LBS数据库的架构是怎样的?(lbs数据是什么)
架构的话有很多尝试,传统的Oracle和 Postgre用的比较广泛, 很多架构在此基础上同时应用 NoSQL因为大多数LBS并不涉及更复杂的空间数据存储,例如多边形或者三维数据,因此,大多数generic的数据库架构都可以应用。
但是,从产品核心的设计以及发展来看,如果像FourSquare(4SQ)进行数据挖掘并提供收费的数据分析服务,那么基于空间的利用文件数据结构,以空间POI为基础的NoSQL,是比较好的选择除了其他人介绍的很多LBS,比如街旁和4SQ,应用的Mongo DB, 还有Couch DB, 根据之前来讲课的澳洲政府的一个大型。
空间数据库项目(集成了多种现有的空间数据库)的构架师介绍,这个项目应用了Couch DB虽然理论上Graphic的NoSQL对于存储空间数据也有很大优势,但是毕竟相对不成熟,所以实际应用中的NoSQL还是以doc结构的Mongo和Couch为主。
如何提高命中率关键是对存储的空间数据认识程度和对用户query的类型的统计分析,并在此基础上开发出适合的算法,建立缓存或者对传统的空间索引进行组合,例如应用一些refine-filter策略空间数据的索引与传统的索引不同,但是又部分基于传统索引的基础之上的。
这里只介绍一些简单的空间索引入门算法,最后简单谈一下缓存建立的策略-----------------------------------索引------------------------------------------------------------------------
----简略介绍一下作为空间索引基础的一般索引,并由此为基础应用部分B tree思想并组合其他一些方法进行空间索引B-Tree/B+Tree 定义的话学过数据库应该都了解这是常用的一般性索引从0-100 这一百个数找到40这个,可以用过100 -> (0-50), (51-100) 在(1-50)里面查询,然后再从(1-25)(26-50)里面的(26-50)里面查询。
通过它的平衡性,每次减少一半的数据,所以查询时间是O(log n)1->100是一个一维的线性关系
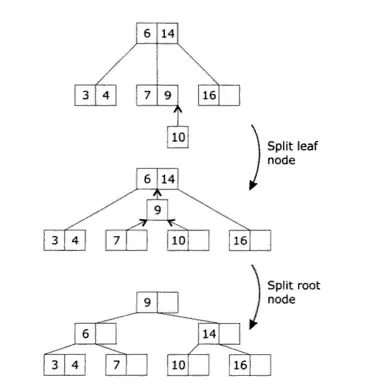
B-Tree 存储的插入方式(Worboys and Duckham, GIS: A Computing Perspective , p229)----从一维到二维(当然也有三维但是那个更复杂,不在这里讨论之列)
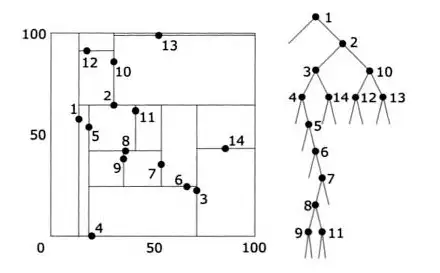
因为空间的每个object的首先是表现在二维空间的点,线或者多边形这个帖子因为问的是LBS,因此主要的目的是存储points的POI(Points of interesting)以及它附属的属性二维空间的索引为什么传统的B tree 不可以呢?看下图:。
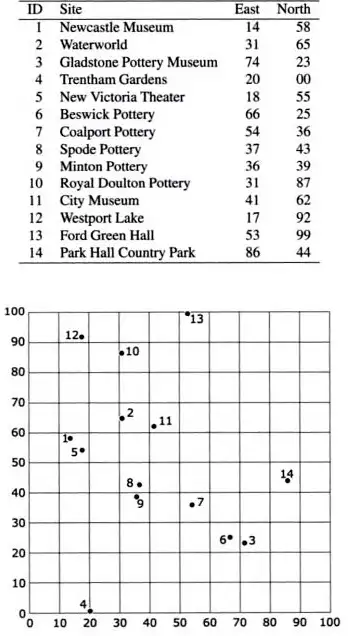
(Worboys and Duckham, GIS: A Computing Perspective , p230)这14个POI的信息在上表,在空间中他们如下面的图请注意点1和点2在一维空间上是相邻的,而在二维空间,1和5却是距离最近的。
因此线性的索引1-2-3-4-5无法满足空间里1-5的关系举个例子,你要查询哪个POI与点1在同一个10*10的区域,在这个query中,你通过1-2-3-4-5...在用B tree分割的方式无法快速返回结果。
那么我们是不是应该根据空间的远近或者相似性来排序呢?如何做呢?见下面------二维的顺序好的二维排序方法应该兼顾顺序和空间远近的相对关系,就是上个例子中点1和5的顺序应该是点1和2,这样就保存了空间相似行
和顺序的正相关。可以应用的空间order 总结下来有如下:
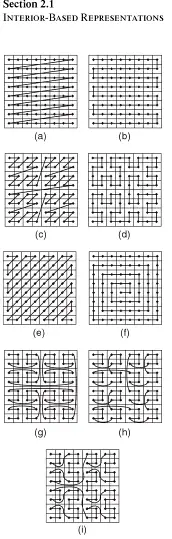
(Hanan Samet, Foundations of Multidimensional and Metric Data Structures,p199)这些方式有利有弊,例如图a,第一行最右边的点8和第二行最右边的点16空间关系很近,但是,序号却相差8。
但是,在同一行空间关系保持的与序号相关性保持的很好----栅格结构从以上的order中发现,这都是基于栅格结构把空间分割成栅格,从而编号成为index的栅格的存储点的空间object的index,常用的方式是Region Quadtrees。
什么是Quadtrees的存储方式呢?
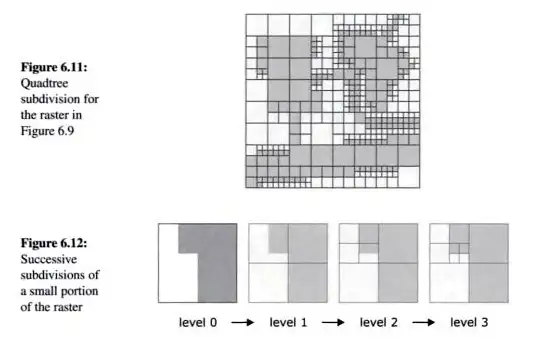
(Worboys and Duckham, GIS: A Computing Perspective , p236)简单来说,在level 1 把空间分成leve1(0,1,2,3)其中只有0,1,3有数据,其中level 1的1和3都被占满了,就不在继续分割了。
然后在level2再把level1的0分成(0,1,2,3),其中只有1,3有数据,其中1已经被占满了,就不用再分割如此类推,所有的数据都存储到 (01,030,031,1,3)----结合以上介绍的方法组合起来来拿作为。
空间index的算法1. Point Quadtree见图:
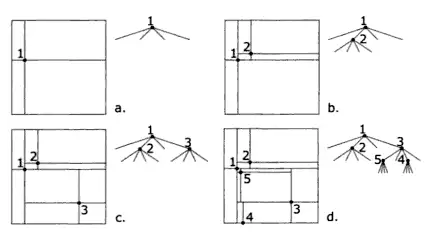
(Worboys and Duckham, GIS: A Computing Perspective , p243)其中点1(x坐标,y坐标,西北,东北,西南,东南,数据),然后在点1的东北下(就是上图中b的第二个分支),存储点2(x坐标,y坐标,西北,东北,西南,东南,数据),然后再在点1的东南(上图中c得第四个分支下)存储点3(x坐标,y坐标,西北,东北,西南,东南,数据)。
以此类推2.2D-Tree与Point Quadtree类似。但是它不把空间分隔成4个部分而是两个。如图:
(Worboys and Duckham, GIS: A Computing Perspective , p245)其中点1(x坐标,y坐标,左,右,数据),点2(x坐标,y坐标,左,右,数据)在1的右边,因此2存储在1的第二个分支下。
以此类推当然,更复杂的地理信息数据库中,线,多边形和三维objects都会有存储,因此他们的index方法也不同于点一般来说,越复杂的object index的方法也越复杂,-----------------------------------缓存------------------------------------------------------------------------。
下面简单说明一下缓存的建立思路这个无法进行详细说明,因为往往都是要根据业务需求进行设计的简单流程是分析业务主流的query类型-》根据query类型设计缓存只有理解query类型,才能理解查询过程中应用的算法。
这么做目的有2个:1是尽量避免用计算量大耗时长的算法来取得query结果,2是如果避免不了就进行预计算所以首先是要理解空间query的类型,按照计算量从小到大顺序排列的query类型是1.空间选择查询.。
例如,找到距离火车站200米以内的5星评价的饭店2.最近邻居查询. 例如,距离火车站最近的2个饭店/火车站到北京饭店的驾车距离是多少3.拓扑关系查询例如,王府井是否在北京市这里如果都是LBS的话, 其实简单很多,因为点与线或者多边形的距离和。
拓扑结构的算法是很简单的,而多边形和多边形就复杂得多假设,LBS的query,是大众点评式的用户最多的query应该是类似:距离我现在的位置最近的的港式餐厅按评价排序结果这个是一个典型的空间选择查询那么,缓存的策略可以按照用户集中地地区,预先查询出一些常用的餐厅类型的文件,做成缓存。
相对于其他的地理信息查询,LBS的缓存还是好做的大家可以感受一下这个query:找到所有国内的城市,它最近的河流全部是在这个城市所在的省之外这个query涉及了线和多边形的拓扑结构查询(省之外)和最近邻居查询(最近的河流)的组合查询,。
如果用户都是这种query,那么做缓存的策略人就要蛋疼了!!!!具体操作就要考虑预先计算省的多边形的最小bounding box了之后这里涉及比较复杂的缓存策略就省略..写起来就不是几句话能讲清楚得了----------------------------------------------------------------------------------------------------------------
最后感谢我的数据库老师Matt Duckham,也就是多次截取图片的原书作者。
以上就是关于《LBS数据库的架构是怎样的?(lbs数据是什么)》的全部内容,本文网址:https://www.7ca.cn/baike/6543.shtml,如对您有帮助可以分享给好友,谢谢。