人人都能看懂的LSTM介绍及反向传播算法推导(非常详细)-反向传播算法(过程及公式推导)
1.长短期记忆网络LSTM
LSTM(Long short-term memory)通过刻意的设计来避免长期依赖问题,是一种特殊的RNN。长时间记住信息实际上是 LSTM 的默认行为,而不是需要努力学习的东西!
所有递归神经网络都具有神经网络的链式重复模块。在标准的RNN中,这个重复模块具有非常简单的结构,例如只有单个tanh层,如下图所示。
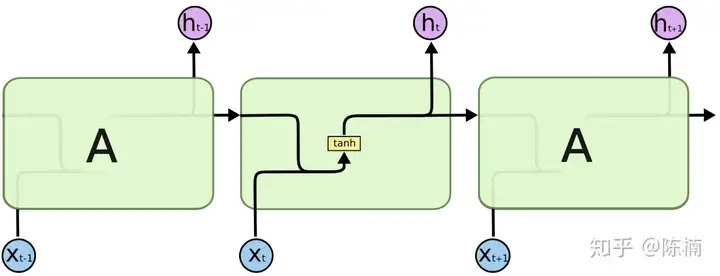
LSTM具有同样的结构,但是重复的模块拥有不同的结构,如下图所示。与RNN的单一神经网络层不同,这里有四个网络层,并且以一种非常特殊的方式进行交互。

1.1 LSTM--遗忘门

LSTM 的第一步要决定从细胞状态中舍弃哪些信息。这一决定由所谓“遗忘门层”的 S 形网络层做出。它接收 ht−1 h_{t-1} 和 xt x_t ,并且对细胞状态 Ct−1C_{t−1} 中的每一个数来说输出值都介于 0 和 1 之间。1 表示“完全接受这个”,0 表示“完全忽略这个”。
1.2 LSTM--输入门
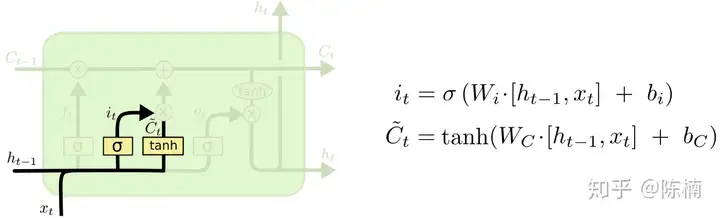
下一步就是要确定需要在细胞状态中保存哪些新信息。这里分成两部分。第一部分,一个所谓“输入门层”的 S 形网络层确定哪些信息需要更新。第二部分,一个 tanh tanh 形网络层创建一个新的备选值向量—— C~t \tilde{C}_t ,可以用来添加到细胞状态。在下一步中我们将上面的两部分结合起来,产生对状态的更新。
1.3 LSTM--细胞状态更新
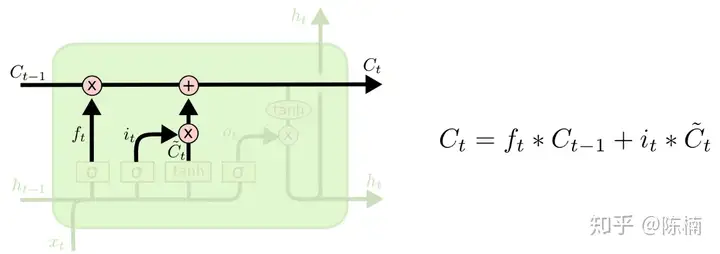
现在更新旧的细胞状态 Ct−1 C_{t−1} 更新到 Ct C_t 。先前的步骤已经决定要做什么,我们只需要照做就好。
我们对旧的状态乘以 ft f_t ,用来忘记我们决定忘记的事。然后我们加上 it⊙C~t i_t\odot\tilde{C}_t ,这是新的候选值,根据我们对每个状态决定的更新值按比例进行缩放。
1.4 LSTM--输出门
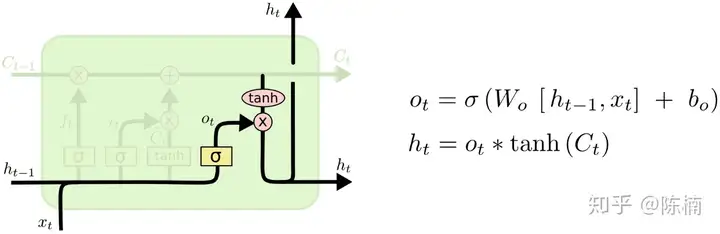
最后,我们需要确定输出值。输出依赖于我们的细胞状态,但会是一个“过滤的”版本。首先我们运行 S 形网络层,用来确定细胞状态中的哪些部分可以输出。然后,我们把细胞状态输入 tanh(把数值调整到 −1 和 1 之间)再和 S 形网络层的输出值相乘,部这样我们就可以输出想要输出的分。
2. LSTM的变种以及前向、反向传播
目前所描述的还只是一个相当一般化的 LSTM 网络。但并非所有 LSTM 网络都和之前描述的一样。事实上,几乎所有文章都会改进 LSTM 网络得到一个特定版本。差别是次要的,但有必要认识一下这些变种。
2.1 带有"窥视孔连接"的LSTM
一个流行的 LSTM 变种由 Gers 和 Schmidhuber 提出,在 LSTM 的基础上添加了一个“窥视孔连接”,这意味着我们可以让门网络层输入细胞状态。
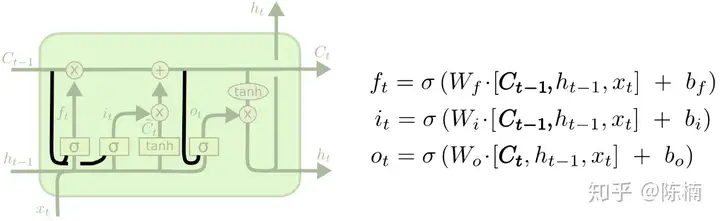
上图中我们为所有门添加窥视孔,但许多论文只为部分门添加。为了更直观的推导反向传播算法,将上图转化为下图:
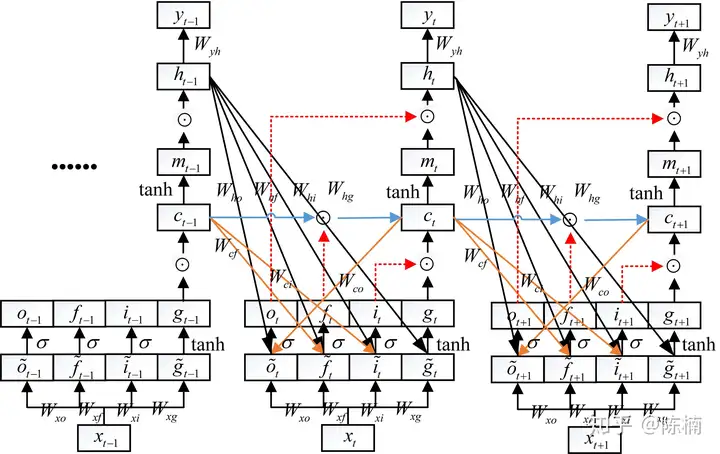
前向传播:在t时刻的前向传播公式为:
{it=σ(i~t)=σ(Wxixt+Whiht−1+Wcict−1+bi)ft=σ(f~t)=σ(Wxfxt+Whfht−1+Wcfct−1+bf)gt=tanh(g~t)=tanh(Wxgxt+Whght−1+bg)ot=σ(o~t)=σ(Wxoxt+Whoht−1+Wcoct+bo)ct=ct−1⊙ft+gt⊙itmt=tanh(ct)ht=ot⊙mtyt=Wyhht+by\left\{ \begin{array}{l} {i_t=\sigma(\tilde{i}_t)=\sigma(W_{xi}x_t+W_{hi}h_{t-1}+W_{ci}c_{t-1}+b_i)} \\ {f_t=\sigma(\tilde{f}_t)=\sigma(W_{xf}x_t+W_{hf}h_{t-1}+W_{cf}c_{t-1}+b_f) }\\ {g_t=\tanh(\tilde{g}_t)=\tanh(W_{xg}x_t+W_{hg}h_{t-1}+b_g)} \\ {o_t=\sigma(\tilde{o}_t)=\sigma(W_{xo}x_t+W_{ho}h_{t-1}+W_{co}c_{t}+b_o) }\\ {c_t=c_{t-1}\odot f_t+g_t\odot i_t}\\ {m_t=\tanh(c_t)}\\ {h_t=o_t\odot m_t}\\ {y_t=W_{yh}h_t+b_y} \end{array}\right.
反向传播:对反向传播算法了解不够透彻的,请参考陈楠:反向传播算法推导过程(非常详细),这里有详细的推导过程,本文将直接使用其结论。
已知: ∂J∂yt,∂J∂ct+1,∂J∂o~t+1,∂J∂f~t+1,∂J∂i~t+1,∂J∂g~t+1 \frac{\partial J}{\partial y_t},\frac{\partial J}{\partial c_{t+1}},\frac{\partial J}{\partial \tilde{o}_{t+1}},\frac{\partial J}{\partial \tilde{f}_{t+1}},\frac{\partial J}{\partial \tilde{i}_{t+1}},\frac{\partial J}{\partial \tilde{g}_{t+1}} ,求某个节点梯度时,首先应该找到该节点的输出节点,然后分别计算所有输出节点的梯度乘以输出节点对该节点的梯度,最后相加即可得到该节点的梯度。如计算 ∂J∂ht \frac{\partial J}{\partial h_t} 时,找到 ht h_t 节点的所有输出节点 、、yt、o~t+1、 y_t、 \tilde{o}_{t+1}、 、f~t+1、\tilde{f}_{t+1}、、i~t+1、g~t+1\tilde{i}_{t+1}、\tilde{g}_{t+1} ,然后分别计算输出节点的梯度(如 ∂J∂yt\frac{\partial J}{\partial y_t} )与输出节点对 ht h_t 的梯度的乘积(如 ∂J∂ytWyhT\frac{\partial J}{\partial y_t}W_{yh}^T ),最后相加即可得到节点 ht h_t 的梯度:
∂J∂ht=∂J∂ytWyhT+∂J∂o~t+1WhoT+∂J∂f~t+1WhfT+∂J∂i~t+1WhiT+∂J∂g~t+1WhgT\frac{\partial J}{\partial h_t}=\frac{\partial J}{\partial y_t}W_{yh}^T+\frac{\partial J}{\partial \tilde{o}_{t+1}}W_{ho}^T+\frac{\partial J}{\partial \tilde{f}_{t+1}}W_{hf}^T+\frac{\partial J}{\partial \tilde{i}_{t+1}}W_{hi}^T+\frac{\partial J}{\partial \tilde{g}_{t+1}}W_{hg}^T
同理可得t时刻其它节点的梯度:
{∂J∂ht=∂J∂ytWyhT+∂J∂o~t+1WhoT+∂J∂f~t+1WhfT+∂J∂i~t+1WhiT+∂J∂g~t+1WhgT∂J∂mt=∂J∂ht⊙ot∂J∂ct=∂J∂mtdmtdct+∂J∂ct+1⊙ft+1+∂J∂f~t+1WcfT+∂J∂i~t+1WciT∂J∂gt=∂J∂ct⊙it∂J∂it=∂J∂ct⊙gt∂J∂ft=∂J∂ct⊙ct−1∂J∂ot=∂J∂ht⊙mt}⇒{∂J∂g~t=∂J∂gt(1−gt2)∂J∂i~t=∂J∂itit(1−it)∂J∂f~t=∂J∂ftft(1−ft)∂J∂o~t=∂J∂otit(1−ot)∂J∂xt=∂J∂o~tWxoT+∂J∂f~tWxfT+∂J∂i~tWxiT+∂J∂g~tWxgT\left \{\begin{array}{l} \frac{\partial J}{\partial h_t}=\frac{\partial J}{\partial y_t}W_{yh}^T+\frac{\partial J}{\partial \tilde{o}_{t+1}}W_{ho}^T+\frac{\partial J}{\partial \tilde{f}_{t+1}}W_{hf}^T+\frac{\partial J}{\partial \tilde{i}_{t+1}}W_{hi}^T+\frac{\partial J}{\partial \tilde{g}_{t+1}}W_{hg}^T \\ \frac{\partial J}{\partial m_t} = \frac{\partial J}{\partial h_t} \odot o_t \\ \frac{\partial J}{\partial c_t} = \frac{\partial J}{\partial m_t}\frac{dm_t}{dc_t}+ \frac{\partial J}{\partial c_{t+1}}\odot f_{t+1} +\frac{\partial J}{\partial \tilde{f}_{t+1}}W_{cf}^T+\frac{\partial J}{\partial \tilde{i}_{t+1}}W_{ci}^T \\ \left. \begin{array}{l} \frac{\partial J}{\partial g_t} = \frac{\partial J}{\partial c_t}\odot i_t \\ \frac{\partial J}{\partial i_t} = \frac{\partial J}{\partial c_t} \odot g_t \\ \frac{\partial J}{\partial f_t} = \frac{\partial J}{\partial c_t} \odot c_{t-1} \\ \frac{\partial J}{\partial o_t} = \frac{\partial J}{\partial h_t} \odot m_t \end{array} \right \} \Rightarrow \left\{ \begin{array}{l} \frac{\partial J}{\partial \tilde{g}_t} = \frac{\partial J}{\partial g_t}(1-g_t^2) \\ \frac{\partial J}{\partial \tilde{i}_t} = \frac{\partial J}{\partial i_t}i_t(1-i_t) \\ \frac{\partial J}{\partial \tilde{f}_t} = \frac{\partial J}{\partial f_t}f_t(1-f_t) \\ \frac{\partial J}{\partial \tilde{o}_t} = \frac{\partial J}{\partial o_t}i_t(1-o_t) \\ \end{array}\right. \\ \frac{\partial J}{\partial x_t} = \frac{\partial J}{\partial \tilde{o}_t}W_{xo}^T+\frac{\partial J}{\partial \tilde{f}_t}W_{xf}^T+ \frac{\partial J}{\partial \tilde{i}_t}W_{xi}^T+\frac{\partial J}{\partial \tilde{g}_t}W_{xg}^T\\ \end{array}\right.
对参数的梯度:
{∂J∂Who=htT∂J∂o~t+1∂J∂Whf=htT∂J∂f~t+1∂J∂Whi=htT∂J∂i~t+1∂J∂Whg=htT∂J∂g~t+1{∂J∂Wyh=htT∂J∂yt∂J∂Wcf=ctT∂J∂f~t+1∂J∂Wci=ctT∂J∂i~t+1∂J∂Wco=ctT∂J∂o~t{∂J∂Wxo=xtT∂J∂o~t∂J∂Wxf=xtT∂J∂f~t∂J∂Wxi=xtT∂J∂i~t∂J∂Wxg=xtT∂J∂g~t\left \{\begin{array}{l} \frac{\partial J}{\partial W_{ho}} = h_t^T\frac{\partial J}{\partial \tilde{o}_{t+1}} \\ \frac{\partial J}{\partial W_{hf}} = h_t^T\frac{\partial J}{\partial \tilde{f}_{t+1}} \\ \frac{\partial J}{\partial W_{hi}} = h_t^T\frac{\partial J}{\partial \tilde{i}_{t+1}} \\ \frac{\partial J}{\partial W_{hg}} = h_t^T\frac{\partial J}{\partial \tilde{g}_{t+1}} \end{array} \right. \left \{\begin{array}{l} \frac{\partial J}{\partial W_{yh}} = h_t^T\frac{\partial J}{\partial y_t} \\ \frac{\partial J}{\partial W_{cf}} = c_t^T\frac{\partial J}{\partial \tilde{f}_{t+1}} \\ \frac{\partial J}{\partial W_{ci}} = c_t^T\frac{\partial J}{\partial \tilde{i}_{t+1}} \\ \frac{\partial J}{\partial W_{co}} = c_t^T\frac{\partial J}{\partial \tilde{o}_{t}} \end{array} \right. \left \{\begin{array}{l} \frac{\partial J}{\partial W_{xo}} = x_t^T\frac{\partial J}{\partial \tilde{o}_{t}} \\ \frac{\partial J}{\partial W_{xf}} = x_t^T\frac{\partial J}{\partial \tilde{f}_{t}} \\ \frac{\partial J}{\partial W_{xi}} = x_t^T\frac{\partial J}{\partial \tilde{i}_{t}} \\ \frac{\partial J}{\partial W_{xg}} = x_t^T\frac{\partial J}{\partial \tilde{g}_{t}} \\ \end{array} \right.
2.2 GRU
一个更有意思的 LSTM 变种称为 Gated Recurrent Unit(GRU),由 Cho 等人提出。LSTM通过三个门函数输入门、遗忘门和输出门分别控制输入值、记忆值和输出值。而GRU中只有两个门:更新门ztz_t 和重置门 rtr_t ,如下图所示。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多;重置门控制前一时刻状态有多少信息被写入到当前的候选集 h~t\tilde{h}_t 上,重置门越小,前一状态的信息被写入的越少。这样做使得 GRU 比标准的 LSTM 模型更简单,因此正在变得流行起来。
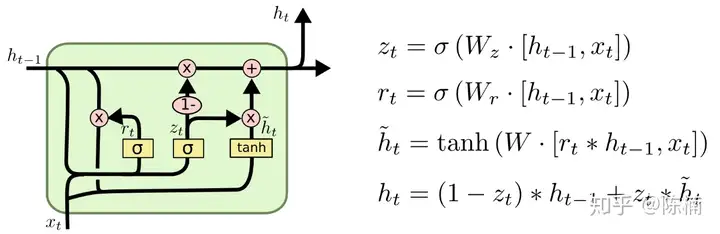
为了更加直观的推导反向传播公式,将上图转化为如下形式:

GRU的前向传播:在t时刻的前向传播公式为:
{rt=σ(r~t)=σ(Wxrxt+Whrht−1+br)zt=σ(z~t)=σ(Wxzxt+Whzht−1+bz)st=tanh(s~t)=tanh[Wxsxt+(ht−1⊙rt)Whs+bs]ht=zt⊙st+ht−1⊙(1−zt)yt=Wyhht+by\left\{ \begin{array}{l} {r_t=\sigma(\tilde{r}_t)=\sigma(W_{xr}x_t+W_{hr}h_{t-1}+b_r)} \\ {z_t=\sigma(\tilde{z}_t)=\sigma(W_{xz}x_t+W_{hz}h_{t-1}+b_z) }\\ {s_t=\tanh(\tilde{s}_t)}=\tanh[W_{xs}x_t+(h_{t-1}\odot r_t)W_{hs}+b_s] \\ {h_t=z_t\odot s_t + h_{t-1}\odot (1-z_t)}\\ {y_t=W_{yh}h_t+b_y} \end{array}\right.
GRU的反向传播:t时刻其它节点的梯度:
{∂J∂ht=∂J∂ytWhyT+∂J∂r~t+1WhrT+∂J∂z~t+1WhzT+∂J∂s~t+1WhsT⊙rt+∂J∂h~t+1⊙(1−zt)∂J∂st=∂J∂ht⊙zt∂J∂zt=∂J∂ht⊙st+∂J∂ht⊙(−ht−1)∂J∂rt=∂J∂s~tWhsT⊙ht−1}⇒{∂J∂s~t=∂J∂st(1−st2)∂J∂z~t=∂J∂ztzt(1−zt)∂J∂r~t=∂J∂rtrt(1−rt)∂J∂xt=∂J∂r~tWxrT+∂J∂z~tWxzT+∂J∂s~tWxsT\left\{ \begin{array}{l} \frac{\partial J}{\partial h_t}=\frac{\partial J}{\partial y_t}W_{hy}^T+\frac{\partial J}{\partial \tilde{r}_{t+1}}W_{hr}^T+ \frac{\partial J}{\partial \tilde{z}_{t+1}}W_{hz}^T+ \frac{\partial J}{\partial \tilde{s}_{t+1}}W_{hs}^T \odot r_t + \frac{\partial J}{\partial \tilde{h}_{t+1}}\odot(1-z_t)\\ \left.\begin{array}{l} \frac{\partial J}{\partial s_t}=\frac{\partial J}{\partial h_t}\odot z_t\\ \frac{\partial J}{\partial z_t}=\frac{\partial J}{\partial h_t}\odot s_t + \frac{\partial J}{\partial h_t}\odot (-h_{t-1}) \\ \frac{\partial J}{\partial r_t}=\frac{\partial J}{\partial \tilde{s}_t}W_{hs}^T\odot h_{t-1} \\ \end{array}\right\} \Rightarrow \left\{ \begin{array}{l} \frac{\partial J}{\partial \tilde{s}_t}=\frac{\partial J}{\partial s_t}(1-s_t^2)\\ \frac{\partial J}{\partial \tilde{z}_t}=\frac{\partial J}{\partial z_t}z_t(1-z_t) \\ \frac{\partial J}{\partial \tilde{r}_t}=\frac{\partial J}{\partial r_t}r_t(1-r_t) \\ \end{array}\right. \\ \frac{\partial J}{\partial x_t} = \frac{\partial J}{\partial \tilde{r}_t}W_{xr}^T+\frac{\partial J}{\partial \tilde{z}_t}W_{xz}^T+ \frac{\partial J}{\partial \tilde{s}_t}W_{xs}^T\\ \end{array}\right.
对参数的梯度:
{∂J∂Why=htT∂J∂yt∂J∂Whs=(ht−1⊙rt)T∂J∂s~t∂J∂Whz=ht−1T∂J∂z~t∂J∂Whr=ht−1T∂J∂r~t{∂J∂Wxs=xtT∂J∂s~t∂J∂Wxz=xtT∂J∂f~z∂J∂Wxr=xtT∂J∂r~t\left \{\begin{array}{l} \frac{\partial J}{\partial W_{hy}} = h_t^T\frac{\partial J}{\partial y_t} \\ \frac{\partial J}{\partial W_{hs}} = (h_{t-1}\odot r_t)^T\frac{\partial J}{\partial \tilde{s}_{t}} \\ \frac{\partial J}{\partial W_{hz}} = h_{t-1}^T\frac{\partial J}{\partial \tilde{z}_{t}} \\ \frac{\partial J}{\partial W_{hr}} = h_{t-1}^T\frac{\partial J}{\partial \tilde{r}_{t}} \end{array} \right. \left \{\begin{array}{l} \frac{\partial J}{\partial W_{xs}} = x_t^T\frac{\partial J}{\partial \tilde{s}_{t}} \\ \frac{\partial J}{\partial W_{xz}} = x_t^T\frac{\partial J}{\partial \tilde{f}_{z}} \\ \frac{\partial J}{\partial W_{xr}} = x_t^T\frac{\partial J}{\partial \tilde{r}_{t}} \end{array} \right.
2.3 遗忘门与输入门相结合的LSTM
另一个变种把遗忘和输入门结合起来。同时确定要遗忘的信息和要添加的新信息,而不再是分开确定。当输入的时候才会遗忘,当遗忘旧信息的时候才会输入新数据。
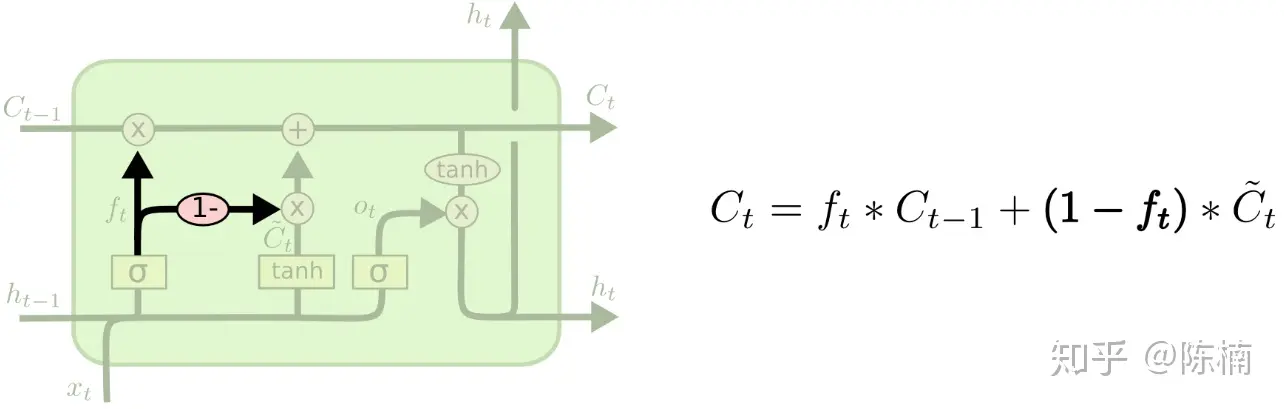
前向与反向算法与上述变种相同,这里不再做过多推导。
参考资料:【翻译】理解 LSTM 网络 - xuruilong100 - 博客园以上就是关于《人人都能看懂的LSTM介绍及反向传播算法推导(非常详细)-反向传播算法(过程及公式推导)》的全部内容,本文网址:https://www.7ca.cn/baike/60141.shtml,如对您有帮助可以分享给好友,谢谢。