Faster_RCNN理解_faster rcnn算法
目录:
1.faster rcnn算法流程
2.faster rcnn原理详解
3.faster rcnn介绍
4.一文读懂faster rcnn知乎
5.faster rcnn fast rcnn
6.faster-rcnn
7.faster rcnn roi
8.fasterrcnn详解
9.faster rcnn+fpn
10.fasterrcnn原理
1.faster rcnn算法流程
https://blog.csdn.net/heavenpeien/article/details/80534963blog.csdn.net/heavenpeien/article/details/80534963
2.faster rcnn原理详解
https://blog.csdn.net/qq_36259240/article/details/78246112blog.csdn.net/qq_36259240/article/details/78246112
3.faster rcnn介绍
https://blog.csdn.net/u014365862/article/details/77887230blog.csdn.net/u014365862/article/details/77887230
4.一文读懂faster rcnn知乎
blog.csdn.net/jmu201521121021/article/details/87877721blog.csdn.net/jmu201521121021/article/details/87877721
5.faster rcnn fast rcnn
https://blog.csdn.net/xys430381_1/article/details/82784645blog.csdn.net/xys430381_1/article/details/82784645
6.faster-rcnn
晓雷:Faster R-CNN375 赞同 · 58 评论文章
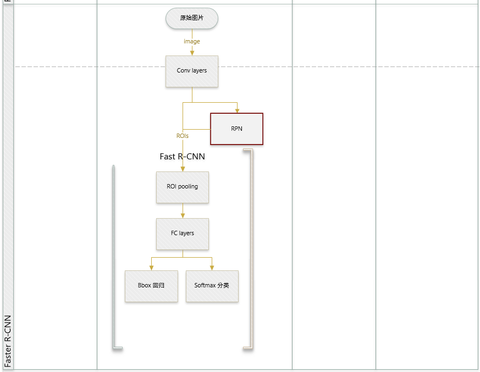
7.faster rcnn roi
Faster RCNN 支持输入任意大小的图片的,比如输入P*Q*3 ,进入网络之前对图片进行了规整化尺度的设定,如可设定图像短边不超过600,图像长边不超过1000,目的是避免图像分辨率过大所带来的计算负担。
8.fasterrcnn详解
我们可以假定M*N=1000*600(如果图片少于该尺寸,可以边缘补0,即图像会有黑色边缘)经过Conv layers,经过16倍下采样后,图片大小变成(M/16)*(N/16),即:60*40(1000/16≈60,600/16≈40);则,Feature Map就是60*40*512-d,表示特征图的大小为60*40,通道数为512。
9.faster rcnn+fpn
Anchor的本质是什么?本质是SPP(spatial pyramid pooling)思想的逆向SPP就是将不同尺寸的输入resize成为相同尺寸的输出所以SPP的逆向就是,将相同尺寸的输出,倒推得到不同尺寸的输入。
10.fasterrcnn原理
Faster RCNN主要贡献:1)RPN(Region Proposal Network)网络,RPN通过深度网络实现了 Proposal 功能,替代之前的 SS(Selective Search)方法,使得检测速度大幅提高。
2)端到端的检测Faster R-CNN 主要由三个部分组成:(1)基础特征提取网络 ----> VGG16/ResNet (2)RPN ,Anchor机制首次提出(anchor=53*49*9 一幅图大约产生 20k个rp) (3)Fast-RCNN 。
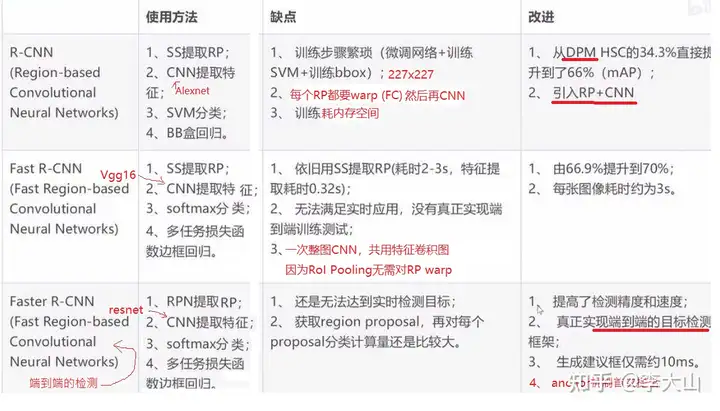
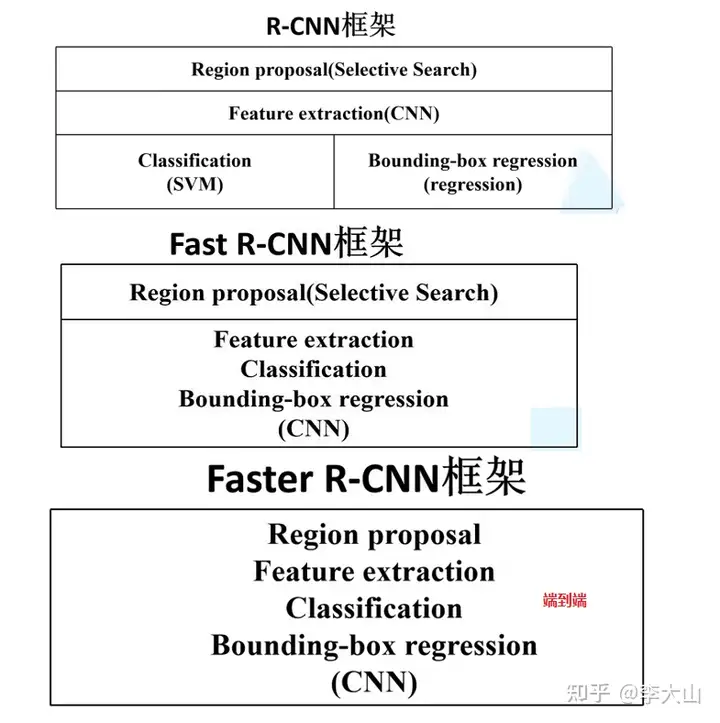
其中RPN和Fast-RCNN 共享特征提取卷积层,思路上依旧延续提取proposal + 分类的思想Ross 2014年R-CNN横空出世的时候,颠覆了以往的目标检测方案,精度大大提升对于R-CNN的贡献, 1) 使用了卷积神经网络(Alexnet)进行特征提取。
2) 监督预训练,分类大数据集先预训练,再迁移到目标检测数据集上Finetune 缺失不足: 1) 耗时的selective search,对一帧图像,需要花费2s 2) 耗时的串行式CNN前向传播,对于每一个RP,都需要经过一个AlexNet提特征,所有的RP提特征大约花费47s。
3) 三个模块(CNN,SVM,bbox回归)是分阶段训练的,并且在训练的时候,对于存储空间的消耗很大 Kaiming He 2104 SPP-Net是对rcnn的改进,spatial Pyramid Pooling,主要贡献: (1)共用特征卷积图(对全图提取特征) (2)空间金字塔池化,有效地解决了不同尺度的图片在全连接层输出不一致的问题。
缺点不足: 1)耗时的selective search还是依旧存在 2)还是R-CNN的框架分阶段训练,不能端到端 Ross在2015年提出的Fast R-CNN进行了改进,对于Fast R-CNN贡献 1) 取代R-CNN的串行特征提取方式,直接采用一个神经网络对全图提取特征(需要RoI Pooling的原因)。
2) 因为有 RoI Pooling,所以无需对RP进行warp 3) 除了selective search,其他部分都可以合在一起训练 缺点不足: 1)耗时的selective search还是依旧存在。
Faster RCNN主要创新 用RPN网络来产生候选框取代selective search,直接通过一个Region Proposal Network (RPN)生成待检测区域,这么做,在生成RoI区域的时候,时间也就从2s缩减到了10ms。
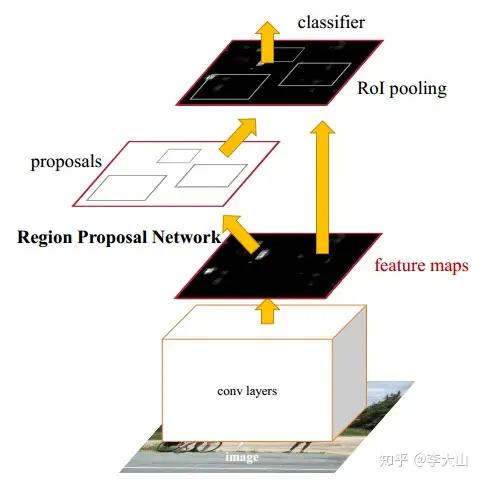

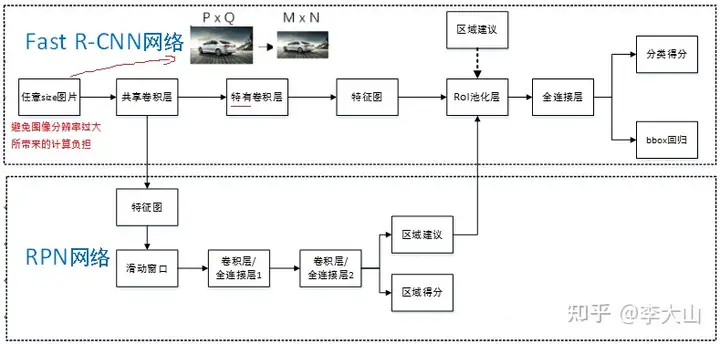
首先使用共享的卷积层为全图提取特征,然后将得到的feature maps送入RPN,RPN生成待检测框(指定RoI的位置)并对RoI的包围框进行第一次修正之后就是Fast R-CNN的架构了,RoI Pooling Layer根据RPN的输出,在feature map上面。
选取每个RoI对应的特征,并将维度置为定值最后,使用全连接层(FC Layer)对框进行分类,并且进行目标框的第二次修正尤其注意的是,Faster R-CNN真正实现了端到端的训练(end-to-end training)。
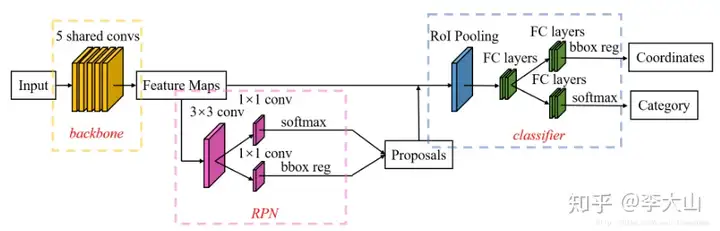
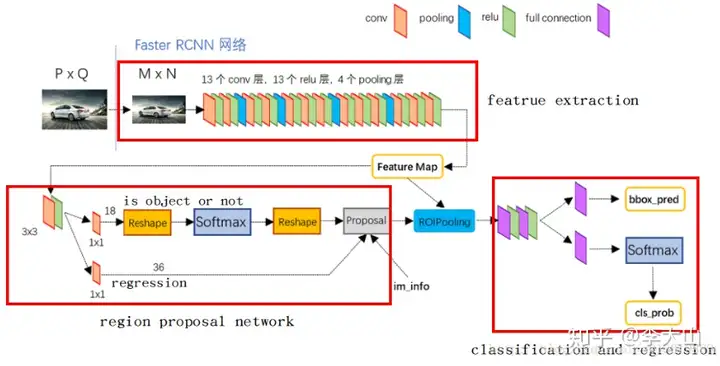
如上图所示,Faster R-CNN的结构主要分为三大部分,第一部分是共享的卷积层-backbone(Resnet网络),第二部分是候选区域生成网络-RPN,第三部分是对候选区域进行分类的网络-classifier
其中,RPN与classifier部分均对目标框有修正classifier部分是原原本本继承的Fast R-CNN结构首先我们需要知道Anchor的本质是什么?本质是SPP(spatial pyramid pooling)思想的逆向。
而SPP本身是做什么的呢,就是将不同尺寸的输入resize成为相同尺寸的输出所以SPP的逆向就是,将相同尺寸的输出,倒推得到不同尺寸的输入接下来是anchor的窗口尺寸,这个不难理解,三个面积尺寸(128^2,256^2,512^2),然后在每个面积尺寸下,取三种不同的长宽比例(1:1,1:2,2:1).这样一来,我们得到了一共9种面积尺寸各异的anchor。
至于这个anchor到底是怎么用的,这个是理解整个问题的关键。
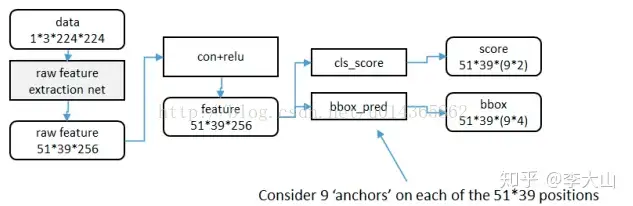
利用anchor是从第二列这个位置开始进行处理,这个时候,原始图片已经经过一系列卷积层和池化层以及relu,得到了这里的 feature map:51x39x256(256是层数) 再通过一个3x3的滑动窗口,在这个51x39的区域上进行滑动,stride=1,padding=2,这样一来,滑动得到的就是51x39个3x3的窗口。
对于每个3x3的窗口,作者就计算这个滑动窗口的中心点所对应的原始图片的中心点然后作者假定,这个3x3窗口,是从原始图片上 通过SPP池化得到的,而这个池化的区域的面积以及比例,就是一个个的anchor。
换句话说,对于每个3x3窗口,作者假定它来自9种不同原始区域的池化, 但是这些池化在原始图片中的中心点,都完全一样这个中心点,就是刚才提到的,3x3窗口中心点所对应的原始图片中的中心点 如此一来,在每个窗口位置,我们都可以根据9个不同长宽比例、不同面积的anchor,逆向推导出它所对应的原始图片中的一个区域, 这个区域的尺寸以及坐标,都是已知的。
而这个区域,就是我们想要的 proposal所以我们通过滑动窗口和anchor,成功得到了 51x39x9 个 原始图片的proposal接下来,每个proposal我们只输出6个参数:每个 proposal 和 ground truth 进行比较得到的前景概率和背景概率(2个参数) (对应图上的 cls_score);由于每个 proposal 和 ground truth 位置及尺寸上的差异,从 proposal 通过平移放缩得到 ground truth 需要的4个平移放缩参数(对应图上的 bbox_pred)。
所以根据我们刚才的计算,我们一共得到了多少个bbox呢? 51 x 39 x 9 = 17900 ----> 约等于 20 k简单地说,RPN依靠一个在共享特征图上 滑动的窗口,为每个位置生成9种预先设置好长宽比与面积的目标框(文中叫做anchor)。
示意图如下所示:
对于生成的anchor,RPN要做的事情有两个,第一个是判断anchor到底是前景还是背景,意思就是判断这个anchor到底有没有覆盖目标,第二个是为属于前景的anchor进行第一次坐标修正对于前一个问题,Faster R-CNN的做法是使用SoftmaxLoss直接训练,在训练的时候排除掉了超越图像边界的anchor;对于后一个问题,采用SmoothL1Loss进行训练。
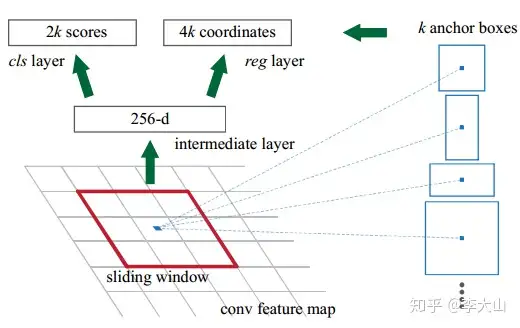
那么,RPN怎么实现呢?这个问题通过RPN的本质很好求解,RPN的本质是一个树状结构,树干是一个3×3的卷积层,树枝是两个1×1的卷积层,第一个1×1的卷积层解决了前背景的输出,第二个1×1的卷积层解决了
边框修正的输出对于RPN输出的特征图中的每一个点,一个1×1的卷积层输出了18个值,因为是每一个点对应9个anchor,每个anchor有一个前景分数和一个背景分数,所以9×2=18另一个1×1的卷积层输出了36个值,因为是每一个点对应9个anchor,每个anchor对应了4个修正坐标的值,所以9×4=36。
那么,要得到这些值,RPN网络需要训练在训练的时候,就需要对应的标签那么,如何判定一个anchor是前景还是背景呢?文中做出了如下定义:如果一个anchor与ground truth的IoU在0.7以上,那这个anchor就算前景(positive)。
类似地,如果这个anchor与ground truth的IoU在0.3以下,那么这个anchor就算背景(negative)在作者进行RPN网络训练的时候,只使用了上述两类anchor,与ground truth的IoU介于0.3和0.7的anchor。
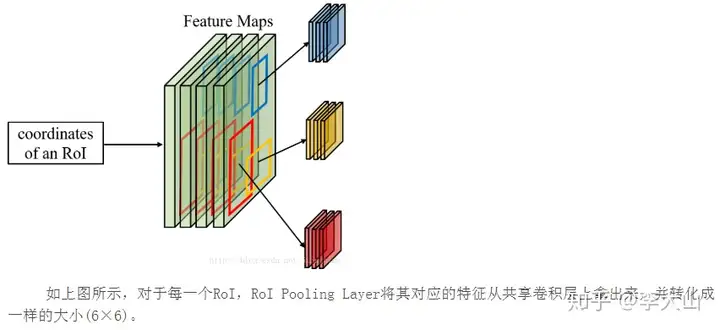
没有使用在训练anchor属于前景与背景的时候,是在一张图中,随机抽取了128个前景anchor与128个背景anchor为什么需要RoI Pooling?答案是在Fast R-CNN中,特征被共享卷积层一次性提取。
因此,对于每个RoI而言,需要从共享卷积层上摘取对应的特征,并且送入全连接层进行分类因此,RoI Pooling主要做了两件事,第一件是为每个RoI选取对应的特征,第二件事是为了满足全连接层的输入需求,。
将每个RoI对应的特征的维度转化成某个定值。RoI Pooling示意图如下所示:
在RoI Pooling Layer之后,就是Fast R-CNN的分类器和RoI边框修正训练分类器主要是分这个提取的RoI具体是什么类别(人,车,马等等),一共C+1类(包含一类背景)RoI边框修正和RPN中的anchor边框修正原理一样,同样也是SmoothL1 Loss,值得注意的是,。
RoI边框修正也是对于非背景的RoI进行修正,对于类别标签为背景的RoI,则不进行RoI边框修正的参数训练Faster R-CNN的训练流程大致为: 1) 首先通过RPN生成约20000个anchor(53×49×9)。
2) 对20000个anchor进行第一次边框修正,得到修订边框后的proposal 3) 对超过图像边界的proposal的边进行clip,使得该proposal不超过图像范围 4) 忽略掉长或者宽太小的proposal。
5) 将所有proposal按照前景分数从高到低排序,选取前12000个proposal 6) 使用阈值为0.7的NMS算法排除掉重叠的proposal 7) 针对上一步剩下的proposal,选取前2000个proposal进行分类和第二次边框修正。
对于Faster R-CNN的训练,作者采用 RPN和Fast R-CNN交替训练: 1) 使用在ImageNet上预训练的模型初始化共享卷积层并训练RPN 2) 使用上一步得到的RPN参数生成RoI proposal。
再使用ImageNet上预训练的模型初始化共享卷积层,训练Fast R-CNN部分(分类器和RoI边框修订) 3) 将训练后的共享卷积层参数固定,同时将Fast R-CNN的参数固定,训练RPN(从这一步开始,共享卷积层的参数真正被两大块网络共享) 4) 同样将共享卷积层参数固定,并将RPN的参数固定,训练Fast R-CNN部分。
pytorch fasterrcnn及maskrcnn inference demoimporttorchimporttorchvisionimportargparseimportcv2importrandom
coco_names={0:background,1:person,2:bicycle,3:car,4:motorcycle,5:airplane,6:bus,7:train,8:truck,9:boat
,10:traffic light,11:fire hydrant,13:stop sign,14:parking meter,15:bench,16:bird,17:cat,18:dog,19:horse
,20:sheep,21:cow,22:elephant,23:bear,24:zebra,25:giraffe,27:backpack,28:umbrella,31:handbag,32:tie,33
:suitcase,34:frisbee,35:skis,36:snowboard,37:sports ball,38:kite,39:baseball bat,40:baseball glove,41
:skateboard,42:surfboard,43:tennis racket,44:bottle,46:wine glass,47:cup,48:fork,49:knife,50:spoon,51
:bowl,52:banana,53:apple,54:sandwich,55:orange,56:broccoli,57:carrot,58:hot dog,59:pizza,60:donut,61:
cake,62:chair,63:couch,64:potted plant,65:bed,67:dining table,70:toilet,72:tv,73:laptop,74:mouse,75:remote
,76:keyboard,77:cell phone,78:microwave,79:oven,80:toaster,81:sink,82:refrigerator,84:book,85:clock,86
:vase,87:scissors,88:teddybear,89:hair drier,90:toothbrush}defget_args():parser=argparse.ArgumentParser
(description=Pytorch Faster-rcnn Detection)#parser.add_argument(image_path, type=str, help=image path)
parser.add_argument(--image_path,default=data/pdog.jpg,help=image path)parser.add_argument(--model,default
=fasterrcnn_resnet50_fpn,help=model)#parser.add_argument(--model, default=maskrcnn_resnet50_fpn, help=model) #选择maskrcnn model
parser.add_argument(--dataset,default=coco,help=model)parser.add_argument(--score,type=float,default=
0.8,help=objectness score threshold)args=parser.parse_args()returnargsdefrandom_color():b=random.randint
(0,255)g=random.randint(0,255)r=random.randint(0,255)return(b,g,r)defmain():args=get_args()print("args ---> "
,args)input=[]num_classes=91names=coco_names# Model creatingprint("Creating model")# 先提前下载好对应的权重fasterrcnn_resnet50_fpn_coco-258fb6c6.pth
model=torchvision.models.detection.__dict__[args.model](num_classes=num_classes,pretrained=True)#model = model.cuda() # for CPU
model.eval()# for inferencesrc_img=cv2.imread(args.image_path)img=cv2.cvtColor(src_img,cv2.COLOR_BGR2RGB
)#img_tensor = torch.from_numpy(img / 255.).permute(2, 0, 1).float().cuda() # for GPUimg_tensor=torch
.from_numpy(img/255.).permute(2,0,1).float()input.append(img_tensor)out=model(input)boxes=out[0][boxes
]labels=out[0][labels]scores=out[0][scores]#把label为 person的筛选出来, 即只选择label=1filter_index=torch.where(
labels==1)[0]# 获取label为person的indexlabels=torch.index_select(labels,0,filter_index)boxes=torch.index_select
(boxes,0,filter_index)scores=torch.index_select(scores,0,filter_index)foridxinrange(boxes.shape[0]):if
scores[idx]>=args.score:x1,y1,x2,y2=boxes[idx][0],boxes[idx][1],boxes[idx][2],boxes[idx][3]name=names
.get(str(labels[idx].item()))cv2.rectangle(src_img,(x1,y1),(x2,y2),random_color(),thickness=2)cv2.putText
(src_img,text=name,org=(x1,y1+10),fontFace=cv2.FONT_HERSHEY_SIMPLEX,fontScale=0.5,thickness=1,lineType
=cv2.LINE_AA,color=(0,0,255))cv2.imshow(result,src_img)cv2.waitKey()cv2.destroyAllWindows()if__name__
=="__main__":main()

以上就是关于《Faster_RCNN理解_faster rcnn算法》的全部内容,本文网址:https://www.7ca.cn/baike/9428.shtml,如对您有帮助可以分享给好友,谢谢。