语言模型“不务正业”做起目标检测,性能还比DETR、Faster R-CNN更好|Hinton团队研究_目标检测与语义分割
目录:
1.目标检测,语义分割
2.语言模型的任务
3.语言模型lm
4.语言模型训练方法
5.语言模型在语音识别中的应用
6.语言模型plug
7.语言模型作用
8.目标检测与语义分割
9.目标检测语义分割一起
10.目标检测和语义分割哪个简单
1.目标检测,语义分割
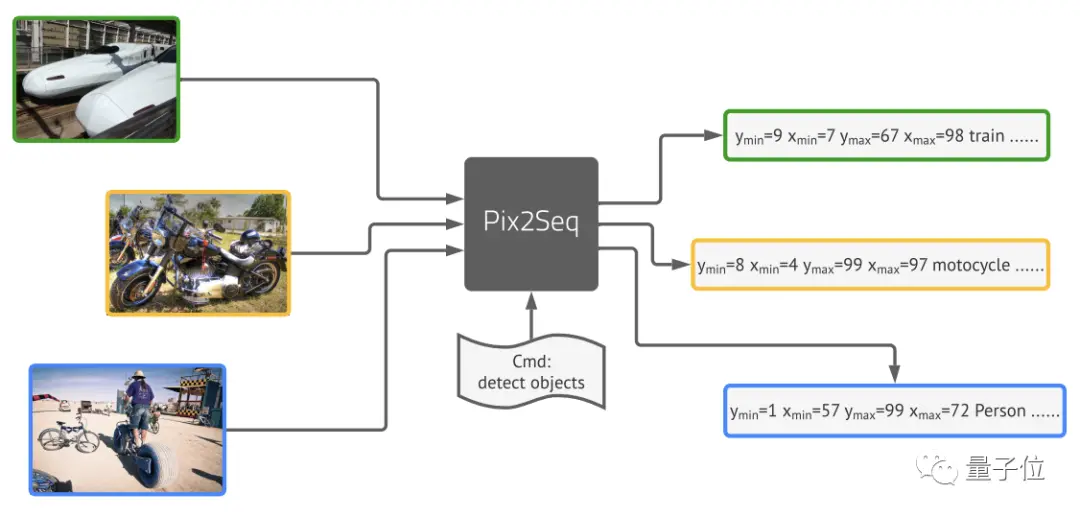
长期以来,CNN都是解决目标检测任务的经典方法就算是引入了Transformer的DETR,也是结合CNN来预测最终的检测结果的但现在,Geoffrey Hinton带领谷歌大脑团队提出的新框架Pix2Seq。
2.语言模型的任务
,可以完全用语言建模的方法来完成目标检测。

3.语言模型lm
打开凤凰新闻,查看更多高清图片团队由图像像素得到一种对目标对象的“描述”,并将其作为语言建模任务的输入。然后让模型去学习并掌握这种“语言”,从而得到有用的目标表示。
4.语言模型训练方法
最后取得的结果基本与Faster R-CNN、DETR相当,对于小型物体的检测优于DETR,在大型物体检测上的表现也比Faster R-CNN更好,接下来就来具体看看这一模型的架构从物体描述中构建序列Pix2Seq的处理流程主要分为四个部分:
5.语言模型在语音识别中的应用
图像增强序列的构建和增强编码器-解码器架构目标/损失函数

6.语言模型plug
首先,Pix2Seq使用图像增强来丰富一组固定的训练实例然后是从物体描述中构建序列一张图像中常常包含多个对象目标,每个目标可以视作边界框和类别标签的集合将这些对象目标的边界框和类别标签表达为离散序列,并采用。
7.语言模型作用
随机排序策略将多个物体排序,最后就能形成一张特定图像的单一序列也就是开头所提到的对“描述”目标对象的特殊语言其中,类标签可以自然表达为离散标记边界框则是将左上角和右下角的两个角点的X,Y坐标,以及类别索引c进行连续数字离散化,最终得到五个离散Token序列:。
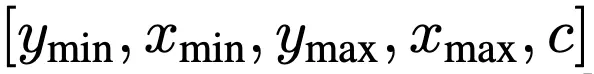
8.目标检测与语义分割
研究团队对所有目标采用共享词表,这时表大小=bins数+类别数。这种量化机制使得一个600×600的图像仅需600bins即可达到零量化误差,远小于32K词表的语言模型。

9.目标检测语义分割一起
接下来,将生成的序列视为一种语言,然后引入语言建模中的通用框架和目标函数这里使用编码器-解码器架构,其中编码器用于感知像素并将其编码为隐藏表征的一般图像,生成则使用Transformer解码器和语言建模类似,Pix2Seq将用于预测并给定图像与之前的Token,以及最大化似然损失。
10.目标检测和语义分割哪个简单
在推理阶段,再从模型中进行Token采样。为了防止模型在没有预测到所有物体时就已经结束,同时平衡精确性(AP)与召回率(AR),团队引入了一种序列增强技术:

这种方法能够对输入序列进行增广,同时还对目标序列进行修改使其能辨别噪声Token,有效提升了模型的鲁棒性在小目标检测上优于DETR团队选用MS-COCO 2017检测数据集进行评估,这一数据集中含有包含11.8万训练图像和5千验证图像。
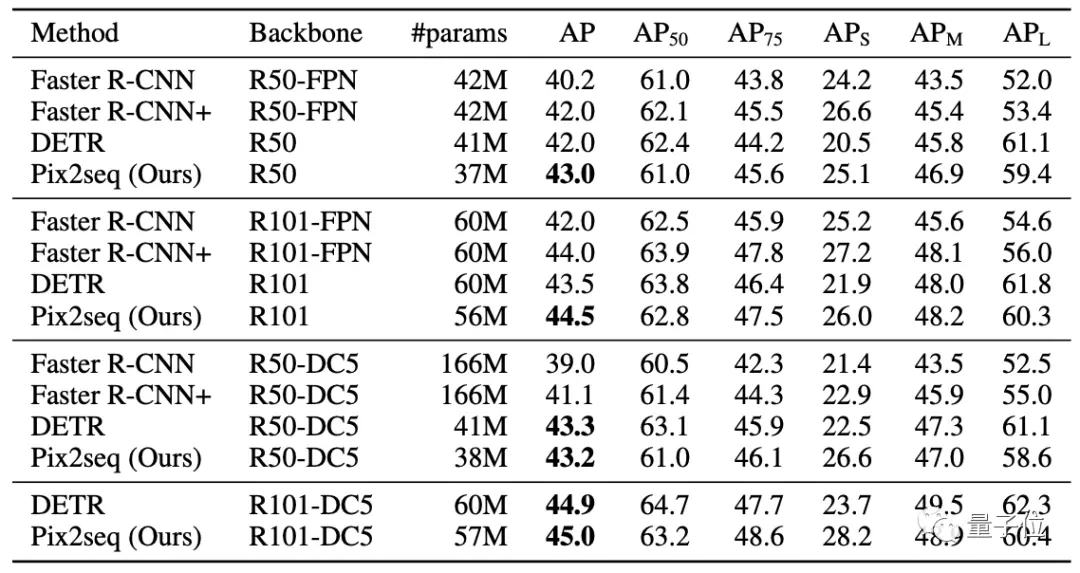
与DETR、Faster R-CNN等知名目标检测框架对比可以看到:Pix2Seq在小/中目标检测方面与Faster R-CNN性能相当,但在大目标检测方面更优而对比DETR,Pix2Seq在大/中目标检测方面相当或稍差,但在小目标检测方面更优。
一作华人这篇论文来自图灵奖得主Geoffrey Hinton带领的谷歌大脑团队一作Ting Chen为华人,本科毕业于北京邮电大学,2019年获加州大学洛杉矶分校(UCLA)的计算机科学博士学位他已在谷歌大脑团队工作两年,目前的主要研究方向是自监督表征学习、有效的离散结构深层神经网络和生成建模。

论文:https://arxiv.org/abs/2109.10852
以上就是关于《语言模型“不务正业”做起目标检测,性能还比DETR、Faster R-CNN更好|Hinton团队研究_目标检测与语义分割》的全部内容,本文网址:https://www.7ca.cn/baike/9443.shtml,如对您有帮助可以分享给好友,谢谢。