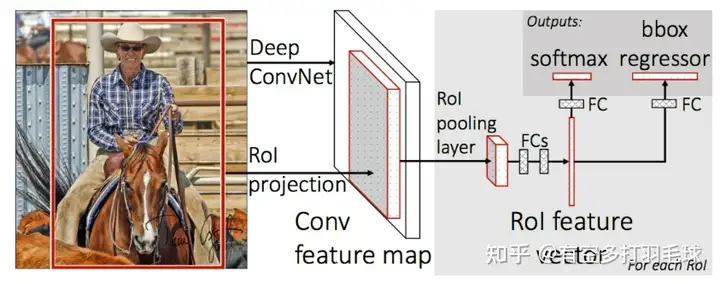
8.faster rcnn flops
Fast-RCNN网络推理流程:1)将image和使用selective search提取到的候选框输入到网络2)训练CNN对image进行特征提取,得到image全图的feature map;CNN选用vgg16,输出低5层的feature map
9.faster rcnn onestage
3)特征映射,将每个候选框映射到feature map上,得到每个候选框对应的feature map4)使用ROI池化,对每个feature map进行处理,得到统一大小的feature,再送入到fc层进行特征处理
10.faster rcnn详解
5)使用softmax作为分类器,替代原始的svm分类器,连接在fc层后面,输出对应的类别概率6)bbox回归器对ss提取到的候选框进行调整关键步骤细节关于原图到特征图上的位置映射,可参考博客:原始图片中的ROI如何映射到到feature map? - 知乎 (zhihu.com)
看着有点绕,直观解释一下经过一层卷积之后坐标点之间的变换:
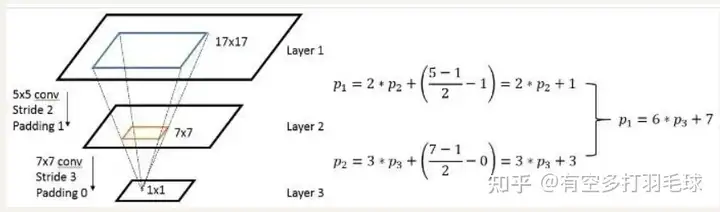
特征图坐标映射公式化表达为:p1=s*p2+((k-1)/2 - p),其中p1表示前一层的坐标,p2表示后一层的坐标,s、k、p分别表示步骤、卷积核大小和padding,则其几何位置变换表示为:s*p2:表示p2映射到前一层输入卷积时,对应卷积核在输入图上的左上角位置;(k-1)/2表示卷积核大小的一半,相加之后表示将左上角的点移动到卷积核中间位置;p表示padding,如果对原图进行padding,则应该将坐标点再向外围移动,因此减去p。
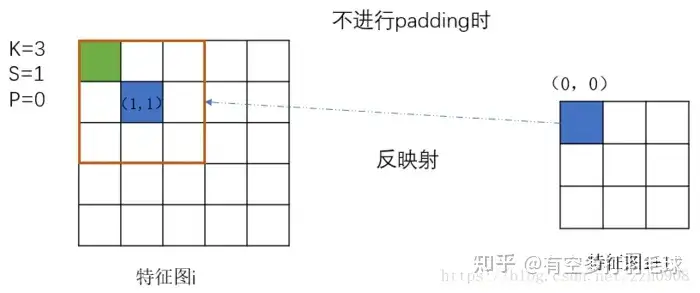
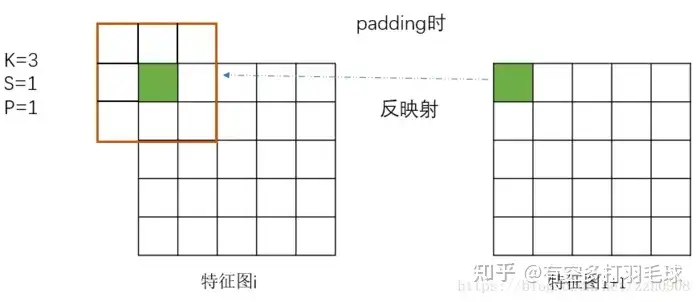
结合上图理解特征图之间的坐标转换更直观,而在fast-RCNN上原图与特征图的映射,本质就是多层特征图的级联操作,套用公式即可得到原图在特征图上的映射关系关于ROI池化,主要是对不同大小的region proposal进行池化,得到相同大小的feature map,以送入fc层。
其主要原理是将每个region proposal划分成固定的的H*W个网格,对每个网格进行最大池化,得到的特征图均为H*W池化过程参考下图,一目了然
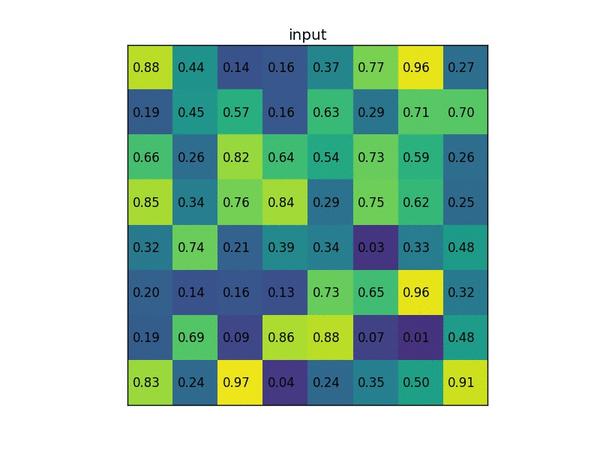
ROI池化损失函数损失函数包括分类损失和回归损失两个部分,其中分类损失使用log loss,计算每个类别以及背景对应的概率值,即:Lcls=−log(pu)L_{cls} = -log(p_{u}) ; 回归损失使用smooth L1 loss,计算左上角坐标x、y和bbox的h、w,即
Lloc=∑i=14g(tiu−vi)L_{loc} = \sum_{i=1}^{4}{g(t_{i}^{u} - v_{i})} ,
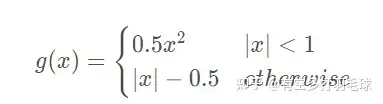
总损失函数为:
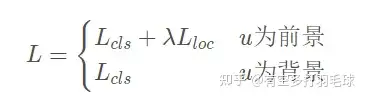
对于损失函数权重问题,回归损失具有更大的权重,其原因是selective search选出的2000个框都会有分类结果,但回归只针对分类为前景的目标,对于背景不会处理,因此总的损失函数里面分类损失项远大于回归损失项,为了平衡两者,需要给回归赋予更大的权重,使得训练结果在分类和回归上表现的一样好。
存在问题:1)仍然使用ss提取region proposal(耗时2~3s),推理时间没有下降2)无法满足实时应用,没有完全实现端到端训练测试Faster-RCNN针对fast-rcnn的耗时问题,并提升网络性能,faster-rcnn的改进点主要在于:1)提出rpn卷积网络替代传统的ss方式,将耗时从秒级下降到毫秒级;2)提出基于anchor的方式进行目标检测,通过两次bbox回归进行矫正,提高检测精度;3)实现了端到端的训练推理
整体结构和训练推理流程
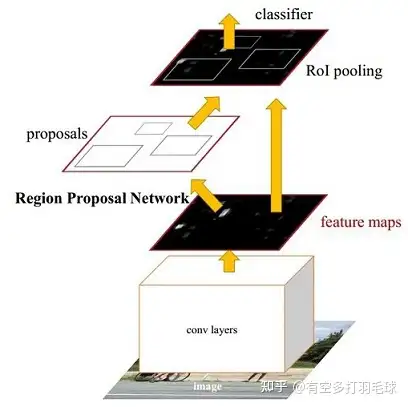
Faster-RCNN整体结构结合上图,可清晰看出完整的推理流程:1)conv layers对输入的image进行特征提取,生成feature maps,用于后续的RPN进行生成region proposal和fc层的分类回归;全流程进行一次卷积特征提取,共享feature maps
2)Region Proposal Network在生成的feature maps上进行region proposal提取,使用softmax判断anchor是positive or negative,然后使用bbox回归对anchor的位置进行调整
3)ROI pooling对产生的大小不同的propoal对应的feature map进行处理,输出统一尺度的feature map,送入后续的fc层4)classifier对fc层处理过的proposal特征进行类别预测,并对positive类别的bbox进行回归矫正
RPN介绍
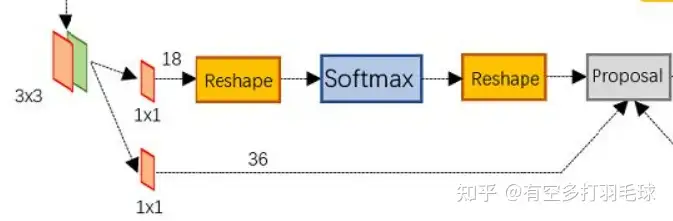
RPN结构RPN的输入是cnn提取的feature map,假设其维度为W*H*C,使用3*3卷积在feature map上提取W*H个proposal,记为anchor,对于每个anchor,假设可对应原图上3中尺寸,9个不同大小的anchor box,每个anchor box都输出对应的位置信息x、y、w、h,则很容易理解上图的流程:
1)使用3*3卷积提取的anchor后,上面的分支进行类别判断,即连接1*1卷积,输出维度为18的特征,表示9个anchor box为前景 or 背景2)下面的分支进行anchor box的位置回归,每个anchor box输出4个位置信息x、y、w、h,每个anchor包含9个anchor box,因此输出特征维度为36
3)anchor box筛选,删除超过原图边界的anchor box,删除过小的anchor box,再使用NMS进行过滤;在训练anchor属于前景与背景的时候,是在一张图中,随机抽取了128个前景anchor与128个背景anchor
RPN训练时的正负样本选取方式有:正例选取:1)与任意gt的IoU值最大的作为正例,选取的正例较少 2)与任意gt的IoU值大于0.7的作为正例负例选取:anchors与所有gt的IoU值小于0.3作为负例
RPN损失函数:
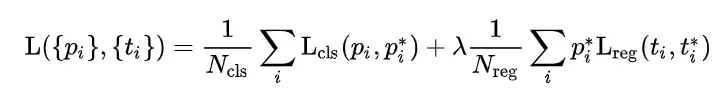
上式中为分类损失和回归损失之和,其中分类损失使用交叉熵损失,分别计算预测类别概率和真实标签(0,1)的差值;回归损失使用smooth L1损失,分别计算bound box对应的4个位置信息和真实标签的差值,在回归损失中乘以真实标签的类别概率,表示回归损失只计算类别为前景的目标,背景框不考虑
训练方式Faster R-CNN的训练流程大致为: 1) 首先通过RPN生成约20000个anchor(53×49×9) 2) 对20000个anchor进行第一次边框修正,得到修订边框后的proposal。
3) 对超过图像边界的proposal的边进行clip,使得该proposal不超过图像范围 4) 忽略掉长或者宽太小的proposal 5) 将所有proposal按照前景分数从高到低排序,选取前12000个proposal。
6) 使用阈值为0.7的NMS算法排除掉重叠的proposal 7) 针对上一步剩下的proposal,选取前2000个proposal进行分类和第二次边框修正对于Faster R-CNN的训练,作者采用 RPN和Fast R-CNN交替训练:。
1) 使用在ImageNet上预训练的模型初始化共享卷积层并训练RPN 2) 使用上一步得到的RPN参数生成RoI proposal再使用ImageNet上预训练的模型初始化共享卷积层,训练Fast R-CNN部分(分类器和RoI边框修订)。
3) 将训练后的共享卷积层参数固定,同时将Fast R-CNN的参数固定,训练RPN(从这一步开始,共享卷积层的参数真正被两大块网络共享) 4) 同样将共享卷积层参数固定,并将RPN的参数固定,训练Fast R-CNN部分。
存在问题:1)对于提取出来的region proposal,仍需要单个进行分类回归,2000个proposal的处理还是比较耗时的关于Faster-RCNN的详细介绍,可参考下面两篇文章:白裳:一文读懂Faster RCNN
9612 赞同 · 411 评论文章
李大山:Faster_RCNN理解10 赞同 · 2 评论文章
以上就是关于《faster-RCNN系列总结_faster rcnn rpn》的全部内容,本文网址:https://www.7ca.cn/baike/9434.shtml,如对您有帮助可以分享给好友,谢谢。