Attention is All You Need?LSTM提出者:我看未必(我未必看的起前一句)
机器之心报道机器之心编辑部Transformer 中的注意力机制等价于一种 Hopfield 网络中的更新规则?LSTM 提出者 Sepp Hochreiter 等人在最近的一篇论文中表达了这种观点,并将这篇论文命名为《Hopfield Networks is All You Need》。
深度学习先驱、图灵奖获得者 Yann LeCun 一直认为无监督学习才是通向真正人工智能的方向为了实现无监督学习,我们需要探索基于能量的学习(energy-based learning)这个方向在 AI 领域里已经存在几十年了,生物学家约翰 · 霍普菲尔德(John Hopfield)于 1982 年将之以 Hopfield Network 的形式进行了推广。
这在当时机器学习领域中是一个突破,它推动了其他学习算法的发展,如 Hinton 的「玻尔兹曼机」「基于能量的学习已经存在了一段时间,最近一段时间里,因为寻求更少监督的方法,它重新回到了我的视野中」Yann LeCun 在 2019 年 10 月于普林斯顿大学的演讲中说道。
深度学习领军人物给未来 AI 方向的预测让我们对 Hopfield 网络这一「古老」事物燃起了兴趣,无独有偶,最近一群研究者又告诉我们:NLP 领域里大热的 Transformer,其网络更新规则其实是和 Hopfield 网络在连续状态下是相同的。
于是,一篇标题也要对标 Transformer 论文的《Hopfield Networks is All You Need》诞生了。

2018 年,谷歌的一篇论文引爆了 NLP 学界在这篇论文中,研究者提出了一种名为 BERT 的模型,刷新了 11 项 NLP 任务的 SOTA 记录众所周知,BERT 之所以能取得如此成功,很大程度上要归功于其背后的 Transformer 架构。
2017 年,谷歌在《Attention is All You Need》一文中提出了 Transformer自提出以来,它在众多自然语言处理问题中取得了非常好的效果:不但训练速度更快,而且更适合建模长距离依赖关系。
目前,主流的预训练模型都是以 Transformer 模型作为基础进行修改,作为自己的特征抽取器可以说,Transformer 的出现改变了深度学习领域,特别是 NLP 领域为什么 Transformer 如此强大?这还要归功于其中的注意力机制。
注意力机制在 NLP 领域的应用最早可以追朔到 2014 年,Bengio 团队将其引入神经机器翻译任务但那时,模型的核心构架还是 RNN相比之下,Transformer 完全抛弃了传统的 CNN 和 RNN,整个网络结构完全由注意力机制组成,这种改变所带来的效果提升也是颠覆性的。
但最近的一项研究表明,Transformer 中的这种注意力机制其实等价于扩展到连续状态的 modern Hopfield 网络中的更新规则论文作者来自奥地利林茨大学、挪威奥斯陆大学等机构,与 Jürgen Schmidhuber 合著 LSTM 的 Sepp Hochreiter 也是作者之一。

Hopfield 网络是一种 RNN 模型,由 John Hopfield 于 1982 年提出它结合了存储系统和二元系统,保证了向局部极小值的收敛,但收敛到错误的局部极小值而非全局极小值的情况也可能发生。
Hopfield 神经网络对上世纪 80 年代初神经网络研究的复兴起到了重大作用1987 年,贝尔实验室在 Hopfield 神经网络的基础上研制出了神经网络芯片2016 年和 2017 年,Hopfield 等人又改进了这一网络(即下文中的 modern Hopfield 网络 )。
在林茨大学和挪威奥斯陆大学的这篇论文中,研究者提出了一种新的 Hopfield 网络,将 modern Hopfield 网络从二元模式扩展到了连续模式,并表明这些新 Hopfield 网络的更新规则(update rule)等价于 Transformer 中的注意力机制。
这种带有连续状态的新 Hopfield 网络保留了离散网络的特点:指数级的存储容量和极快的收敛速度在发现新 Hopfield 网络更新规则与 Transformer 注意力机制的等价性之后,研究者利用这一发现分析了 BERT 等基于 Transformer 的模型。
他们发现,这些模型有不同的运行模式,而且更加倾向于在较高的能量最小值下运行,而后者是一种亚稳态(metastable state)这篇论文在 Twitter、Reddit 等平台上引发了广泛的讨论。
知名 Youtube 博主、苏黎世联邦理工学院博士生 Yannic Kilcher 还针对该论文进行了解读,相关视频播放量两天内就超过了一万次00:00/00:00倍速原视频地址:https://www.youtube.com/watch?v=nv6oFDp6rNQ&feature=youtu.be。
以下是论文的详细内容Hopfield Networks is All You Need深度学习社区一直在寻找 RNN 的替代方案,以解决信息存储问题,但大多数方法都是基于注意力的Transformer 和 BERT 模型更是通过注意力机制将模型在 NLP 任务中的性能推到了新的水平。
这项研究表明,Transformer 中的注意力机制其实等价于扩展到连续状态的一种 modern Hopfield 神经网络的更新规则这个新的 Hopfield 网络能够实现模式存储的指数级提升,一次更新即可收敛,并且检索误差也呈现指数级下降。
存储模式的数量与收敛速度和检索误差之间存在必然的权衡研究者提出的新 Hopfield 网络有三种类型的能量最小值(更新的固定点):1)所有模式上的全局固定点平均值;2)模式子集上的亚稳态平均值;3)存储单个模式的固定点。
Transformer 通过构建一个模式嵌入和关联空间的查询来学习注意力机制在最初几层,Transformer 和 BERT 模型倾向于在全局平均机制下运行,但在更高层则倾向于在亚稳态下运行Transformer 中的梯度在亚稳态机制中最大,在全局平均时均匀分布,在固定点临近存储模式时消失。
基于 Hopfield 网络的解释,研究者分析了 Transformer 和 BERT 架构的学习学习开始于注意力头(attention head),它们最初平均分布,然后其中的大部分转换为亚稳态但是,前几层中的注意力头大多依然平均分布,并且可以被研究者提出的高斯权重等平均运算取代。
相比之下,最后几层中的注意力头稳定地学习,而且似乎利用亚稳态来收集较低的层创建的信息这些注意力头似乎就是改进 Transformer 的潜在目标集成 Hopfield 网络的神经网络(等同于注意力头)在免疫组库分类任务中的性能优于其他方法,其中的 Hopfield 网络可以存储数十万个模式。
研究者提出了一种名为「Hopfield」的 PyTorch 层,借助 modern Hopfield 网络来改进深度学习这是一种包含池化、记忆和注意力的强大新概念

论文地址:https://arxiv.org/pdf/2008.02217.pdf项目地址:https://github.com/ml-jku/hopfield-layers连续状态 Modern Hopfield 网络的新能量函数和更新规则
在论文中,研究者提出了一个新的能量函数,它是在 modern Hopfield 网络能量函数的基础上做出的改进,以使其扩展到连续状态改进之后,新的 modern Hopfield 网络可以存储连续模式,还能保持二元 Hopfield 网络的收敛和存储能力。
经典 Hopfield 网络不需要约束自身状态向量的范数,因为这类网络是二元的,且具有固定长度此外,研究者还提出了一个新的更新规则,它被证明可以收敛至能量函数的稳定点(局部最小值或鞍点)他们还证明,一个与其他模式实现良好分离的模式可以通过一步更新被检索到,同时还能实现指数级的误差下降。
下图 1 展示了二元 modern Hopfield 网络、研究者提出的连续状态 Hopfield 网络、新更新规则和 Transformer 之间的关系。
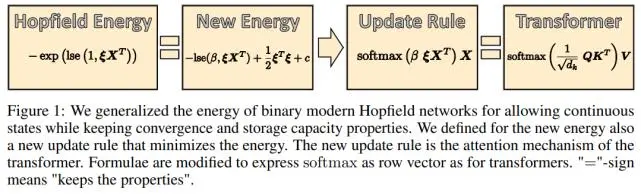
通过使用 negative 能量的对数并添加一个确保状态向量ξ的范数受限的二次项,研究者将这个能量函数泛化至连续值模式他们证明,这些改动保持了 modern Hopfield 网络的指数级存储能力优势以及单次更新即可收敛的属性,具体可见上图 1。
研究者将这个新颖的能量函数 E 定义如下:
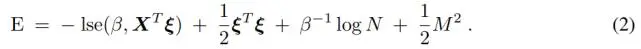
其中,
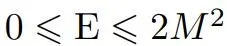
。研究者用 p = softmax(βX^T ξ)定义了一个新的更新规则,公式如下:

接下来,他们又证明了更新规则公式 (3) 具有全局收敛性连续状态 Hopfield 网络的更新规则就是 Transformer 中的注意力机制研究者认为,连续状态 Hopfield 网络中的更新规则就是 Transformer 和 BERT 中使用的注意力机制。
为此,他们假设模式 y_i 映射到维度 d_k 的 Hopfield 空间研究者令
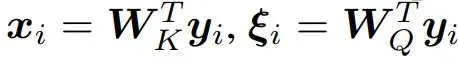
并将更新规则结果与 W_V 相乘。矩阵

结合 y_i,作为行向量。研究者分别将矩阵 X^T 和 V 定义为
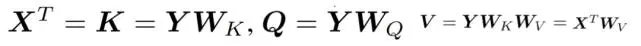
其中

对于结合矩阵 Q、
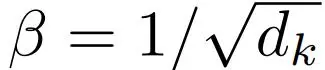
和 softmax ∈ R^N 中变成行向量的所有查询,研究者将更新规则公式 (3) 乘以 W_V,得到的结果如下:
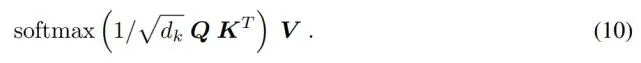
这个公式就是 Transformer 的注意力机制Transformer 和 BERT 模型分析Transformer 和 BERT 模型的运算类别通过对注意力机制的理论分析,研究者提出了以下三种固定点:a)如果模式 x_i 没有实现良好的分离,那么迭代转向靠近向量算数平均值的固定点,即全局固定点;b)如果模式彼此之间实现良好的分离,则迭代靠近模式。
如果初始ξ类似于模式 x_i,则它将收敛至接近 x_i 的向量,p 也将收敛至靠近 e_i 的向量,研究者称之为靠近单个模式的固定点;c)如果一些向量彼此之间类似并与其他所有向量实现良好的分离,则类似向量之间存在着所谓的亚稳态。
开始时靠近亚稳态的迭代收敛至这个亚稳态研究者观察到,Transformer 和 BERT 模型都拥有包含以上三种固定点的注意力头,具体如下图 2 所示:
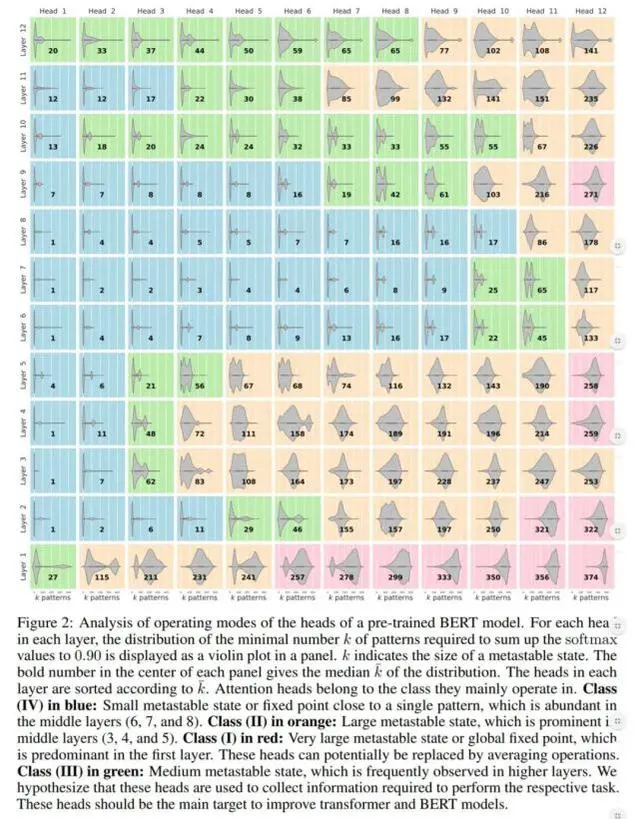
从上图 2 可以看到,较低层中的很多注意力头在 class (I)中运行较低层中的注意力头执行平均运算如下图 3d 所示,困惑度是根据改动层的数量绘制的(第一层的困惑度最低)红线表示初始模型的困惑度研究者发现,较低层中性能受影响的程度低于较高层,并且在第一层几乎不受影响。
这表明,第一层的注意力头可以被基于平均运算的非注意力头所取代

基于这些分析,研究者用高斯权重替换了第一层的注意力头,其中高斯函数的均值和方差可以学得所以,他们得到了一个位置高斯权重平均方案,其中每个 token 仅有两个参数,而没有注意力头此外,注意力头总是执行相同的平均运算,而与输入无关。
研究者采用的高斯权重类似于随机合成器头(random synthesizer head),其中注意力权重可以直接学得后几层的注意力头在中等亚稳态下运行,而且看起来对于 BERT 非常重要如上图 2 所示,研究者发现后几层(第 10、11 和 12 层)中的注意力头主要在 class III 状态下运行。
为了研究这些层,研究者像以往一样以平均值运算替换注意力头与前几层和中间层执行相同的操作相比,模型的性能下降要明显得多,具体如上图 3d 所示在更新到大约 9000 次时,损失函数曲线出现剧烈下滑(如上图 3a 蓝线所示),这与注意力头转向其他类是一致的。
相比之下,后几层的注意力头在下降之后依在学习(如上图 3c 所示),并且更靠近 class (III)最后,层归一化与 modern Hopfield 网络中最重要参数的调整高度相关研究者将β认定为固定点以及注意力头运算模式的一个关键参数。
Hopfield 网络由β、M(最大模式范数)、m_max(类似模式的传播)和 ‖m_x‖(类似模式的中心)共同决定β的较低值诱导全局平均值和更高的β亚稳态值调整β或 M 等同于调整层归一化的(逆)增益参数。
所以,层归一化控制了 Hopfield 网络最重要的几个参数:β、M、m_max 和 ‖m_x‖实验在实验部分,研究者证实在免疫组库分类和大规模多实例学习中,modern Hopfield 网络可以被视为类似于 Transformer 的注意力机制。
原文中定理 3 表明,modern Hopfield 网络具有指数级存储能力,从而可以解决免疫库分类等大规模多实例学习问题研究者通过大规模对比研究证实了 modern Hopfield 网络的有效性此外,研究者还提供了一个新 Hopfield 层的 PyTorch 实现,从而可以将 Hopfield 网络作为一种新颖的记忆概念加入到深度学习架构中。
新的 Hopfield 层能够关联两个向量集合这种通用的功能性可以实现类似于 Transformer 的自注意力、编码器 - 解码器注意力、时序预测(可能使用位置编码)、序列分析、多实例学习、点集学习、基于关联的数据源组合、记忆构建以及运算求平均值和池化等等。
具体来说,新 Hopfield 层能够轻易地作为池化层(最大池化或平均池化)、排列等变层、GRU&LSTM 层以及注意力层等现有层的 plug-in 替代新 Hopfield 层基于连续状态的 modern Hopfield 网络,这些网络具有极强的存储能力以及一次更新即可收敛的能力。
参考内容:https://www.zdnet.com/article/high-energy-facebooks-ai-guru-lecun-imagines-ais-next-frontier/
以上就是关于《Attention is All You Need?LSTM提出者:我看未必(我未必看的起前一句)》的全部内容,本文网址:https://www.7ca.cn/news/dianzizhizao/676.shtml,如对您有帮助可以分享给好友,谢谢。