想要优雅的Excel数据去重,还得是unique函数(excel表数据去重)

「如何将数据中的重复数据去除,只保留或提取不重复的数据,该怎么操作呢?」
本期用3种方法来解决上面的问题。
手动操作去重提取
unique高级数组函数一步提取
普通数组函数提取(可直接套用公式)
点赞收藏,根据你的需要选择合适的方法。
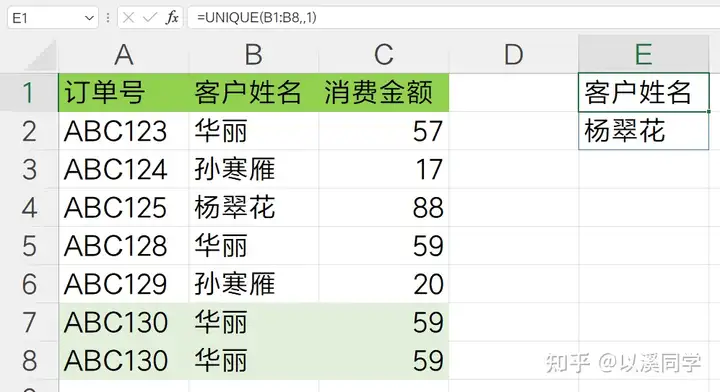
问题:需求例如下图的数据表,最下方存在两条重复数据,同时也存在一个客户有多笔订单的情况。
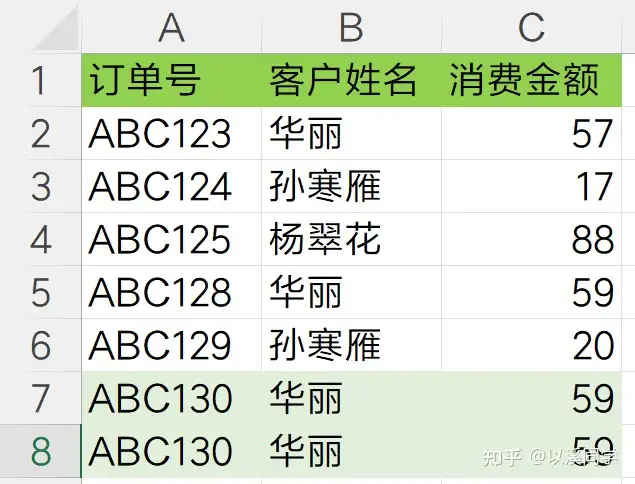
需求有三个:
将数据去重,只保留不重复的数据;
提取出去重后的客户姓名;
提取只出现过一次的客户姓名;
1.软件内置删除重复值操作复制原数据到新的一张表中,选中所有数据。
在数据选项卡找到删除重复值按钮。
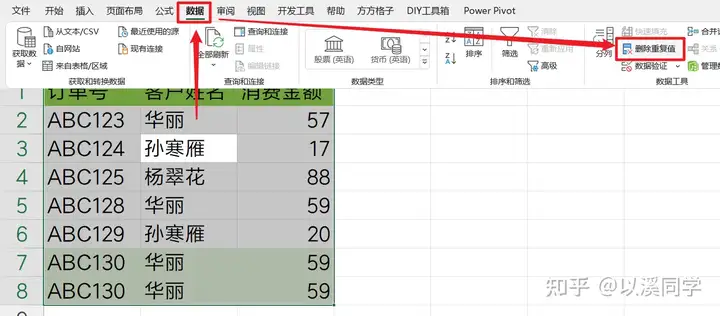
在弹出的窗口中,数据有标题记得勾选标题,下方的三列选项,全部勾上,代表只有当三列数据都完全一致,才算重复项。
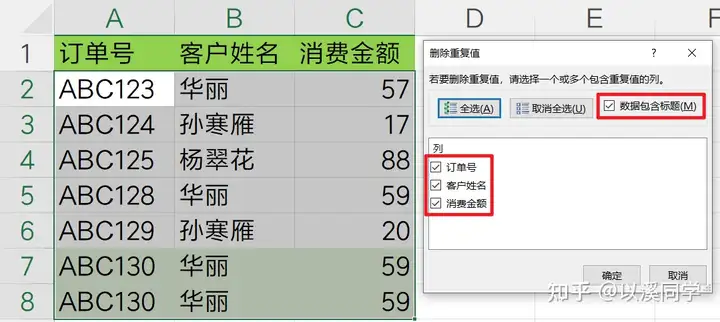
点击确认删除后,会发现虽然存在多个重复姓名,但是只有一个三列全部重复的数据被删除了。
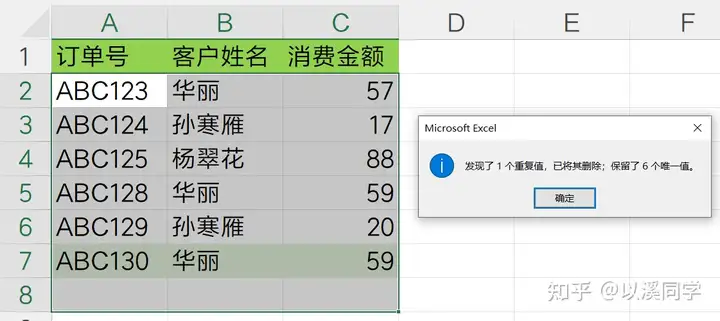
如果想要去重客户姓名,则可以「只勾选客户姓名」,最终结果如下图所示。
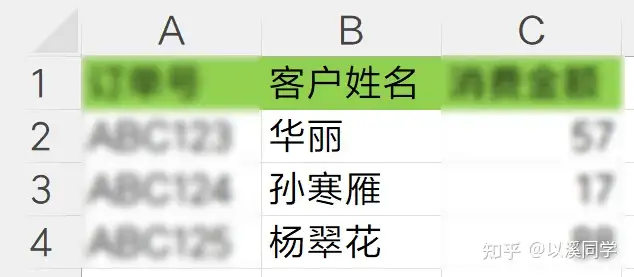
此时的订单号和消费金额已经没有意义了,可以删除。
如果想要提取只出现过一次的客户姓名,则可以使用辅助列方法。
在原数据右侧添加辅助公式列,公式向下填充,统计姓名出现次数
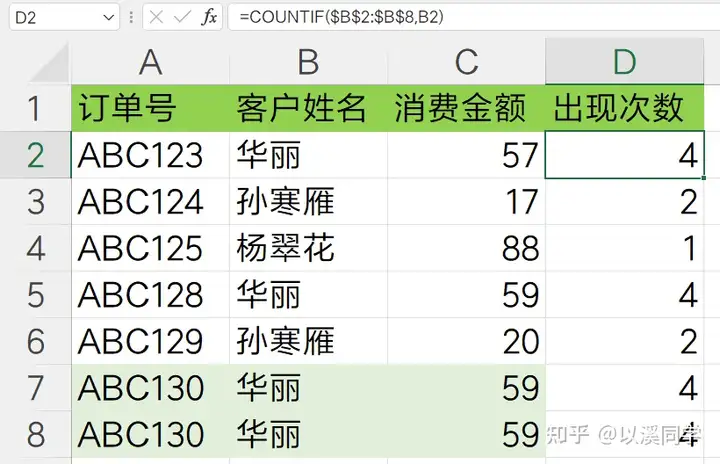
统计客户姓名出现次数后筛选提取次数为1的数据。
提示:CTRL+SHIFT+L可以快速开关筛选

通过辅助列,你可实现各种乱七八糟的去重操作,比如将所有列数据用&链接成一个字符串,然后统计筛选去重。
不过,上面的方法,怎么看都感觉不够优雅!

如果你的软件版本带有unique函数,那上面的操作,只需几行函数公式就搞定了。
2.unique去重函数Microsoft 365,Excel 2021以及WPS最新版支持该函数
UNIQUE函数作用,就是返回列表或范围中的一系列唯一值。
参数如下:
=UNIQUE (array,[by_col],[exactly_once])

一共三个参数,通常情况下,你不需要做特别设置。
比如需求1中,将所有数据按行去重。
如果你是Microsoft 365用户,直接输入公式:
回车就可以得到去重后的结果。
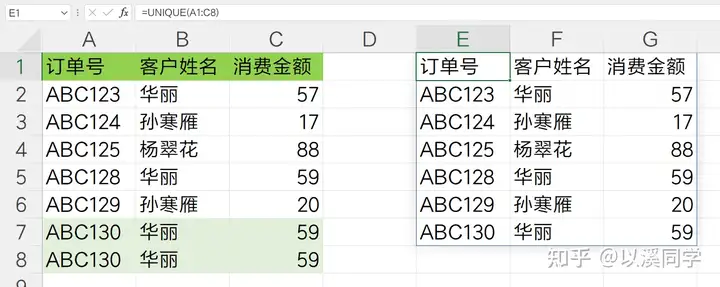
如果是WPS,需要按照普通数组公式使用方法。
先选择承载去重后数据的空单元格区域。
也就是E1:G7单元格,这个选择范围,是根据去重后的数据大小确认,可以比最终的数据范围大,但不能小,否则会显示不全数据。
再输入上面的公式。
最后按数组确认键CTRL+SHIFT+回车确认数组公式。
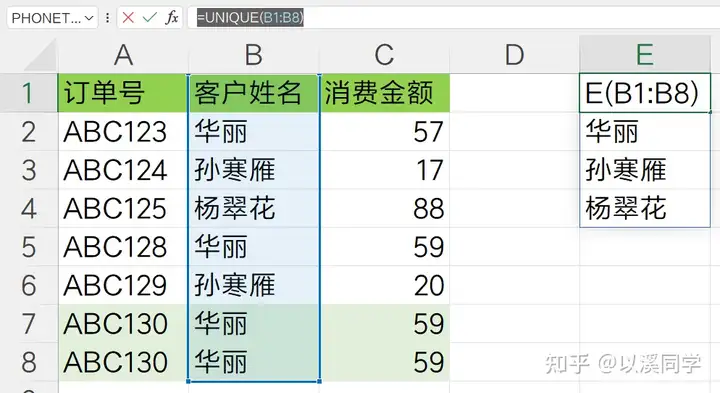
需求2要求提取去重姓名,只需要将函数的第一个参数array,也就是待去重的数据区域,缩小到姓名区域即可,公式如下:
需求3要求提取只出现过一次的客户姓名,将unique函数的第三个参数改成1,即可提取恰好出现过一次的数据,公式如下:
如果你的软件里没有unique函数,也由于某些原因,无法更新软件,可以试试下面的普通数组公式法来代替unique,实现部分相同的功能。
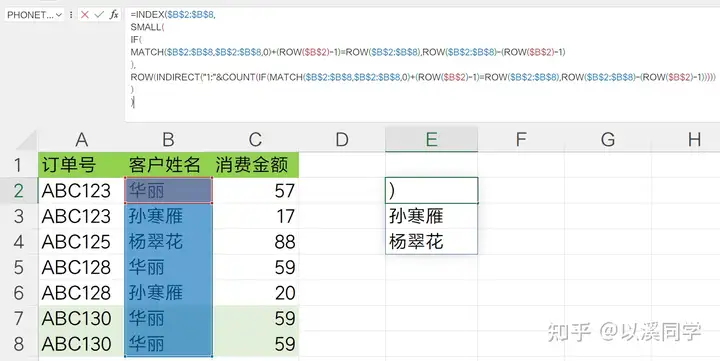
3.普通数组公式代替unique去重单列数据例如将客户姓名列数据进行去重,完整的公式如下:
将公式中的下方数据,替换为自己表格中的实际待去重区域地址即可
$B$2:$B$8为待去重区域单元格引用地址;
$B$2为待去重区域「第一个单元格」的引用地址;
WPS请按照CSE数组公式输入三步骤(上文写过),来录入公式。
完成结果如图:
看到这么长的数组公式,不用慌,分析清楚结构后,你就能直接替换其中的数据范围,自己编写出适合自己数据的公式。
3.1 普通数组函数公式解析公式的核心就是通过index函数,从给定的数据范围里,按照给定的位置数组,输出对应数据范围的数据。
「基本公式index提取数据」
例如=index(B2:B8,{1;2;3})就会返回B2:B8区域的第1、2和3位的数据。
那现在最关键的就是如何计算得出{1;2;3}这个位置数组,来告诉index提取这三个位置的数据。
「match函数查找每个数据位置」
我们使用match函数,用来查找指定数据在数据范围中的位置数据。也就是MATCH($B$2:$B$8,$B$2:$B$8,0),得出结果为{1;2;3;1;2;1;1}。
通过选中整个查找区域到整个查找区域去匹配,我们就能得到,每一个客户姓名,首次出现在查找区域的位置。
从数字上,我们就能够看出,出现重复数字的就是存在重复情况。
「使用if函数判断是否首次出现」
使用ROW($B$2:$B$8),我们能够得到客户姓名数据的每一行位置数据,也就是{2;3;4;5;6;7;8}。
如果match函数查找到的数据位置与row函数本身的数据位置一致,则说明,该行数据是首次出现,否则说明前面已经出现过了。
需要注意的是,由于客户姓名所在区域是从B2开始的,这导致row(B2)返回的值也是从2开始。
而match函数返回的位置数据,是相对于查找数据范围从1开始计数,因此我们需要给match函数加上这个相对位置差。
这个相对位置差的计算方法由选择的客户姓名数据范围的第一个单元格位置$B$2减1得到,也就是ROW($B$2)-1,一定要添加$绝对引用。
最终if函数的条件式就写好了:MATCH($B$2:$B$8,$B$2:$B$8,0)+(ROW($B$2)-1)=ROW($B$2:$B$8)。
如果成立,我们就返回对应的位置数,你可以写成MATCH($B$2:$B$8,$B$2:$B$8,0),也可以写成ROW($B$2:$B$8)-(ROW($B$2)-1)。
如果不成立,则说明前面已经出现过这个姓名数据了,就默认返回False即可。
完整的if函数部分公式如下:IF(MATCH($B$2:$B$8,$B$2:$B$8,0)+(ROW($B$2)-1)=ROW($B$2:$B$8),ROW($B$2:$B$8)-(ROW($B$2)-1))
该部分公式计算结果为:{1;2;3;FALSE;FALSE;FALSE;FALSE}
「使用small函数,依次提取最小的数字」
我们通过if函数得到了去重后的位置数组{1;2;3;FALSE;FALSE;FALSE;FALSE},现在只要使用small函数去提取出其中的{1;2;3},就完成了整个公式。
small函数一共有2个参数,第一个是数组,第二个是要提取第几位最小值。
我们这里需要提取第1、2和3位最小值,其中false不参与比较,可以把第二个参数写成{1;2;3}数组带入,一次性返回small函数提取的值。
公式如下:small({1;2;3;FALSE;FALSE;FALSE;FALSE},{1;2;3})
那问题的关键就是如何生成{1;2;3}这种序列数组,而且刚好生成3个。
想要了解,序列函数技巧,可以参考Sequence等差序列函数这篇文章。

使用row(1:3),就可以直接生成{1;2;3},但是如果表格被删除了1到3行中的任意行,函数会报错。
所以我们可以使用indirect函数,把原本的1:3行地址引用改成文本的indirect("1:3"),这样外界的操作就不会影响函数公式,最终的公式为ROW(INDIRECT("1:3"))。
那么如何指定生成多少个呢?
我们可以使用count函数去统计前面if函数的结果中,数字的部分有多少个,就能直接获得需要的个数。
所以,别犹豫,直接复制前面的if函数公式部分,再用count函数嵌套后,替换掉ROW(INDIRECT("1:3"))这里的3,注意文本和公式拼接要使用&符号。
那最终small函数的第二个参数,需求生成{1;2;3}的函数公式就是ROW(INDIRECT("1:"&COUNT(IF(MATCH($B$2:$B$8,$B$2:$B$8,0)+(ROW($B$2)-1)=ROW($B$2:$B$8),ROW($B$2:$B$8)-(ROW($B$2)-1)))))
别看这部分这么长,其实count函数里的公式都是前面写过的。 最后完整的公式就成功出炉:=INDEX($B$2:$B$8, SMALL( IF( MATCH($B$2:$B$8,$B$2:$B$8,0)+(ROW($B$2)-1)=ROW($B$2:$B$8),ROW($B$2:$B$8)-(ROW($B$2)-1) ), ROW(INDIRECT("1:"&COUNT(IF(MATCH($B$2:$B$8,$B$2:$B$8,0)+(ROW($B$2)-1)=ROW($B$2:$B$8),ROW($B$2:$B$8)-(ROW($B$2)-1))))) ) )
3.2那么,如何实现需求3中的,只提取恰好出现1次的数据呢?函数公式如下:
关键的不同点,在于把match函数,改成了countif函数,由查找位置数,变成了统计出现次数,并判断是否次数等于1。
最后如果还有相关问题,欢迎在评论区留言讨论,或在以溪同学好众工回复「群」加入Excel讨论~
你学会了吗?
以上就是关于《想要优雅的Excel数据去重,还得是unique函数(excel表数据去重)》的全部内容,本文网址:https://www.7ca.cn/baike/60666.shtml,如对您有帮助可以分享给好友,谢谢。